

Сколько стоят ИТ-сервисы и как они используются приложениями? Каков уровень готовности и производительности сервисов в различных ЦОД? Как можно эффективно снизить общую стоимость владения, повысив качество обслуживания? От ответов на подобные вопросы зависит уровень организации мониторинга ИТ-сред и производительность инфраструктуры.
Благодаря виртуализации и облакам получать необходимые ресурсы для новых инфраструктур и приложений сегодня как никогда просто, однако следствием этого стало усложнение ИТ-среды. Более того, сегодня системы нередко географически распределены и могут полагаться на разные операционные системы, из-за чего усложняется администрирование. В результате опять стала актуальна достаточно старая тема мониторинга ИТ-сред и приложений. На начальном этапе необходимо организовать мониторинг ИТ-инфраструктуры на уровне оборудования, сервисов и приложений (рис. 1). Рассмотрим современные инструменты мониторинга сетей, позволяющие обнаруживать неполадки, обеспечивать доступность компонентов и измерять объемы расходуемых ими ресурсов.
- Выбор инструментов
- Развертывание и сопровождение
- Восемь популярных инструментов
- Zabbix
- Hyperic
- SolarWinds
- ManageEngine OpManager
- HP Operations Manager
- WhatsUp Gold
- Перспективы
- Литература
- Задачи для системы внешнего мониторинга «UFS»
- Требования к внешнему мониторингу
- Сервисы мониторинга: особенности работы, плюсы, минусы
- Таблица характеристик систем внешнего мониторинга
- Настройка уведомлений, интеграция с мессенджером
- Кейсы с внедренным мониторингом
- Для чего можно использовать ИТ-мониторинг:
- Преимущества ИТ-мониторинга:
- Возможности системы ИТ-мониторинга
- Нам доверяют клиенты
- Zabbix, Nagios
- Prometheus, Graphite
- Custom IT-monitoring stacks
- Итоги
Выбор инструментов
При выборе инструментария мониторинга инфраструктуры нужно учесть ряд факторов, в первую очередь — оценить соответствие функционала вашим техническим и бизнес-требованиям. Затем нужно рассмотреть особенности развертывания и сопровождения, чтобы подобрать инструмент, соответствующий ресурсам и уровню компетенции вашей команды ИТ-специалистов. И наконец, оценив, насколько новый инструмент будет полезен вашей организации, нужно подсчитать общую стоимость владения.
Для выбора функциональности нужно знать потребности различных пользователей (разработчиков, эксплуатационного персонала и т. д.). К примеру, ответственный за принятие бизнес-решений может быть заинтересован в отчетах о выполнении соглашений об уровне обслуживания, которые, в свою очередь, могут оказаться ценными и для технических специалистов в качестве подспорья при выявлении проблем с производительностью и их первопричин. Оценивать придется самые разные аспекты; инструмент должен поддерживать мониторинг как серверной, так и интерфейсной части среды и быть способным распознавать широкий круг проблем — от снижения быстродействия и аварийных завершений до утечек памяти.
Пользовательские интерфейсы. Инструменты мониторинга инфраструктуры существуют уже давно, и можно положиться на проверенные пакеты, однако их пользовательские интерфейсы не всегда поспевают за современными тенденциями. Оцените, удовлетворяет ли интерфейс рассматриваемого решения вашим потребностям. В зависимости от специальности пользователя и его должностных обязанностей, возможно, будет обязательным наличие веб-интерфейса либо мобильного приложения для универсальной доступности.
Уведомления, интеграция со службой поддержки и автоматизация. Назначение системы мониторинга состоит в том, чтобы помочь как можно быстрее реагировать на проблемы, например на ухудшение качества обслуживания. В этом случае, возможно, приоритетной будет настраиваемая система выдачи предупреждений. При выборе инструментария следует обратить внимание на следующие факторы: поддержку различных способов уведомления (по SMS, электронной почте, с помощью произвольных скриптов и т. п.); объем конфигурирования, который понадобится конкретно для вашей среды; поддерживаемые операционные системы и возможность интеграции с вашей системой поддержки пользователей (в частности, надо оценить простоту встраивания системы в имеющиеся процессы разрешения проблем).
По мере сбора сведений об инфраструктуре можно автоматизировать запуск различных задач при наступлении разных событий, что даст больше контроля над неполадками.
Развертывание и сопровождение
Прежде всего способ развертывания инструментария должен согласовываться с корпоративными политиками. Кроме того, выбранный инструмент должен поддерживать используемые у вас языки программирования, быть совместимым с инфраструктурой и отвечать уровню компетенции ИТ-специалистов. Нужно также провести оценку методов сбора показателей с точки зрения возможности извлечения ценных сведений. Стоит учесть, что выбор способа мониторинга производительности зависит от того, что является источником диагностической информации. К примеру, она может извлекаться из кода, из журналов операций, а также поступать от клиентских систем и сетевого оборудования.
И наконец, надо оценить стоимость инсталляции и сопровождения — любые инструменты мониторинга придется адаптировать к конкретной среде, а потому роль процессов их установки и конфигурирования в проектах внедрения трудно переоценить. Нужно обратить внимание на простоту развертывания, на возможность автоматического распознавания топологии приложений и соотнести это с имеющимися навыками и ресурсами.
При установке инструментария нужно ориентироваться на его быструю окупаемость. Для оценки общей стоимости владения понадобится, например, произвести сравнение облачной версии с локальной альтернативой, для которой затраты на лицензирование и оборудование могут быстро вырасти.
Восемь популярных инструментов
Nagios — один из самых известных инструментов с открытым кодом для мониторинга ИТ-инфраструктур, в том числе рабочих станций конечного пользователя, ИТ-сервисов и активных сетевых компонентов. Помимо бесплатной версии с открытым кодом Nagios Core, имеется коммерческая Nagios XI с дополнительными возможностями, обладающая более современным и простым в навигации веб-интерфейсом, предлагающим интерактивную информационную панель с обзором хостов, сервисов и сетевых устройств. Возможность построения графиков тенденций и наличие наглядных инструментов планирования мощности помогают в подготовке модернизаций инфраструктуры.
Инсталляция проста, но работа с конфигурационными файлами для управления устройствами и тестами потребует обстоятельного изучения документации.
Вокруг Nagios сформировалось обширное и активное сообщество поддержки, участники которого разрабатывают новые плагины, устраняющие недоработки основного инструмента, такие как трудности конфигурирования и отсутствие возможности автоматического распознавания устройств. Есть плагин для поддержки виртуальных сред.
Zabbix
Zabbix — система с открытым кодом, характеризующаяся высоким быстродействием при сборе данных и масштабируемая до корпоративного уровня. Она позволяет вести мониторинг серверов, сетевых устройств и приложений со сбором детальной статистики, касающейся производительности. Zabbix отличается простотой инсталляции, но конфигурирование может вызывать сложности, особенно если требуется настраивать особые режимы проверки. Zabbix имеет продуманный веб-интерфейс и развитые средства создания отчетов и построения графиков. Все это входит в стандартный пакет, который, помимо функций мониторинга, реализует возможности выявления тенденций. Уведомления о выходе за допустимые значения параметров система отправляет по электронной почте и SMS. Как и у Nagios, у Zabbix имеется активное сообщество поддержки.
Hyperic
Hyperic — проект компании VMware, представляющий собой систему мониторинга и администрирования для виртуальных сред. Предлагаются бесплатная версия с открытым кодом Hyperic HQ и коммерческая vFabric Hyperic. Решение обеспечивает эффективное управление многими операционными системами, веб-серверами, а также серверами приложений и баз данных. Среди дополнительных возможностей vFabric Hyperic — автоматизированное устранение неполадок.
Инсталляция проста и занимает минуты. Hyperic имеет настраиваемый пользовательский интерфейс с продуманным дизайном. Предусмотрена возможность редактирования информационных панелей — например, добавления часто используемых графиков. Уведомления приходят по SMS или электронной почте, можно назначать административные операции, которые должны выполняться при получении тех или иных уведомлений. Hyperic способен автоматически распознавать программное обеспечение и сетевые ресурсы. Имеется активное сообщество поддержки.
Главный недостаток Hyperic — большие, в сравнении с другими инструментами, потребности в ресурсах, которые нужны виртуальной машине Java.
SolarWinds
SolarWinds предлагается в качестве локально размещаемого решения и SaaS-сервиса. Установка может занимать от нескольких минут до нескольких часов в зависимости от сложности конфигурационных данных и обычно не требует помощи поставщика. Система легко масштабируется и может использоваться в больших организациях. Она также обеспечивает нативную поддержку VMware. Консультации по SolarWinds можно получить в соответствующем онлайн-сообществе.
Пользовательский интерфейс интуитивно понятен, с настраиваемыми формами ввода и возможностью доступа с мобильных устройств. Подробные графики отображают сетевые сбои, уровни готовности и быстродействия. Уведомления легко настраиваются, есть возможность создавать сложные последовательности операций на основе правил. SolarWinds предоставляет заранее сконфигурированные информационные панели, которые можно менять по своему усмотрению. Система генерирует настраиваемые отчеты, в том числе автоматически по заранее заданному расписанию.
ManageEngine OpManager
OpManager инсталлируется быстро и легко, но конфигурировать его нужно вручную, что может вызвать затруднения. Впоследствии можно автоматизировать рутинные операции сопровождения и устранения неисправностей.
OpManager предлагает несколько информационных панелей, компоновку которых можно менять. Правда, навигация по пользовательскому интерфейсу довольно сложная. Инструмент генерирует много видов отчетов и позволяет настраивать выдачу уведомлений при выходе за пороговые значения с отправкой по электронной почте, SMS и через произвольные скрипты. Имеются три уровня уведомлений: «предупреждение», «неисправность» и «ошибка». Для OpManager предлагается ряд плагинов — все как самостоятельные продукты.
HP Operations Manager
HP Operations Manager — центральный компонент комплекса для системного мониторинга от HP, представляющий собой клиент-серверное решение, требующее наличия программных агентов на каждом узле. Если нужно установить несколько пакетов, начальная настройка может оказаться непростой.
HP Operations Manager имеет превосходный графический пользовательский интерфейс для мониторинга состояния приложений, систем и сети. В состав решения входят средства планирования, в том числе инструменты прогнозного анализа и моделирования ЦОД. Уведомления можно фильтровать по весу ошибки и типу узла. Имеются механизмы упреждающего мониторинга и автоматизированной выдачи уведомлений. Сведения о событиях сопровождаются рекомендациями по исправлению ситуации, есть готовые инструменты и автоматизированные операции устранения неисправностей.
Установка Tivoli проста и занимает несколько минут, но конфигурирование, обновление и тонкая настройка средств аналитики и реагирования требуют определенной квалификации.
Система имеет интуитивно понятный веб-интерфейс с конфигурируемыми рабочими пространствами, снабжена простым в использовании хранилищем данных и развитыми средствами отчетности. Имеется механизм динамического анализа пороговых значений и производительности, помогающий в предотвращении инцидентов. Есть системы упреждающего мониторинга и автоматизированного управления сбоями. Пользуясь накопленными данными, инструментарий реализует функции отчетности, анализа производительности и выявления тенденций.
IBM предоставляет поддержку по телефону и электронной почте в рабочее время, а также обширную документацию и пользовательскую базу знаний.
WhatsUp Gold
Установить WhatsUp Gold нетрудно — конфигурирование выполняется с помощью веб-консоли и Windows-приложения. Предлагается более 200 настраиваемых отчетов, в том числе по тенденциям, выявленным в процессе анализа данных за прошлые периоды. Возможно формирование отчетов в реальном времени, что помогает в устранении неисправностей. Доступны несколько плагинов, расширяющих возможности системы. Однако пользовательский интерфейс неудобен даже при доступе к простым функциям — например, при создании отчетов по индивидуальным элементам. При выходе параметров устройств за пороговые значения уведомления могут отправляться по электронной почте, SMS или через произвольные скрипты.
Перспективы
Уже скоро традиционные инструменты мониторинга инфраструктуры уступят место средствам управления производительностью приложений, от быстродействия которых все сильнее зависит рентабельность бизнеса. «Отзывчивость» приложений — ключевой параметр, влияющий на характеристики бизнес-процессов и способность удерживать клиентуру. В то же время изменчивость рынка и потребность в более быстром получении результатов побуждают компании переходить на скорые (agile) методы разработки, позволяющие ускорить выпуск ПО. При этом качество ПО надо оценивать не только по функциональности (способности проходить тесты), но и по характеристикам производительности. На смену традиционным методам управления ИТ-инфраструктурой придут подходы на основе идей DevOps, при которых инструменты управления производительностью приложений будут полезными на протяжении всего жизненного цикла разработки ПО.
Литература
- J. Kowall, W. Cappelli. Magic Quadrant for Application Performance Monitoring. Gartner, Oct. 2014. URL: http://www.gartner.com/doc/2889421/magic- quadrant- application- performance- monitoring (дата обращения: 30.11.2015).
- Vendor Landscape: Systems Management. Info-Tech Research Group, 2011. URL: http://www.infotech.com/research/ss/it- vendor- landscape- systems- management (дата обращения: 30.11.2015).
- K. Fatema et al. A Survey of Cloud Monitoring Tools: Taxonomy, Capabilities and Objectives // J. Parallel and Distributed Computing. — 2014. Vol. 74, N. 10. — P. 2918–2933.
Что такое мониторинг ИТ-инфраструктуры и как организовать его с помощью современных технологий в интервью рассказал Никита Кардашин, руководитель практики комплексной цифровизации процессов компании NAUMEN.
— Какие средства для организации мониторинга инфраструктуры, приложений, бизнес-процессов сейчас есть в арсенале ИТ?
На верхнем уровне все решения для мониторинга делятся на инфраструктурные и зонтичные. Первые применяются для сбора информации непосредственно с объектов мониторинга агентским или безагентским способом. С их помощью можно вести реестр метрик, реагировать на обнаруженные отклонения и оповещать об этом технических специалистов. В свою очередь, зонтичный мониторинг ориентирован не на прямой сбор «сырых» значений с оборудования, а на консолидацию данных, которые поступают из множества различных источников: систем инфраструктурного мониторинга, учетных и управляющих систем.
Если привести пример, то при инфраструктурном мониторинге сотен серверов придется подключиться к каждому из них отдельно и собрать нужную информацию. При зонтичном — серверная инфраструктура направляет данные в систему виртуализации или управления, из которой их и забирает решение мониторинга.
— А как эти два типа систем соотносятся между собой: дополняют или применяются по отдельности?
Такие решения тесно взаимосвязаны. В целом для управления ИТ-инфраструктурой используется целый комплекс инструментов, таких как системы мониторинга, инвентаризации, решения класса Service Desk, CMDB. Все они действуют в тесной «спайке» и закрывают определенную зону функциональности в зависимости от конкретных потребностей компании и ИТ-подразделения.
Возможны случаи, когда в небольшой организации или отдельном подразделении крупной компании используется исключительно инфраструктурный мониторинг. С его помощью контролируется ограниченный объем компонентов ИТ-ландшафта (к примеру, отдельный сервис), где нет необходимости в агрегации данных.
Иногда инфраструктурный мониторинг вовсе не нужен. Например, если компания перевела свою инфраструктуру в облачную среду. Данные собираются системой управления, откуда их можно сразу направлять в «зонтичный» слой.
— Как организовать грамотный мониторинг?
При оценке требований к мониторингу можно выделить несколько ключевых моментов. Первый — это полнота получаемой информации. Как правило, ИТ-инфраструктура состоит из множества технологических доменов: серверного и сетевого оборудования, систем виртуализации, баз данных. Особенно высокой гетерогенностью отличается инфраструктура крупных компаний.
Все эти компоненты необходимо контролировать, чтобы ИТ-специалисты организации вовремя реагировали на возникающие отклонения. Иначе всегда будет сохраняться точка нестабильности и опасность инцидентов. Конкретные способы мониторинга и применяемые цифровые системы могут различаться для каждого из технологических доменов.
Второе, что важно для грамотного мониторинга, — целостность информации. Получаемые данные должны передаваться в единый центр, где они будут агрегироваться и коррелироваться, то есть накладываться друг на друга. Только так получится сформировать 360 view, чтобы получить ответ на вопрос, а что сейчас происходит в любом из компонентов ИТ-инфраструктуры.
Зачастую компании применяют различные системы мониторинга, которые действуют обособленно. Данные из них никак не консолидируются. В итоге, чтобы понять причину сбоя в работе корпоративной почты, ИТ-специалистам потребуется изучить показания всех используемых цифровых решений. Разумеется, это неэффективно и создает риск, что проблема не будет своевременно выявлена. Не говоря уже о быстрой реакции на нее. Именно здесь поможет «зонтичный» слой.
Третий нюанс — получаемые данные бесполезны без привязки к учету и ресурсно-сервисной модели компании. Для понимания, что именно пошло не так, нужно четко представлять нормальную ситуацию, к которой следует стремиться. В этих целях и формируется ресурсная-сервисная модель, которая описывает взаимосвязи элементов ИТ-инфраструктуры. К примеру, поясняет, что для корректной отправки электронных писем должны исправно работать почтовый сервер, СУБД, каналы связи, инфраструктурные фермы, вплоть до технологического уровня: систем питания, кондиционирования ЦОД и т.д.
Четвертый ключевой момент — это объединение данных мониторинга с процессами поддержки. Например, при регистрации инцидентов от пользователей. В таком случае глубокая интеграция процессов поддержки и мониторинга позволяет получить петлю обратной связи, когда, допустим, при поломке оборудования или прерывании услуги автоматически создается задача на восстановление. После ее выполнения система мониторинга подтверждает, что проблема действительно устранена. Таким образом, процессный мир, в котором работают люди, взаимодействует и обменивается информацией с технической средой.
Наконец, пятое условие эффективной организации потоков данных — применение технологий предиктивной аналитики. Сегодня мало реагировать на инциденты. Лучше не допускать ситуаций, когда пользователи звонят в службу поддержки и сообщают, что важные сервисы не работают. Нужен проактивный подход, чтобы выявлять и устранять подобные сбои заранее. А в идеале пользователи вообще не должны замечать неполадки. В сочетании с консолидацией данных технологии предиктивной аналитики позволяют принимать упреждающие меры еще до того, как произойдет авария и нанесет ущерб бизнесу.
— Насколько соблюдение этих требований помогает улучшить ситуацию с мониторингом и в целом организацией процессов?
Оцифровать и зафиксировать такой прогресс бывает непросто. Ведь сравнивать приходится уровни низкой и высокой зрелости процессов. Прежде чем анализировать изменения к лучшему, нужно понимать изначальную ситуацию. Это требует определенной процессной зрелости уже на старте проекта по внедрению комплексного мониторинга.
Не все компании до начала автоматизации ведут надлежащий учет возникающих инцидентов. Нередко большинство вопросов решается «по старинке»: если что-то ломается, пользователь дозванивается до ИТ-специалиста. Тот устраняет проблему, и это нигде не фиксируется. При таком ведении статистики трудно говорить о количественных метриках прогресса, который, несомненно, достигается путем автоматизации и мониторинга.
В целом внедрение качественного мониторинга позволяет значительно (в разы) сократить число инцидентов и периоды простоя ИТ-услуг, повысить удовлетворенность бизнес-пользователей и клиентов, а также сократить нагрузку на и без того перегруженный ИТ-персонал.
— Каким опытом обладает в данной сфере NAUMEN? Какие технологии и решения есть у компании, какими достижениями гордится?
Наша компания работает в сфере автоматизации ИТ-подразделений фактически 20 лет. За этот продолжительный период мы накопили большой проектный опыт по построению процессов мониторинга, управления инфраструктурой и ИТ-активами.
Наша продуктовая линейка закрывает различные потребности бизнеса, начиная от инфраструктурного мониторинга и заканчивая полноценным выстраиванием процессов по модели ITIL 4. Это продукты Naumen Network Manager, Naumen Business Service Monitoring и Naumen Service Desk, которые позволяют решать полный спектр вопросов ИТ-подразделения. Важно отметить, что в этих цифровых продуктах широко применяются технологии предиктивной аналитики и роботизации.
Вместе с тем мы обладаем большим опытом с позиции как вендора, так и интегратора. NAUMEN не только разрабатывает и поставляет автоматизированные решения, но и реализует «под ключ» проекты внедрения и перестройки бизнес-процессов.
— Ваше экспертное мнение о перспективах развития направления мониторинга ИТ и подходах, которые будут актуальны в ближайшие годы.
Безусловно, продолжат активно развиваться технологии предиктивной аналитики. Не потеряет актуальности тренд на роботизацию и автоматизацию процессов. Уже сегодня можно полностью автоматизировать значительную часть процедур в рамках ИТ-процессов и делегировать принятие ряда решений системам автоматизации.
В плане выстраивания сквозных процессов сохранится текущая тенденция консолидации и переиспользования информации в единой системе. Имеется в виду автоматизация смежных процессов (финансовое, бюджетное планирование, проектное управление и т.д.), в которых сведения из систем мониторинга и поддержки ИТ-услуг также помогают выполнить множество задач. Это определение эффективности использования вычислительных ресурсов компании, выявление точек недогрузки или перегрузки, оптимизация плана закупок и многое другое.
Не исчезнет тренд на высокую значимость клиентского сервиса, в том числе в ИТ. На успех бизнеса все больше будут влиять качество и оперативность предоставляемых потребителю услуг.
— Насколько развиты эти тренды уже сегодня?
Для каждой организации рост зрелости осуществляется по своему уникальному сценарию. Если говорить про российский ИТ-рынок, то лишь небольшое число компаний сегодня имеет по-настоящему зрелые процессы управления. Многие либо вовсе не применяют средства автоматизации, либо делают это ограниченно.
Разумеется, в нашей стране есть примеры компаний, где достигнута высокая процессная зрелость. Значительная часть из них использует программное обеспечение разработки NAUMEN. В целом таких продвинутых организаций пока не так много, и в этом плане рынку есть куда расти.
Для любой ИТ-компании, владеющей несколькими веб-сервисами, важной задачей является не только обеспечение их стабильной работы, но и максимально быстрое реагирование на возникающие сложности
Для любой ИТ-компании, владеющей несколькими веб-сервисами, важной задачей является не только обеспечение их стабильной работы, но и максимально быстрое реагирование на возникающие сложности. Особую роль в данном случае играет правильно подобранная система мониторинга. Travel-компании и не только, со штатом системных администраторов и команд разработки, как правило, отдают предпочтение внутреннему мониторингу. При этом у внешнего – масса преимуществ. Эксперты «UFS», ИТ-компании в сегменте travel, которая работает с высоконагруженными сервисами, проанализировали самые популярные системы, представленные на рынке, выбрали подходящую и решили поделиться успешными кейсами.
Задачи для системы внешнего мониторинга «UFS»
В рамках активного внедрения практики DevOps часть процесса мониторинга перешла от системных администраторов к командам разработки. В первую очередь необходимо было автоматизировать проверку доступности системы компании для потребителя – пользователей, а также веб-сервисов и других систем.
Процесс взаимодействия сервисов «UFS» выглядит следующим образом. Все справочные данные от поставщиков контента передаются в веб-сервисы (шлюзы), являющиеся backend-частью системы, обрабатываются там и в установленном формате передаются на сайт для отображения. Таким образом, при возникновении ошибки в результате запроса от сайта система мониторинга должна оперативно проверить три сервиса – сайт, шлюз, поставщика данных и выявить причину.
Проверка должна направляться на большинство страниц сайта: например, на ключевые направления, маршруты, расписание поездов и др. В ходе проверки backend-части проверяется ряд важных запросов для тех же страниц. А для мониторинга жизнеспособности провайдера данных используется проверка его ответа на соответствие заданному формату – если в ответе не поступает один из обязательных тэгов, значит, проблема на его стороне. Необходимо, чтобы при сигнале о падении того или иного монитора моментально определялось место возникновения проблемы.
При этом система внешнего мониторинга не должна была тестировать сервисы, отвечающие за оплату, корректность почтовых рассылок и т. д. Установить факт работоспособности таких сервисов невозможно проверкой http-статуса ответа. В подобных ситуациях проводятся сложные проверки интеграционным автоматизированным тестированием. Например, для выявления корректной работы сервиса почтовых рассылок используется скрипт, покупающий билет и проверяющий адекватность отображения всех писем, которые должны поступить на почту при покупке.
Требования к внешнему мониторингу
Частота опрашивания страниц. Чем быстрее неисправность будет выявлена, тем быстрее она будет исправлена, но слишком часто обращаться к страницам тоже нельзя, так как чрезмерная нагрузка повлияет на доступность серверов. Выяснили, что оптимальна – частота 1 раз в 1–2 минуты для каждой страницы.
Распознавание статусов ответа. Традиционно, 200-й код ответа страницы означает «успех». В нашем случае это не всегда так. Например, для проверки работоспособности взаимодействия одного из наших сервисов с внешним поставщиком при определенном запросе мы должны получать страницу с 301-м редиректом, и только ее. Таким образом, система мониторинга должны быть гибко настроена к распознаванию кодов ответа страниц – 404-я ошибка так же может быть успешным кейсом в некоторых случаях.
Проверка протоколов HTTP/HTTPS, тогда как FTP, POP3, SMTP, IMAP в данный момент не актуальны.
Список ключевых слов в ответе от сервера. Команда пришла к выводу, что стратегия проверки исключительно кода ответа от страницы, к сожалению, проигрышная. Во многих случаях сайт передавал 200-е страницы с абсолютно некорректным содержимым, поэтому было принято решение проверять страницы еще и на присутствие ключевых слов. Или, наоборот, на их отсутствие.
Оповещения. Это наиболее важный момент любого мониторинга. Вся переписка внутри компании проходит в одном из популярных мессенджеров, поэтому основным каналом связи должен был стать именно он. Кроме того, необходимы СМС-оповещения или автоматические звонки на телефон для самых важных мониторов.
Удобная визуализация статистики. Необходимо обеспечить доступ каждой команды к просмотру данных при минимальном количестве людей, имеющих права на администрирование системы мониторинга в целом. Существует два пути решения этого вопроса – бот в мессенджере, отправляющий оповещения и статистику по запросу, и веб-страница, при открытии которой отображается статистика по проекту. Второй вариант оказался более практичным для использования.
Сервисы мониторинга: особенности работы, плюсы, минусы
Мы выбрали пять сервисов, по предварительным данным отвечающих нашим требованиям и поставленным задачам:
30 дней бесплатной полной версии, далее только подписка. На минимальном тарифе максимум 10 мониторов с интервалом 1 раз в минуту. Проверяет протоколы HTTP(s), все почтовые – SMTP, IMAP, POP3. Умеет проверять работоспособность указанных портов. Оповещения действуют во многих каналах связи – Slack, HipChat, push-уведомления в собственные мобильные приложения. В минимальный тариф входят 50 СМС-сообщений в месяц. Стоимость $12–200 в месяц.
50 мониторов с частотой проверки раз в 5 минут бесплатно. Проверяет HTTP(s) протоколы, доступность портов, ключевые слова на странице. Удобная визуализация статистики – умеет создавать отдельные страницы для отображения доступности выбранных мониторов, доступ к которым можно получить без входа в панель администрирования.
Уведомления могут быть отправлены большим количеством способов – от банальных Slack и Telegram до собственной RSS-ленты со статусами мониторов.
Стоимость – около $120 в год ($10 в месяц) за 150 мониторов с частотой обновления раз в минуту.
Есть бесплатный тариф с неограниченным (!) количеством мониторов и частотой проверки раз в 5 минут. Проверяет HTTP(s)-протоколы, пинг, доступность указанных портов, SSH. Уведомления может отправлять на почту, в Slack, HipChat, PublicTweet и в другие менее известные каналы связи. Большой минус – цена, от $25 в месяц.
Умеет проверять многочисленные методы HTTP-протоколов, содержимое ответа сервера по ключевым словам, FTP, DNS, стандартные почтовые протоколы, пинг, доступность портов и многое другое.
Представлено три тарифа в зависимости от количества мониторов. Уведомления отправляются по стандартным каналам – почта, Pushover, Slack, есть возможность голосовых звонков. Стоимость $8–50 в месяц.
Наверное, самый известный русскоязычный сервис мониторинга.
Проверяет HTTP-протокол, FTP, работоспособность БД MySQL и PostgreSQL, почтовые протоколы, DNS, пинг и TelNet. Количество мониторов не ограничено. Уведомления рассылает в Telegram, почту, Skype, аську и Jabber. Фиксированных тарифов нет, оплачивается каждая проверка, стоит $0,00015.
Таблица характеристик систем внешнего мониторинга
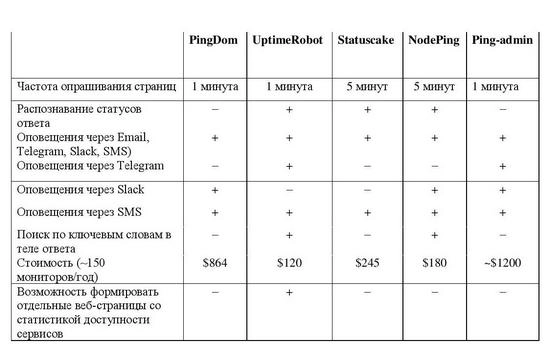
Как видно из таблицы, для установленных ранее критериев UptimeRobot – это наиболее подходящая система мониторинга. Он умеет распознавать статусы ответа страницы, искать ключевые слова на указанных страницах, интегрирован с используемым в компании мессенджером, есть возможность формировать WebHook и RSS-ленты со статусами мониторов. Кроме того, его стоимость чуть ли не минимальна среди выбранных сервисов.
Настройка уведомлений, интеграция с мессенджером
Одной из основных функций мониторинга должна была быть отправка сообщений о статусах мониторов в мессенджер. Соответственно, для каждого проекта сообщения для удобства должны были передаваться в отдельный чат. UptimeRobot интегрирован с мессенджером, но не может разделять сообщения о падениях по проектам и отправлять их в разные чаты. Решение нашлось.
UptimeRobot отправляет сообщения о текущих статусах мониторов через несколько каналов, в том числе Web-Hooks, инструмент для определения изменения состояния веб-страницы. Соответственно, для связи UptimeRobot`a и мессенджера нужен был сервис, способный обрабатывать созданные Web-Hook сообщения и отправлять их в мессенджер, например IFTTT.
IFTTT (If This Then That) представляет собой сервис обработки триггеров. В нашем случае он проверяет Web-Hook от UptimeRobot`a на наличие новых записей и при их появлении отправляет в мессенджер сообщение по установленному шаблону. В ответе от сервиса мониторинга поступает название монитора, статус Up или Down, время события.
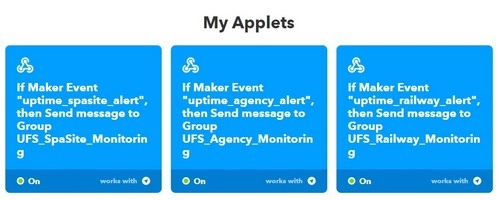
Общий вид чатов мониторинга представляет собой следующее:
Кейсы с внедренным мониторингом
1. Полное падение системы
Андрей Матвеев, UFS:
«Первый инцидент произошел через неделю после установки бесплатной версии UptimeRobot`a, включающей до 50 мониторов, опрашиваемых с интервалом один раз в 5 минут. Для проверки было установлено около 30 ключевых страниц сайта. В субботу утром мониторинг сообщил о падении абсолютно всех добавленных в него страниц. Оказалось, что сайт был недоступен полностью, а вместе с ним и все остальные сервисы компании. Простой составил около 30 минут, так как внезапно изменились параметры DNS-сервера. Внутренний же мониторинг проблем не обнаружил, поскольку находился внутри сети, а оттуда все сервисы исправно работали. Очевидно, что без внешних средств проверки сайта проблема была бы намного глобальнее».
2. Изменение типа вагона и падение главного направления
Александр Виниченко, UFS:
«В мониторинг были добавлены страницы доступных поездов по десяти самым популярным направлениям: Москва – Санкт-Петербург, Москва – Казань и т. д. Обычно при поломках у поставщика данных или на нашей стороне падали все страницы одновременно, так как логика их работы одинаковая. Однако произошел случай, когда перестала отвечать только страница направления Москва – Санкт-Петербург, остальные направления работали в обычном режиме. После анализа ответа провайдера выяснилось, что для поезда со стандартными типами вагонов (плацкарт, купе, СВ) назначены типы вагонов «Сапсана» («Эконом», «Бизнес» и т. д.) Приложение, не получив привычных данных, ломалось и не отдавало корректного списка поездов. Проблему оперативно решили, избежав простоя страницы по самому прибыльному направлению».
ИТ-мониторинг — это автоматическая система мониторинга ИТ-инфраструктуры
предприятия, которая позволяет контролировать параметры всех ИТ-систем в заданных рамках, оперативно
устранять и предотвращать сбои в их работе.
Подключение услуги мониторинга IT-систем позволяет решать следующие задачи:
- Автоматическое оповещение и выполнение определенных действий в случае обнаружения проблем на
ИТ-объектах. - Сбор и хранение данных о различных параметрах ИТ-систем, в том числе с помощью SNMP.
- Проактивное реагирование, прогнозирование и недопущение потенциальных сбоев ИТ-систем.
- Контроль качества ИТ-обслуживания.
Схема работы мониторинга ИТ-систем

Как
работает ИТ-мониторинг: Серверная часть системы представляет собой программное обеспечение, которое отвечает
за работу системы в целом. Мониторинг объектов происходит либо напрямую с сервера с помощью внешних проверок,
либо на ИТ-объект ставится специальное ПО – агент. В случае установки агента возможности отслеживания
значительно расширяются. Все данные, поступившие в систему, хранятся в базе данных и далее обрабатываются.
Для просмотра информации используется панель мониторинга — приложение, на которое в графическом и текстовом виде
выводится информация об объектах отслеживания. В случае превышения критических значений срабатывает оповещение
ответственных сотрудников.
Для чего можно использовать ИТ-мониторинг:
Преимущества ИТ-мониторинга:
- Значительное сокращение количества сбоев ИТ-инфраструктуры.
- Сокращение общего времени простоя ИТ-сервисов.
- Сокращение времени реакции специалиста на инцидент.
- Предотвращение возможных финансовых потерь по причине простоя ИТ-систем.
- Централизованный контроль параметров всей инфраструктуры на одной консоли.
- Повышение качества ИТ обслуживания.
- Сокращение затрат на ИТ-персонал.
- Привлекательная цена услуги.

Возможности системы ИТ-мониторинга
Благодаря использованию широкого спектра средств мониторинга
ИТ-инфраструктуры, сбор данных осуществляется с помощью различных инструментов:
- Сбор подробной информации с помощью нативного кроссплатформенного
агента. Агент системы ИТ-мониторинга может быть как пассивным (сервер
подключается к нему извне и собирает информацию) так и активным (сам отправляет
информацию на сервер). Во втором случае не нужно специально открывать порты для
организации мониторинга. - Сбор данных с оборудования с помощью протоколов SNMP, IPMI,
JMX. - Безагентный мониторинг — внешние проверки доступности
сервисов по любым TCP и UDP портам, а также ICMP.
Мониторинг ИТ-процессов на различных объектах инфраструктуры позволяет
осуществлять комплексный подход к обслуживанию ИТ-систем предприятия.
- Мониторинг серверов с любой операционной системой (Windows, Linux,
FreeBSD,MacOS); - Мониторинг баз данных (MSMSQL, MySQL, Oracle, PostGre и др.);
- Мониторинг сетевого оборудования (коммутаторы, маршрутизаторы, точки доступа,
сетевые хранилища, видеорегистраторы и др.); - Мониторинг приложений и служб;
- Мониторинг веб-сайтов;
- Мониторинг систем хранения данных (СХД);
- Мониторинг цифровых АТС и IP-телефонии;
- Мониторинг бизнес-процессов.
Мониторинг информационных систем поддерживает различные варианты
представления собранной информации:
Динамические графики. Динамика активности изменения параметров
ИТ-систем представлена в виде графиков. Например, возможно наглядно посмотреть какая
была загрузка процессора на сервере в течении дня или как менялось количество активных
пользователей на сервере.

Комплексные экраны. Возможно создавать пользовательские консоли с
необходимым набором данных. Например, на одном экране можно объединить таблицы, графики
и другую информацию.

Карта сети. Графическое отображение всех узлов компьютерной сети
и их состояния.

Цветовая идентификация параметров. Для каждого параметра
настраивается несколько уровней критичности, при превышении которых срабатывает цветовая
идентификация. В случае когда все показатели в норме – на панели мониторинга все
показатели светятся зеленым цветом. Если же какой-то параметр выходит за пределы нормы,
то соответствующая ему ячейка окрашивается в другой цвет. Обычно цвета меняются от
желтого или бледно-розового (наименьшая критичность) до ярко-красного (чрезвычайная
критичность). Таким образом, можно легко понять, с какими объектами все хорошо, на каких
есть проблема, а на каких критическая ситуация.

Система оповещения. Система ИТ-мониторинга поддерживает оповещения
заинтересованных сотрудников в случае наступления критического события по Email, SMS или
через систему мгновенных сообщений.
Автоматическое выполнение действий. В случае превышения
критического значения можно не только настроить оповещение, но и выполнить конкретное
действие: запустить внешнее приложение, перезапустить службу, выполнить скрипт и так
далее. Например, в случае если не была сделана резервная копия, можно выполнить
повторный запуск скрипта для её создания.
Мониторинг SLA. С помощью системы ИТ-мониторинга происходит
подсчет процента времени простоя ИТ-услуг, что позволяет сделать выводы о качестве их
предоставления.
Гибкое разграничение прав. Возможность разграничить доступ к узлам
мониторинга между пользователями.
Шаблонизация. Возможность применять для мониторинга узла уже
готовый набор отслеживаемых параметров, а не создавать их каждый раз заново. Шаблон
можно подключать из библиотеки или же создать самому. В библиотеке системы мониторинга
уже есть шаблоны наиболее популярного оборудования и ПО.
Собственный API. Поддерживается интеграция системы IT-мониторинга
инфраструктуры с другими программными решениями, например тикет-системой.
Нам доверяют клиенты
На практике внедрение большинства систем мониторинга ИТ-инфраструктуры сопряжено с различными ограничениями и сложностями
В современном мире, учитывая архитектурную сложность и территориальную распределенность ИТ-инфраструктур, непросто встретить среднюю или крупную компанию, не использующую системы ИТ-мониторинга. Сбои в работе ИТ-оборудования при отсутствии адекватного мониторинга, использующего инструменты оповещения, визуализации и реагирования, способны серьезно пошатнуть бизнес-процессы, а следовательно, принести существенные финансовые потери. Однако на практике внедрение большинства систем мониторинга ИТ-инфраструктуры сопряжено с различными ограничениями и сложностями.
Выбирая систему мониторинга ИT-инфраструктуры, необходимо принимать во внимание не только характеристики и возможности отдельно взятого комплекса, но и учитывать такие нюансы, как сложность развертывания, стоимость сопровождения и наличие соответствующих компетенций в компании. Далее рассмотрим наиболее популярные open-source системы мониторинга ИТ-инфраструктуры, сегментируем их на категории в зависимости от основных принципов и парадигмы работы, выявим достоинства и недостатки и определим, существует ли единственно лучшая система или же каждая из рассмотренных в статье может найти своего функционального заказчика.
Zabbix, Nagios
Наиболее популярными и узнаваемыми системами ИT-мониторинга являются такие решения, как Zabbix и Nagios. Они построены на базе программного обеспечения с открытым исходным кодом и давно зарекомендовали себя как качественные и успешно решающие целевые задачи продукты. И Zabbix, и Nagios способны осуществлять мониторинг большинства компонентов любой современной ИT-инфраструктуры, включая сетевое оборудование, ОС, различные приложения, базы данных, платформы виртуализации и т. д. Обе системы поддерживают агентский и безагентский сбор данных с целевых источников, имеют инструменты оповещения, визуализации и реагирования, а также сторонние плагины и возможность модернизации логики работы с помощью внешних скриптов. С коммерческой точки зрения у обоих решений предусмотрена платная поддержка, а у Nagios еще и платная версия системы – Nagios XI с дополнительными возможностями и более современной визуальной оболочкой.
Данные решения находятся в одной категории, достаточно схожи по своему функционалу и поэтому имеют аналогичные достоинства и недостатки (таблица 1).
Таблица 1. Достоинства и недостатки Zabbix и Nagios
В современном мире, учитывая архитектурную сложность и территориальную распределенность ИТ-инфраструктур, непросто встретить среднюю или крупную компанию, не использующую системы ИТ-мониторинга. Сбои в работе ИТ-оборудования при отсутствии адекватного мониторинга, использующего инструменты оповещения, визуализации и реагирования, способны серьезно пошатнуть бизнес-процессы, а следовательно, принести существенные финансовые потери. Однако на практике внедрение большинства систем мониторинга ИТ-инфраструктуры сопряжено с различными ограничениями и сложностями.
Выбирая систему мониторинга ИT-инфраструктуры, необходимо принимать во внимание не только характеристики и возможности отдельно взятого комплекса, но и учитывать такие нюансы, как сложность развертывания, стоимость сопровождения и наличие соответствующих компетенций в компании. Далее рассмотрим наиболее популярные open-source системы мониторинга ИТ-инфраструктуры, сегментируем их на категории в зависимости от основных принципов и парадигмы работы, выявим достоинства и недостатки и определим, существует ли единственно лучшая система или же каждая из рассмотренных в статье может найти своего функционального заказчика.
Prometheus, Graphite
Во вторую категорию входят современные решения, к которым можно отнести такие системы, как Prometheus и Graphite. Они появились сравнительно недавно и активно развиваются. Архитектура обоих решений направлена именно на работу с time-series-данными. Независимо от метода сбора (SNMP/агенты), итоговое представление и хранение данных в обоих решениях будет в формате временных рядов, за исключением, что Graphite хранит данные в кольцевой СУБД Whisper, а Prometheus – в файлах (используя многомерную модель с продвинутыми механизмами индексирования и тегирования).
Поскольку рассматриваемые решения появились сравнительно недавно, разработчики учли многие недостатки предыдущих систем и постарались сделать решения более гибкими и удобными. Помимо наличия основополагающего функционала по мониторингу ИТ-метрик, Graphite и Prometheus имеют ряд преимуществ, но не обошлось и без недостатков (таблица 2).
Таблица 2. Достоинства и недостатки Graphite и Prometheus
Custom IT-monitoring stacks
В третью категорию следует отнести индивидуальные разработки, основанные на различных технологических стеках. Многие крупные компании, учитывая недостатки вышерассмотренных решений, стремятся избавиться от них путем комбинирования технологических компонентов и внутренней разработки.
Принимая во внимание, что Graphite и Prometheus не являются готовыми решениями и не рассчитаны для работы «из коробки», их часто используют как основу для проектирования итоговой системы. Например, в том же Graphite можно заменить подсистему хранения данных с Whisper популярным InfluxDB, оптимизировав тем самым хранение time-series-данных. Или, при необходимости обеспечения отказоустойчивости и реализации OLAP-сценария обработки данных, можно выбрать связку ClickHouse+ZooKeeper, обеспечив максимально эффективные хранение и обработку данных. Eсли же требуется более красивый и функциональный интерфейс, к любому из четырех вышерассмотренных решений можно добавить инструмент Grafana, позволяющий по-новому взглянуть на собираемые ИT-метрики. А если добавить пару самописных сервисов для решения узкоспециализированных задач, удастся получить практически идеальную систему ИT-мониторинга. Может возникнуть вопрос, почему «практически»? Ответ прост: крайней высокая сложность сопровождения подобной системы. При возникновении внештатных ситуаций или необходимости доработки системы, в случае отсутствия высококвалифицированных специалистов, компания может столкнуться с серьезными проблемами. Чтобы избежать такого развития событий, в штате компании обязательно должны присутствует специалисты с соответствующими компетенциями. В таблице 3 представлены ключевые достоинства и недостатки, присущие рассматриваемому подходу в построении систем по мониторингу ИТ-инфраструктуры.
Таблица 3. Достоинства и недостатки Custom IT-monitoring stacks
Альтернативным решением, позволяющим нивелировать рассмотренные выше недостатки, является использование современных коммерческих систем. На зарубежном рынке представлено достаточно много решений от крупных вендоров – ManageEngine OpManager, IBM Tivoli Monitoring, Solarwinds Network Performance Monitor и других. На российском рынке также имеются активно развивающиеся продукты в сфере ИIT-мониторинга, в частности Naumen Network Manager и NGRSOFTLAB Dataplan. Каждый из этих продуктов предлагает современный стек технологий, продвинутые инструменты по оповещению и реагированию, а также качественную официальную поддержку.
Итоги
Проанализировав наиболее популярные решения в области ИT-мониторинга, разбив их на категории и выделив ключевые преимущества и недостатки, можно подвести итоги. Как оказалось, единственного наилучшего решения не существует. При выборе системы мониторинга ИT-инфраструктуры необходимо руководствоваться в первую очередь тем, какие задачи и бизнес-цели стоят перед внедряемой системой и сложностью внедрения и сопровождения.
Если вам нужна проверенная временем система для классического мониторинга утилизации аппаратных и программных ресурсов вашей инфраструктуры, с отличными возможностями по оповещению и наличием официальной поддержки, то Zabbix или Nagios – отличный выбор.
Если в вашей инфраструктуре ИT-мониторинг в первую очередь означает сбор узкоспециализированных метрик с различных приложений, самописных сервисов и систем, подсистемы хранения и визуализации данных в Zabbix или Nagios кажутся откровенно устаревшими, а наличие официальной поддержки для компании не является обязательным условием, то предпочтительны такие решения, как Prometheus или Graphite.
При выборе же решения, в котором необходимо наличие функционала по обеспечению отказоустойчивости хранения собираемых данных, возможности ретроспективного анализа и решения сложных комплексных задач ИT-мониторинга, следует обратить внимание на современные коммерческие решения, предлагаемые в том числе и на российском рынке.
