

- Elastic Documentation
- Что нам дает Elasticsearch?
- Краткий словарик начинающего гуманитария
- Анализаторы
- Нечеткий поиск
- CJK
- Безопасность
- Эпилог
- Вода и предыстория
- Elasticsearch термины и структура
- Основные термины
- Структура и хранение
- Mapping
- Запросы
- Простые запросы
- Ответы
- Где взять индексы и поля?
- Сложные запросы
- Типы запросов и их применение или, что пишем внутри query?
- Match
- Multi_match Поиск по нескольким полям. Сам по себе Match указывает на необходимость поиска среди конкретного поля, но что, если нам необходимо искать среди нескольких полей? Match так не умеет, а вот multi_match запросто! Для этого в свойстве fields нужно перечислить список полей, где мы хотим выполнять поиск.
- Match_phrase
- Term
- Terms
- Query_string
- Range
- Bool
Elastic Documentation
Основных поисковых брендов на данный момент существует несколько: это Solr, Sphinx, Elasticsearch. Но сегодня мы поговорим только о последнем. Elasticsearch — это на самом деле не вполне самостоятельный поиск. Это, скорее, красивая обертка над библиотекой Apache Lucene (на нем же строится Solr). Но не стоит воспринимать слово «обертка» в негативном ключе. Lucene сам по себе вообще мало на что годен. Это все-таки не полноценный сервис, а просто библиотека для построения поисковых систем. Все, что она может, — только индексировать и искать. А API для ввода данных, для поисковых запросов, кластеризация и прочее — это все отдается на откуп «обертке».
Что нам дает Elasticsearch?
Масштабируемость и отказоустойчивость. Elasticsearch легко масштабируется. К уже имеющейся системе можно на ходу добавлять новые серверы, и поисковый движок сможет сам распределить на них нагрузку. При этом данные будут распределены таким образом, что при отказе какой-то из нод они не будут утеряны и сама поисковая система продолжит работу без сбоев.
На самом деле оно даже работает. В хипстерском стиле «чувак, вот тебе три команды — пользуйся ими и, пожалуйста, не задумывайся, какой ад происходит внутри». И часто это прокатывает. Новые ноды подключаются буквально парой строчек в конфиге, почти как у Redis. Главное, мастеры со слейвами не путать, а то он возьмет и молча потрет все данные :). При выпадении каких-либо серверов из кластера, если правильно были распределены реплики данных, корректно настроенное приложение продолжит поиск, как будто ничего не произошло. После того как сервер поднимется, он сам вернется в кластер и подтянет последние изменения в данных.
Мультиарендность (англ. multitenancy) — возможность организовать несколько различных поисковых систем в рамках одного объекта Elasticsearch. Причем организовать их можно абсолютно динамически. Очень интересная особенность, которая в отдельных случаях становится определяющей при выборе поисковой системы. На первый взгляд может показаться, что необходимости в этой особенности нет. Классические системы поиска типа Sphinx обычно индексируют какую-то одну базу с определенным кругом данных. Это форумы, интернет-магазины, чаты, различные каталоги. Все те места, где поиск для всех посетителей должен быть идентичным. Но на самом деле довольно часто возникают ситуации, когда систем поиска должно быть больше одной. Это либо мультиязычные системы, либо системы, где есть определенное количество пользователей, которым нужно предоставлять возможность поиска по их персональным данным.
В первом случае нам нужно строить отдельные индексы по разным языкам, отдельно настраивать морфологию, стемминг, параметры нечеткого поиска для того, чтобы получить максимально качественные результаты для каждого из языков. Во втором случае в качестве гипотетического примера можно взять какой-нибудь корпоративный аналог Dropbox’а. Приходит клиент, регистрируется, заливает свои документы. Система их анализирует, угадывает язык, парсит, заливает в отдельный индекс поисковой системы, настраивает параметры под нужный язык. И далее клиент может пользоваться поиском по своим документам. Поиск будет работать достаточно быстро, потому что данных в индексе отдельного клиента всегда будет меньше, чем в одном большом общем, будет возможность динамически такие индексы создавать, устанавливать различные поисковые параметры. Ну и данные клиентов будут изолированы друг от друга.
Операционная стабильность — на каждое изменение данных в хранилище ведется логирование сразу на нескольких ячейках кластера для повышения отказоустойчивости и сохранности данных в случае разного рода сбоев.
Отсутствие схемы (schema-free) — Elasticsearch позволяет загружать в него обычный JSON-объект, а далее он уже сам все проиндексирует, добавит в базу поиска. Позволяет не заморачиваться слишком сильно над структурой данных при быстром прототипировании.
RESTful api — Elasticsearch практически полностью управляется по HTTP с помощью запросов в формате JSON.
Краткий словарик начинающего гуманитария
Установить Elasticsearch проще простого. Есть готовые репозитории и для RHEL/Centos, и для Debian. Можно отдельно установить из тарбола.
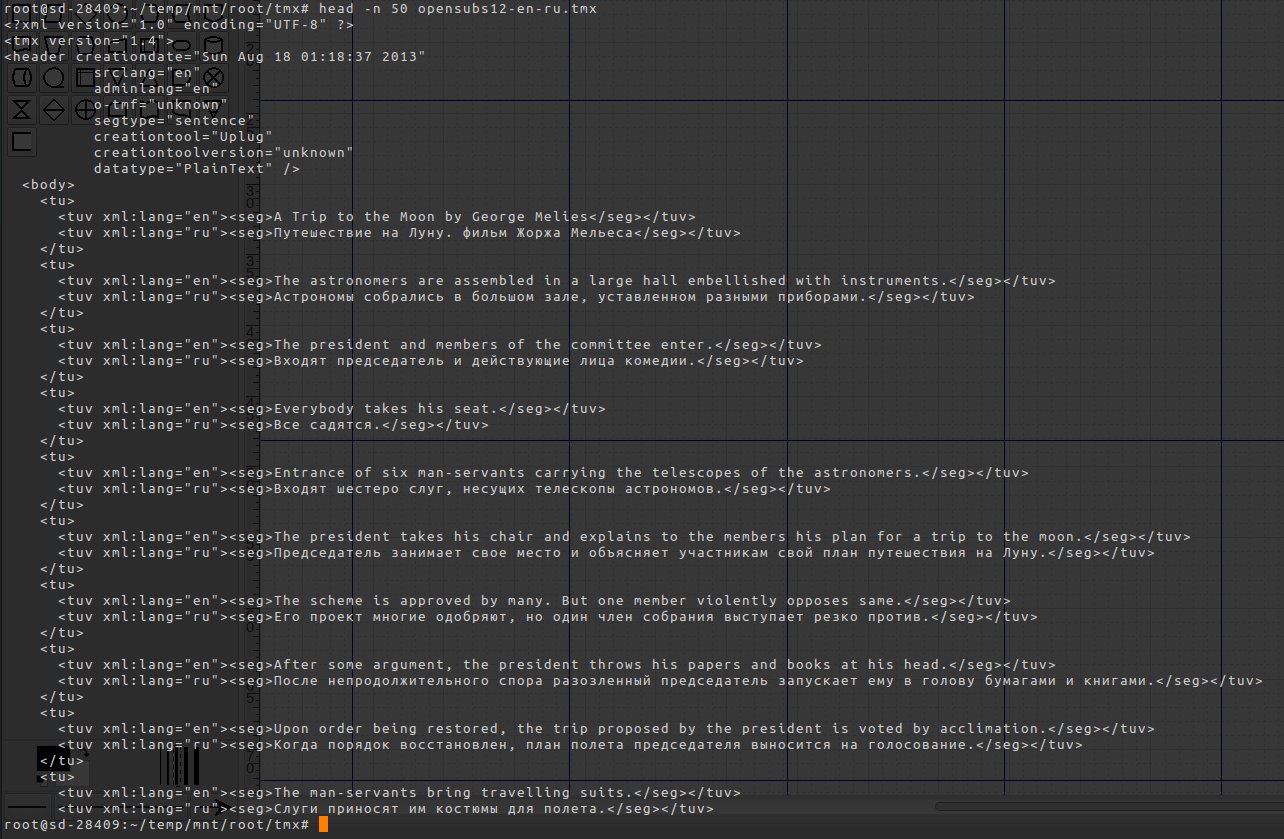
И вся дальнейшая работа с ним происходит посредством HTTP-запросов в JSON-формате. Давай, к примеру, создадим новый индекс и забьем в него какие-нибудь тестовые данные. Я взял отсюда англо-русский параллельный корпус, собранный из данных OpenSubtitles.org. Формат TMX достаточно простой, описывать его отдельно не стану. Напишу небольшой парсер на Python, который бы разбирал файл и заливал данные в новый индекс:
На VPS’ке с четырьмя гигами памяти во флопсе заливка четырех с половиной миллионов документов (чуть больше 900 Мб данных в текстовом формате) занимает примерно полтора часа. В целом очень даже неплохо. Теперь накидаем небольшой скриптик для удобного поиска:
И проверяем, что у нас получилось:
Первая колонка — вес полученного значения, остальные две — найденные результаты. А теперь ищем по-русски:
Как видишь, неплохо ищет уже прямо из коробки, для какого-нибудь блога или небольшого форума вполне подойдет. А если качество выдачи покажется недостаточно высоким (а к такой мысли рано или поздно приходят почти все), то Elasticsearch предоставляет большое количество возможностей для дальнейшего тюнинга анализаторов и поисковых алгоритмов.
Анализаторы
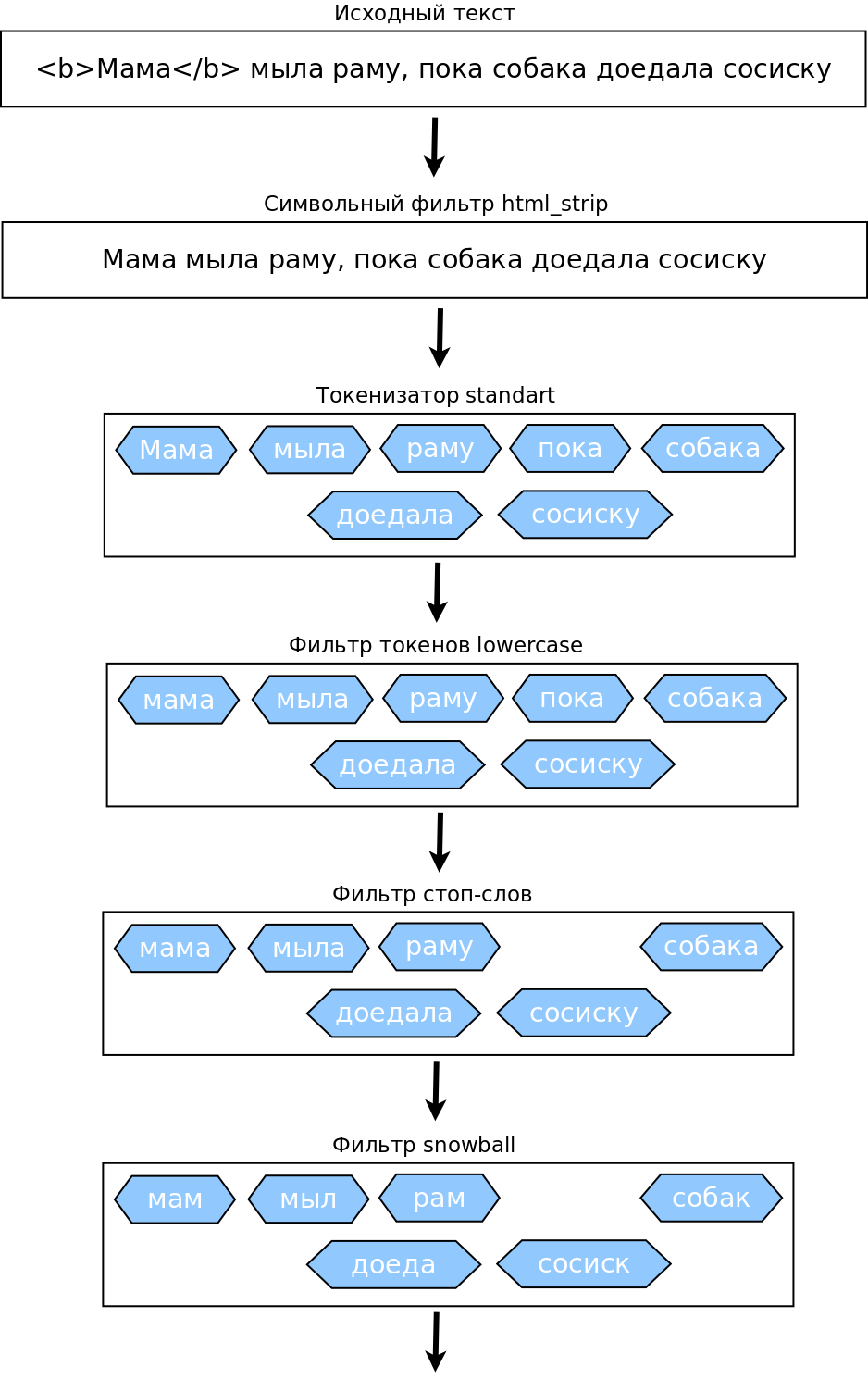
Выбор правильного анализатора для обработки своих данных — это что-то почти на грани искусства. Изнутри каждый анализатор представляет собой своеобразный конвейер, состоящий из нескольких обработчиков:
Главная цель любого анализатора — из длинного предложения, перегруженного ненужными деталями, выжать основную суть и получить список токенов, которые бы ее отражали.

Примерную схему работы конвейера можно увидеть на картинке поблизости. Анализ начинается с опциональных символьных фильтров. Это, к примеру, перевод текста в нижний регистр или подстановка слов. Полученный результат передается токенизатору, главному и единственному обязательному элементу анализатора. Здесь предложение очищается от знаков препинания, разбивается на отдельные слова-токены, которые могут либо сохранять имеющуюся форму, либо обрезаться только до основы слова, либо обрабатываться еще каким-либо образом в зависимости от токенизатора. После токенизатора полученные данные отправляются на дальнейшую фильтрацию, если уже проделанных манипуляций будет недостаточно.
Elasticsearch из коробки предоставляет сразу несколько различных анализаторов. Если их будет мало, то нестандартные анализаторы можно будет добавить с помощью специального API. Вот базовый пример нестандартного анализатора:
Что делает этот анализатор:
Детальнее о предоставляемых вместе с Elasticsearch анализаторах и фильтрах можно прочитать в официальной документации. Здесь описывать не возьмусь, так как деталей там очень много.
Нечеткий поиск
Основой нечеткого поиска является расстояние Дамерау — Левенштейна — количество операций вставки/удаления/замены/транспозиции для того, чтобы одна строка совпала с другой. Например, для превращения «пгода вИ кутске» в «погода в Иркутске» такое расстояние было бы равно трем — две вставки и одна замена.
Расстояние Дамерау — Левенштейна — это модификация классической формулы Левенштейна, в которой изначально отсутствовала операция транспозиции (перестановки двух соседних символов). Elasticsearch поддерживает возможность использования в нечетком поиске обоих вариантов, по умолчанию включено использование расстояния Дамерау — Левенштейна.
При работе с нечетким поиском также не стоит забывать и о том, как Elasticsearch (да и любой другой поисковый движок в принципе) работает изнутри. Все данные, загружаемые в индекс, сперва проходят обработку анализатором, лемматизацию, стемминг. В индекс уже складываются только «обрывки» исходных данных, содержащие максимум смысла при минимуме знакового объема. И уже по этим самым обрывкам впоследствии проводится поиск, что при использовании нечеткого поиска может давать довольно курьезные результаты.
Например, при использовании анализатора snowball во время нечеткого поиска по слову running оно после прохода через стемминг превратится в run, но при этом по нему не найдется слово runninga, так как для совпадения с ним нужно больше двух правок. Поэтому для повышения качества работы нечеткого поиска лучше использовать самый простой стеммер и отказаться от поиска по синонимам.
Elasticsearch поддерживает несколько различных способов нечеткого поиска:
CJK
CJK — это три буквы боли западных систем полнотекстового поиска и людей, которые хотят ими воспользоваться. C JK — это сокращение для Chinese, Japanese, Korean. Три основных восточных языка, составляющих совокупно почти 10% современного интернета. Они отличаются от привычных западных языков практически всем — и письменностью, и морфологией, и синтаксисом. Все это, понятно, вызывает некоторые проблемы при разработке различных систем обработки естественных языков, в том числе и поисковых систем.
У Elasticsearch в этой области дела тоже обстоят неплохо. Есть встроенный анализатор CJK со стеммингом, есть возможность использовать нечеткий поиск. Вот только если по текстам на корейском и японском языках еще хоть как-то можно искать «по классическим правилам» (то есть делим на слова, отбрасываем союзы/предлоги, оставшиеся слова токенизируем и загоняем в индекс), то вот с китайским, в котором слова в предложении не принято разделять пробелами, все куда сложнее.
Для поисковой системы все предложение на китайском остается одной целой единицей, по которым проводится поиск. Например, предложение «Мэри и я гуляем по Пекину» выглядит вот так:
Девять символов без пробелов, 18 байт в UTF-8. В нормальной вселенной это прокатило бы за одно слово, но не тут. Если стратегически расставить пробелы в нужных местах, то предложение станет выглядеть вот так:
玛丽 和 我 走 北京 周边.
Шесть слов. С этим уже можно было бы работать. Вот только пробелы в китайском никто не использует. Можно пытаться разделять предложения на слова в автоматическом режиме (уже даже существует пара готовых решений), но и тут тебя будут ожидать неприятности. Некоторые слоги, стоящие в предложении рядом, могут, в зависимости от того, как их разделить пробелами, складываться в разные слова и резко менять смысл предложения. Возьмем для примера предложение 我想到纽约:
我 想 到 纽约 — Я хочу поехать в Нью-Йорк.
我 想到 纽约 — Я вспомнил про Нью-Йорк.
Как видишь, на автоматизированное членение лучше не полагаться. Как тогда быть? Тут нам поможет поиск по N-граммам. Предложение делится на куски по два-три знака:
玛丽和我走北京周边 = 玛丽 – 丽和 – 和我 – 我走 – 走北 – 北京 – 京周 – 周边
И уже по ним далее идет поиск. К этому можно добавить нечеткий поиск с расстоянием в одну-две замены, и уже получится более-менее сносный поиск.
Безопасность
У Elasticsearch нет никакой встроенной системы авторизации и ограничения прав доступа. После установки он по умолчанию вешается на порт 9200 на все доступные интерфейсы, что делает возможным не только полностью увести у тебя все, что находится в поисковой базе, но и, чисто теоретически, через обнаруженную дыру залезть в систему и там начудить. До версии 1.2 такая возможность была доступна прямо из коробки (см. C VE-2014-3120) и напрягаться не было вообще никакой нужды. В 1.2 по умолчанию выполнение скриптов в поисковых запросах отключено, но пока что и это не спасает.
Совсем недавно мы наблюдали ботнет на эластиках версий в том числе и 1.4 и выше. Судя по всему, использовалась уязвимость CVE-2015-1427. В версии 1.4.3 ее вроде как закрыли, но, сам понимаешь, полагаться на удачу в таких делах не вариант (на самом деле да, пока писалась эта статья, свежепоставленный эластик версии 1.5.0 на тестовых виртуалках у меня успели поломать уже на второй день :)). Вешай сервис только на локальные IP, все необходимые подключения извне ограничивай только доверенными адресами, фильтруй поисковые запросы, своевременно обновляйся. Спасение утопающих — дело рук самих утопающих.
К теме сохранности данных также стоит упомянуть про бэкапы. Возможности резервного копирования и восстановления встроены в сам Elasticsearch, причем довольно интересно. Перед началом создания резервных копий нужно эластику сообщить, куда они будут складываться. В местных терминах это называется «создать репозиторий»:
После того как создан репозиторий, можно начать бэкапиться:
$ curl -XPUT «localhost:9200/_snapshot/my_backup/snapshot_1?wait_for_completion=true»
Такой запрос создает бэкап с названием snapshot_1 в репозитории my_backup.
Восстановить данные можно следующим образом:
$ curl -XPOST «localhost:9200/_snapshot/my_backup/snapshot_1/_restore»
Причем снимки состояния делаются инкрементальные. То есть в первый раз создается полный бэкап, а далее при последующих бэкапах фиксируется только разница состояния между текущим моментом и моментом предыдущего бэкапа. Если у тебя кластер с несколькими мастерами, то хранилище репозитория должно шариться между всеми мастерами (то есть, при хранении на файловой системе, это должен быть какого-либо рода сетевой диск, доступный всем мастерам). Файлы репозитория я бы тоже с диска куда-нибудь бэкапил на всякий случай :).
Эпилог
На этом, наверное, стоит пока остановиться. К сожалению, за бортом статьи остались животрепещущие детали того, как на самом деле работает кластеризация и действительно ли Elasticsearch такой неубиваемый, как его хвалят. Не было сказано совсем ничего про систему плагинов и различные веб-панели для удобного администрирования поискового кластера. Но и без этого Elasticsearch уже выглядит достаточно интересным, чтобы продолжить с ним знакомство самостоятельно и, возможно, найти для себя идеальный поиск.
Данная статья будет полезна тем, кто задумался о программном использовании полнотекстового поиска напрямую, например для сложных кастомных запросов по нестандартным полям. Ну или для тех, кто захотел попробовать написать свой вариант полнотекстового поиска.
При прочтении данной статьи рекомендую заранее вооружиться доступным и работающим Elasticsearch и пользоваться им во время прочтения.
Вода и предыстория
Однажды заказчик рассказал, что они внутри компании очень любят и активно используют полнотекстовый поиск и хотели бы видеть нечто подобное в модуле нормативных документов. В таком случае поиск этот должен искать заданную пользователем фразу в тексте или карточке документа в разрезе определённых типов и видов документов. И мы задались вопросом: «А можно так???».
Механизмы объектной модели D5 не позволяли в полной мере реализовать преимущества полнотекста. Например, мы с вами можем указать в критериях поиска ISearchCriterion реквизит «Наименование» или «Примечание» или любой другой строковый реквизит со строковым типом. И поиск в таком случае будет осуществляться без использования словоформ. В критериях поиска фабрики поисков для полнотекстового поиска доступны только поля с типом текст.
Тогда я решил посмотреть в сторону Elasticsearch и его прямой эксплуатации на благо решения нашей задачки.
Elasticsearch термины и структура
С версии Directum 5.6 для полнотекстового поиска стал использоваться движок Elasticsearch (далее – ES)– популярная (в том числе в области Big Data) поисковая система с открытым исходным кодом, любимая и почитаемая многими за свою скорость и гибкость. E S поддерживает сложные агрегации, геофильтры и т.д. На данный момент она же используется и в Directum RX, что не удивительно, на самом деле.
Немного о терминах и структуре, дабы понимать, о чём будет речь далее. Это очень важно, т.к. термины в целом знакомые, но в смежных областях означают немного другое.
Основные термины
Проще всего основные термины объяснить проводя аналогии с базами данных. Ниже приведена таблица с аналогичными терминами из, наверняка, знакомого вам SQL.
* Начиная c 6-й версии ES у индекса может быть только один тип.
Структура и хранение
В Elasticsearch данные хранятся в виде документов JSON, причём поддерживается хранение вложенных объектов. Пример структуры документа:
Кстати, элементы «id», «name» и т.д. это и есть ни что иное, как название полей документов.
Mapping
Так же вам будет встречаться такой термин, как Mapping, по-другому его ещё можно назвать схемой. По сути mapping определяет в каком виде будет хранится документ(структура и типы полей), и каким образом он индексируется. Здесь же можно указать анализаторы и дефолтные значения и т.д.
Полезно будет понимание того, что все свойства, и ключи, начинающиеся со знака «_» являются системными. Например поле _id, которое есть у каждого документа или поле _type – ни что иное, как его тип, или url-ключ _search, который задаёт API поиска(реализует поиск).
Основной способ взаимодействия с Elasticsearch — REST API. По умолчанию API —интерфейс Elasticsearch работает на порту 9200. Api Elasticsearch можно классифицировать на следующие виды:
Нас же будет интересовать API поиска и API Индексов.
Запросы
Начнём с простого. Так как это REST API нам понадобится браузер с любым расширением для работы с http запросами, либо Postman.
В postman для тела используем следующие настройки:

Во-первых, проверим, строку подключения. В Directum 5 её можно найти в константе ESServerURL (В моём случае это http://localhost:9200).
Проверка доступа осуществляется с помощью простого http запроса по тому же адресу. Если коннект налажен, то мы должны получить примерно следующее:
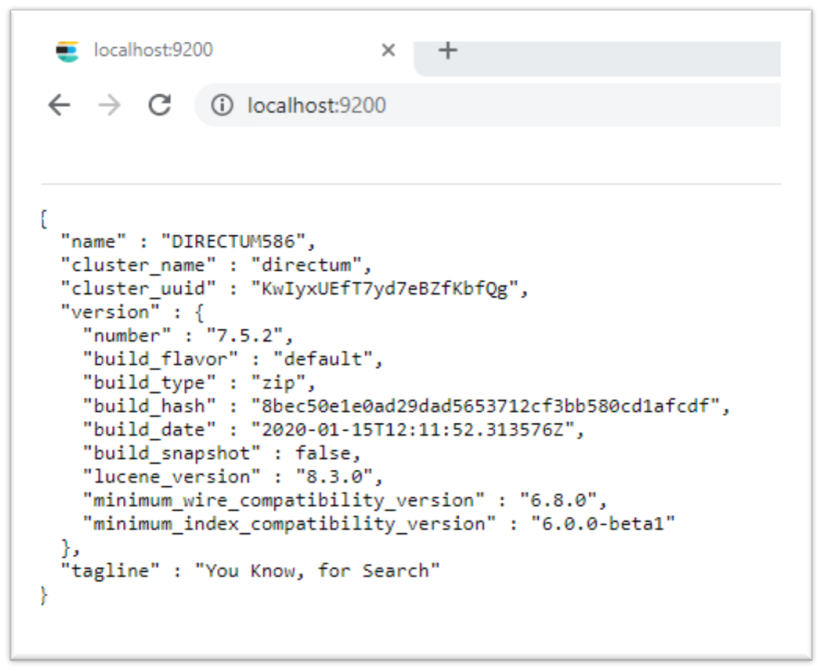
О доступе стоит поговорить отдельно, ведь для D5 это порождает некоторые проблемы.
Согласно справке для ES настраивается безопасный доступ, что означает, что у простых пользователей прямого доступа к API не будет. И это правильно, ведь движок не в курсе прав доступа на те или иные документы и без разбора может выдать тексты документов тем пользователям, у которых на это нет прав, но это касается лишь «Продвинутой» части пользователей, способной писать и слать запросы.
Так. Что вариантов решения этой проблемы мне на ум приходит всего 2:
В RX же проблема должна решаться серверными функциями.
Возможно, кто-то сможет придумать, как договориться со службой поиска, чтобы через неё отправлять свои запросы.
Когда необходимо выполнить поиск, используется HTTP-запрос к _search Api. Индекс и тип, по которому должен выполняться запрос, указывается в URL-адресе. Индекс и тип являются необязательными. Если индекс и тип не указаны, Elasticsearch выполняет запрос по всем индексам в кластере. Поисковый запрос в ES может быть выполнен двумя разными способами:
Простые запросы
Самый простой запрос, возвращающий результаты поиска по слову «Фёдор», будет выглядеть так:
Данный запрос будет искать по всем полям всех индексов и всех типов документов, короче везде.
Запрос более точечный, для поиска среди конкретных индексов и типов будет выглядеть следующим образом:
Этот запрос уже ищет не по всем индексам, но всё ещё продолжает искать по всем полям документов. Рассмотрим запрос, где нам необходимо найти совпадения по определённым полям карточки, или только в тексте документа:
Здесь уже совпадения будут искаться только среди поля content. в D5 это поле содержит текст тела документа.
Ответы
Мы поговорили о запросах, а что же с ответами? Если после выполнения запроса вам пришёл ответ со статусом 200, то запрос вы составили корректно. Вне зависимости от того, нашлось ли что-то по вашему запросу, или нет вы получите ответ в виде json’а.
Ниже приведён слегка упрощённый (урезанный в плане полей) пример ответа:
Если по вашему запросу ничего не найдётся, то свойство hits будет пустым т.е.
Описание структуры ответа:
В основном в json ответа нас будет интересовать свойство hits. Именно оно и содержит всю информацию о найденных по нашему запросу документах в виде массива объектов.
Где взять индексы и поля?
Это вполне логичный вопрос, раз мы вплотную подошли к сложным запросам, ведь нам точно нужно знать и понимать какие поля указывать и что там вообще хранится.
Для получения индексов очень удобно использовать следующий запрос:
В ES для D5 я получил следующий результат:
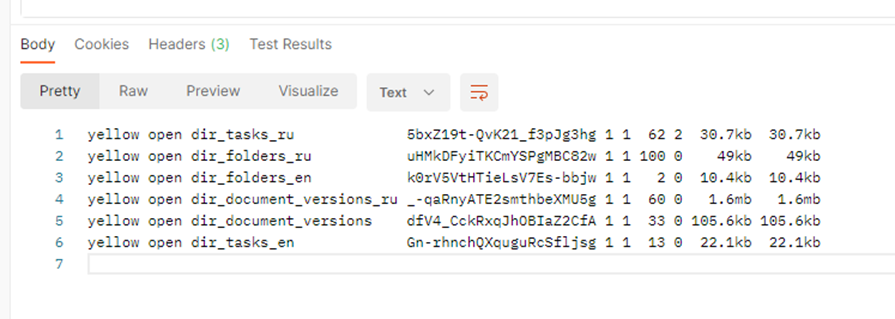
В этом случае параметр _cat позволил получить результаты в виде красивенькой таблички.
К сожалению, это пока что для меня это единственный запрос, работающий с параметром _cat.
Собственно наименования индексов находятся в третьей колонке, а четвёртой их uuid.
На всякий случай, выделю полученные имена индексов:
Отличий между индексами dir_document_versions и dir_document_versions_ru я так и не нашёл. Тем не менее в моей системе есть документы как с одним, так и с другим индексом не зависимо от того, на каком языке содержимое документа. Возможно, индексы *_ru используются там, где тело документа хранится в кодировке windows-1251. Этот вопрос потребует более детальной проработки. Названия индексов вполне себе интуитивно понятны, поэтому расшифровывать их не вижу смысла.
Такс, индексы мы получили, теперь неплохо было бы узнать поля, не так ли? В этом нам, как раз поможет mapping.
Следующий запрос вернёт схемы всех индексов
И даже здесь весь результат выкладывать не буду, приложу урезанную схему:
Интересующие нас поля содержатся в свойстве properties.
Например archive_tag, author_value_id, content и есть наши искомые поля индекса dir_document_versions_ru.
Типы полей указаны в свойстве type для каждого поля из блока Properties.
Описание всех типов, поддерживаемых ES есть в этой статье.
Важно понимать, что для полнотекстового поиска используются поля с типом text. Данные в полях с типом keyword, будут искаться по точному совпадению.
Обратите внимание, что поле card составное, поэтому его использование как поле для поиска напрямую не даст результатов. Но есть возможность искать по его дочерним полям, указывая их через точку. Например:
card.name в D5 соответствует наименованию документа.
Но проще всего оценить структуру и содержимое документа выполнив прямой запрос на конкретный документ. Получим документ с ид 163098.
В ответе можно будет увидеть примерно следующее:
В результате этого запроса мы можем найти системное свойство _source, которое как раз и содержит перечень полей документа и их значения.
*При поиске по полям нужно учитывать регистр! Т.е. результат запроса:
будет пустым т.к. у нас есть поле id, но нет поля iD.
Ну что ж. теперь мы знаем наши индексы и наши поля и можем приступать к более сложным запросам!
Сложные запросы
Мы рассмотрели способы поиска через параметры запроса, однако такой способ подойдёт только для простых запросов. Для более сложных нам понадобится указывать необходимые нам условия в теле запроса. Здесь уже не обойтись без postman или расширений. Я буду использовать postman.
Для начала рассмотрим простой запрос, аналогичный предыдущему из простых.
Структура json тела запроса:
Типы запросов и их применение или, что пишем внутри query?
В следующих примерах я буду опускать строку запроса, т.к. везде мы будем использовать одну и ту же:
Мы уже знакомы с простеньким запросом полнотекстового поиска по полю card.name
Match
Match указывает на то, что нам нужно искать совпадения в указанном поле по указанной строке.
Multi_match
Поиск по нескольким полям. Сам по себе Match указывает на необходимость поиска среди конкретного поля, но что, если нам необходимо искать среди нескольких полей? Match так не умеет, а вот multi_match запросто! Для этого в свойстве fields нужно перечислить список полей, где мы хотим выполнять поиск.
* В таких запросах по умолчанию значение для поля _score будет выбираться по лучшему результату из указанных полей (в режиме best_fields).
Вообще, просто, что бы вы знали, есть и другие способы вычисления _score и с этим можно поиграться, но, пожалуй, оставлю это вам на самостоятельное изучение, потому что для наших задач это будет излишне.
Match_phrase
Внутри «match_all» можно ещё прописать увеличение значения для параметра _score:
Вот данный запрос, например, увеличит всем полученным документам значение _score в 3.2. раза. По умолчанию _score = 1.0(это при использовании «match_all»)
Term
Такой запрос как:
Не вернёт мне данный документ. В то время, как подобный match запрос, вполне себе справится с этой задачей:
Документ я смогу получить с помощью term только в том случае, если я буду указывать всё слово целиком и только в нижнем регистре. Т.е. «новый» или «текстовый» или «документ» – позволят получить этот документ. Так же этот документ мне не вернётся если целиком указать всё наименование, т.к. оно состоит из нескольких слов.
Terms
Чтобы запросить более одного термина, мы должны использовать запрос терминов «terms». Если документ соответствует любому из условий, он попадает в результат.
Выше приведён пример запроса документа с id равным 103485, или 163099.
Query_string
Расшифрую запрос: для поиска будут использоваться поля card.name и content. Искать будем по значению Документ. Вот эти символы в конце полей: ^3 и ^2 означают boost для значения _score в результате запроса. Т.е. за совпадения искомого в поле card.name очки _score будут увеличены в 3 раза, а для совпадения в поле content очки увеличатся в 2 раза.
Или вот такой запрос:
Этим запросом мы будем искать значения полей в карточке(то есть все поля, начинающиеся с «card.») соответствующим значению Фёдор, либо значению Документ.
Если не указывать fields и в query не указывать поле, по которому нужно искать, то поиск будет производиться по всем полям:
Данный запрос вернёт все документы, где в полях упоминается документ
*В интернете вы можете найти упоминание волшебного поля _all которые можно использовать для поиска по всем полям, но с версии 6.0 оно удалено.
Я очень долго не понимал, почему у меня при поиске по нему ничего не находит, пока умные люди не подсказали. По крайней мере в D5 его точно нет – просто знайте.
Будут возвращать вам пустой результат.
Range
Range, подобно between, рассчитан на диапазон. Удобен при работе с датами. Ниже приведена таблица с разъяснением полей этого типа запроса привычными нам символами сравнения.
Т.е. запросом из примера мы отбирали все документы id которых находилось в диапазоне от 1000 и до 5000000
Bool
Используется для объединения запросов. Т.е. мы можем использовать два match вместо multi_match. Именно эта штука позволяет комбинировать все описанные ранее запросы! Покажу на примере:
should – указывает на то, что в результате нас устроит совпадение с одним из полей. Когда нужно, что бы в результат попадали только те документы, у которых имеются совпадения по всем условиям внутри bool, то мы должны указать must. А если есть необходимость исключить документы с определенными условиями то указываем must_not.
Если проще, то:
Bool может иметь под запросы bool. Базовая структура запроса bool выглядит следующим образом:
По умолчанию Bool для расчета итогового балла _score добавляются оценки всех запросов.
