
26 августа, 2020 12:06 пп
Стек Elastic (ранее ELK) – это набор открытых программ, разработанных компанией Elastic
, который позволяет выполнять поиск, анализ и визуализацию логов любого источника в любом формате. Такая практика называется централизованным логированием. Такое логирование очень полезно при выявлении проблем и неполадок сервера или приложения, поскольку все данные логов собираются в одном месте. Также с помощью этого можно очень быстро обнаружить неполадку, которая влияет на работу сразу нескольких серверов в кластере, сопоставив их логи за определенный период времени.
Стек Elastic включает четыре основных компонентов:
- Elasticsearch
: распределенная поисковая система RESTful
, которая хранит все собранные данные. - Logstash
: компонент для обработки данных, который отправляет входящие данные на Elasticsearch. - Kibana
: веб-интерфейс для поиска и визуализации логов. - Beats
: легкие специализированные отправители данных; могут передавать данные на Logstash или Elasticsearch с сотен или тысяч машин.
Данный мануал поможет установить Elastic Stack
на сервер Ubuntu 20.04. Вы узнаете, как установить все компоненты, включая Filebeat
(Beat для пересылки и централизации логов и файлов), и настроить их для сбора и визуализации системных логов. Обычно Kibana устанавливается только на локальном хосте, потому мы настроим прокси Nginx, чтобы получить доступ к Kibana через веб-браузер. Мы установим все эти компоненты на один сервер.
Примечание
: В стеке Elastic нужно использовать одинаковые версии всех компонентов. В этом мануале мы установим последние версии пакетов, это Elasticsearch 7.7.1, Kibana 7.7.1, Logstash 7.7.1, and Filebeat 7.7.1.
- Требования
- 1: Установка и настройка Elasticsearch
- 2: Установка и настройка Kibana
- 3: Установка и настройка Logstash
- 4: Установка и настройка Filebeat
- 5: Дашборды Kibana
- Заключение
- Before we get started
- Configure Fluent Bit
- Input Configuration
- Конфигурация выхода
- Начинайте отправлять свои логи!
- Дополнительные настройки конфигурации
- Зачем использовать Fluent Bit?
- Упростите конвейеры Fluent Bit с помощью Calyptia Core
- Требования
- 1: Определение внутренних IP-адресов
- 2: Настройка адреса Elasticsearch
- 3: Настройка сервера для централизованного хранения логов
- 4: Настройка rsyslog для удаленной отправки данных
- 5: Преобразование логов в JSON
- 6: Настройка отправки данных в Logstash
- 7: Настройка Logstash для получения сообщений JSON
- 8: Тестирование Elasticsearch
- Заключение
Требования
- Сервер Ubuntu 20.04, настроенный по этому мануалу
. - Объем CPU, RAM и хранилища сервера ELK зависит от объема логов, которые вы будете собирать. В данном мануале используется сервер с такими характеристиками: RAM: 4GB, CPU: 2.
- OpenJDK 11 (инструкции по установке вы найдете в мануале Установка Java с помощью apt в Ubuntu 20.04
). - Nginx, прокси-сервер для Kibana. Инструкции по установке можно найти здесь
.
Также очень важно обеспечить безопасность сервера, поскольку стек Elastic используется для доступа к ценной информации, которую не должны видеть неавторизованные пользователи. Для этого создайте сертификат TLS/SSL. Это необязательно, но настоятельно рекомендуется сделать.
Настройка Nginx будет меняться, а потому вы можете выполнить Создание сертификата Let’s Encrypt для Nginx в Ubuntu 20.04
в конце второго раздела. Если вы собираетесь это сделать, вам понадобится:
- FQDN. Здесь используется условный домен your_domain.
- Две записи А – для www.your_domain и your_domain – указывающие на внешний IP-адрес сервера.
1: Установка и настройка Elasticsearch
Компоненты стека Elastic не доступны в стандартных репозиториях Ubuntu. Но их можно установить с помощью APT, если добавить исходный список Elastic.
Все пакеты Elastic Stack подписаны с помощью ключа Elasticsearch, чтобы защитить систему от подделки пакетов. Пакеты, прошедшие проверку подлинности с использованием ключа, будут считаться вашим менеджером пакетов доверенными. На этом этапе мы импортируем открытый ключ GPG Elasticsearch и добавим исходный список пакета Elastic для установки Elasticsearch.
Используйте инструмент командной строки cURL, чтобы импортировать открытый ключ GPG Elasticsearch в APT. Обратите внимание, что мы используем аргументы -fsSL, чтобы подавить вывод о прогрессе и потенциальных ошибках (кроме сбоя сервера) и позволить cURL перенаправить запрос. Мы направляем вывод команды cURL в apt-key, которая добавляет открытый ключ GPG в APT.
Затем добавьте список Elastic в каталог sources.list.d, где менеджер apt будет искать новые пакеты.
Обновите индекс пакетов:
sudo apt update
Теперь просто установите Elasticsearch.
sudo apt install elasticsearch
После установки Elasticsearch откройте текстовый редактор, чтобы отредактировать главный конфигурационный файл Elasticsearch, elasticsearch.yml. Здесь мы будем использовать nano:
sudo nano /etc/elasticsearch/elasticsearch.yml
Примечание
: Конфигурационный файл Elasticsearch пишется в формате YAML, а это означает, что отступы очень важны. Убедитесь, что при редактировании этого файла не появились лишние пробелы.
Файл elasticsearch.yml предоставляет параметры конфигурации для вашего кластера, нод, путей, памяти, сети, обнаружения и шлюзов. Большинство этих параметров имеет стандартное значение, но вы можете изменить их в соответствии с вашими потребностями. Для кластера, состоящего из одного сервера, мы изменим настройки только для сетевого хоста.
Elasticsearch прослушивает трафик через порт 9200. Нужно ограничить внешний доступ к экземпляру Elasticsearch, чтобы запретить посторонним пользователям читать ваши данные или не дать остановить работу кластера Elasticsearch через REST API. Найдите строку network.host, раскомментируйте ее и замените ее значение на localhost, чтобы она выглядела следующим образом:
. . .
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: localhost
. . .
Это минимальная настройка, необходимая для запуска Elasticsearch.
Теперь вы можете впервые запустить сервис Elasticsearch с помощью systemctl:
sudo systemctl start elasticsearch
Затем добавьте сервис в автозагрузку, чтобы Elasticsearch запускался при каждой загрузке вашего сервера:
sudo systemctl enable elasticsearch
Убедитесь, что сервис Elasticsearch работает, отправив HTTP-запрос:
curl -X GET "localhost:9200"
Вы увидите основную информацию о вашем локальном хосте:
Поисковая система Elasticsearch установлена и запущена.
2: Установка и настройка Kibana
Согласно официальной документации
, устанавливать Kibana следует только после Elasticsearch. Такой порядок гарантирует, что все зависимые друг от друга программы будут установлены правильно.
Поскольку вы уже добавили исходный список Elastic, сейчас вы можете просто установить остальные компоненты стека с помощью apt:
sudo apt install kibana
Чтобы включить сервис Kibana, введите:
sudo systemctl enable kibana
sudo systemctl start kibana
Поскольку Kibana прослушивает только локальный хост, нужно настроить обратный прокси-сервер, чтобы разрешить внешний доступ к сервису. Для этой цели мы будем использовать Nginx, который уже должен быть установлен на вашем сервере (согласно требованиям к мануалу).
Введите и подтвердите пароль в командной строке. Запомните эти данные, так как они понадобятся вам для доступа к веб-интерфейсу Kibana.
Далее нужно создать файл блока server Nginx. Мы используем условный домен your_domain, но вы можете выбрать более описательное имя. Например, если у сервера есть FQDN и DNS-записи, вы можете назвать этот файл своим доменным именем:
sudo nano /etc/nginx/sites-available/your_domain
Обратите внимание: если вы до конца выполнили мануал по Nginx (из требований), вероятно, вы уже создали такой файл и заполнили его некоторым кодом. В этом случае удалите все существующее содержимое в файле, а потом добавьте такой код.
Сохраните и закройте файл.
Включите новую конфигурацию, добавив симлинк в каталог sites-enabled. Если вы создали файл блока server с таким же именем ранее, вам не нужно делать этого.
sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
Проверьте ошибки в файле:
sudo nginx -t
Если в выводе команда сообщает об ошибках, вернитесь в файл и проверьте код, который вы поместили в файл конфигурации. Исправив ошибки, снова запустите команду (в выводе должно быть syntax is ok ) и перезапустите Nginx:
sudo systemctl reload nginx
Если вы следовали мануалу по начальной настройке сервера, у вас должен быть включен брандмауэр UFW. Чтобы разрешить подключения к Nginx, нужно настроить брандмауэр, набрав:
sudo ufw allow 'Nginx Full'
Примечание
: Если вы следовали мануалу по установке Nginx, вероятно, ранее вы создали правило UFW, разрешающее профиль HTTP Nginx. Поскольку профиль Nginx Full поддерживает трафик HTTP и HTTPS, вы можете просто удалить это правило с помощью следующей команды:
sudo ufw delete allow 'Nginx HTTP'
На странице вы увидите информацию об использовании ресурсов и установленных плагинах.
Примечание
: В требованиях упоминалось, что сервер нужно защитить с помощью сертификата SSL/TLS. Сейчас самое время сделать это. Инструкции можно найти здесь
.
3: Установка и настройка Logstash
Beats может отправлять данные напрямую в базу данных Elasticsearch, но мы рекомендуем использовать для обработки данных Logstash. Это позволит вам собирать данные из разных источников, преобразовывать их в общий формат и экспортировать в другую базу данных.
Установите Logstash с помощью этой команды:
sudo apt install logstash
Создайте конфигурационный файл 02-beats-input.conf для настройки входных данных Filebeat.
sudo nano /etc/logstash/conf.d/02-beats-input.conf
Вставьте в файл такую конфигурацию. Она настраивает прослушивание входных данных beats по TCP-порту 5044.
Сохраните и закройте файл. Затем создайте файл 30-elasticsearch-output.conf:
sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf
Вставьте следующую конфигурацию вывода. По сути, эти параметры настраивают Logstash для хранения данных Beats в базе Elasticsearch (по адресу localhost:9200) в индексе с именем используемого Beat. Beat, использованный в этом мануале, называется Filebeat.
Сохраните и закройте файл.
Проверьте свою конфигурацию Logstash:
Если ошибок нет, через несколько секунд вывод сообщит «Config Validation Result: OK. Exiting Logstash». Если вы не видите этого сообщения в выводе, проверьте наличие ошибок и обновите конфигурацию, чтобы исправить их.
Если проверка конфигурации прошла успешно, запустите и включите Logstash, чтобы изменения вступили в силу:
sudo systemctl start logstash
sudo systemctl enable logstash
4: Установка и настройка Filebeat
Elastic Stack использует несколько простых клиентов Beats для сбора данных из различных источников и их передачи в Logstash или Elasticsearch. Вот Beats, которые в настоящее время доступны в Elastic:
В этом мануале мы используем Filebeat, клиент для передачи логов в стек Elastic.
sudo apt install filebeat
Затем настройте Filebeat для подключения к Logstash. Отредактируйте образец файла конфигурации, который поставляется вместе с Filebeat. Откройте файл.
sudo nano /etc/filebeat/filebeat.yml
Примечание
: Как и в случае Elasticsearch, конфигурационный файл Filebeat имеет формат YAML, а в нем очень важны правильные отступы.
Filebeat поддерживает множество выходных данных, но обычно события отправляются непосредственно в Elasticsearch или на обработку в Logstash. В этом мануале мы будем использовать Logstash для дополнительной обработки данных, собранных Filebeat. Клиенту Filebeat не нужно будет напрямую отправлять данные в Elasticsearch, поэтому давайте отключим этот вывод. Для этого найдите раздел output.elasticsearch и закомментируйте следующие строки, поставив перед ними знак #:
Сохраните и закройте файл.
Функциональность Filebeat можно расширить с помощью модулей
. В этом мануале мы будем использовать модуль system
, который собирает и анализирует логи, созданные сервисом системных логов Linux.
sudo filebeat modules enable system
Получить список включенных и отключенных модулей можно с помощью:
По умолчанию Filebeat использует пути системного лога и лога авторизации по умолчанию. В данном случае в конфигурации не нужно ничего менять. Вы можете увидеть параметры модуля в файле /etc/filebeat/modules.d/system.yml.
Затем нам нужно настроить конвейеры приема Filebeat, которые анализируют данные логов перед отправкой их в logstash, а потом в Elasticsearch. Чтобы загрузить конвейер для модуля system, введите следующую команду:
sudo filebeat setup --pipelines --modules system
Затем загрузите шаблон индекса в Elasticsearch. Индекс Elasticsearch
– это набор документов, имеющих сходные характеристики. Индексы определяются по имени. Имя используется для ссылки на индекс при выполнении различных операций в нем. Шаблон индекса будет автоматически использоваться при создании нового индекса.
Чтобы загрузить шаблон, используйте следующую команду:
Filebeat поставляется с образцами дашбордов Kibana, которые позволяют визуализировать данные Filebeat в Kibana. Прежде чем вы сможете использовать дашборды, вам нужно создать шаблон индекса и загрузить дашборд в Kibana.
Когда дашборд будет загружен, Filebeat подключится к Elasticsearch для проверки информации о версии. Если Logstash включен, необходимо отключить вывод Logstash и включить вывод Elasticsearch, чтобы загрузить дашборды.
Вы увидите примерно следующее:
Overwriting ILM policy is disabled. Set `setup.ilm.overwrite:true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup --machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
Loaded machine learning job configurations
Loaded Ingest pipelines
Теперь можно запустить Filebeat и добавить его в автозагрузку:
sudo systemctl start filebeat
sudo systemctl enable filebeat
Если вы правильно настроили свой стек Elastic, Filebeat начнет отправку системного лога и логов авторизации в Logstash, который затем загрузит эти данные в Elasticsearch.
Чтобы убедиться, что Elasticsearch действительно получает эти данные, запросите индекс Filebeat с помощью этой команды:
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
Вы должны получить такой результат:
Если ваши выходные данные показывают 0 total hits, Elasticsearch не загружает логи в индекс, который вы искали, и вам нужно будет проверить настройки на наличие ошибок. Если вы получили ожидаемый результат, переходите к следующему разделу, в котором вы узнаете, как работать с дашбордами Kibana.
5: Дашборды Kibana
Теперь давайте посмотрим, как работает Kibana.
В браузере откройте FQDN или внешний IP сервера Elastic. Введите свои учетные данные из раздела 2, и вы попадете на домашнюю страницу Kibana.
Нажмите Discover в левой панели навигации. На странице Discover выберите предопределенный шаблон индекса filebeat-*, чтобы увидеть данные Filebeat. По умолчанию будут показаны все данные лога за последние 15 минут. Вы увидите гистограмму с событиями и некоторыми сообщениями лога.
Здесь вы можете искать и просматривать логи, а также настраивать дашборды. На данный момент, однако, там не будет много данных, потому что сейчас отображаются только системные логи сервера Elastic Stack.
Используйте левую панель, чтобы перейти на страницу Dashboard и выполнить поиск по Filebeat System. Оказавшись там, вы можете искать примеры дашбордов, которые поставляются с модулем system.
Например, вы можете просмотреть подробную статистику на основе ваших сообщений системного лога или узнать, какие пользователи и когда использовали команду sudo.
У Kibana есть много других функций, таких как построение графиков и фильтров. Исследуйте их самостоятельно.
Заключение
Теперь вы знаете, как установить и настроить стек Elastic для централизованного сбора и анализа системных логов. Помните, что вы можете отправлять в Logstash практически любой тип лога или индексированных данных, используя Beats
, но данные будут еще более полезными, если их анализировать и структурировать с помощью фильтров Logstash: это преобразует их в согласованный формат, который Elasticsearch легко прочитает.
Tags: Elastic Stack
, ElasticSearch
, Filebeat
, Kibana
, Logstash
, Ubuntu
, Ubuntu 20.04
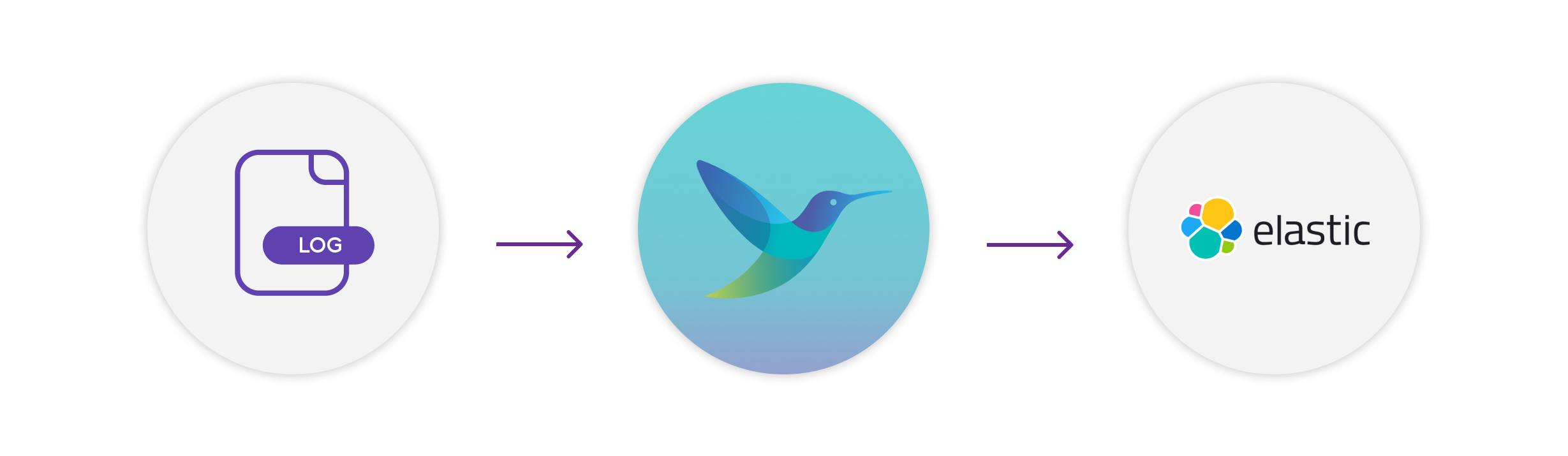
Logs are the foundational data of any observability effort. Elasticsearch
allows us to store, search, and analyze huge volumes of data quickly, making it ideal for the massive volumes of log and other telemetry data generated by modern applications. It is also one of the components of the ELK Stack (Elasticsearch, Logstash, and Kibana), a widely-used log management solution for companies.
Fluent Bit
is the leading open source solution for collecting, processing, and routing large volumes of telemetry data. When used as the agent for sending logs to Elasticsearch you have a highly performative telemetry pipeline.
Here we will show you how to send logs to Elasticsearch using Fluent Bit.
Before we get started
This tutorial assumes that you already have Fluent Bit installed and running on your source. It also assumes that you have Elasticsearch.
For this tutorial, we will be running Fluent Bit on an EC2 instance from AWS running Amazon Linux2 and sending the logs to Elastic Cloud, Elastic’s hosted service. The configurations you use will vary slightly depending on your source and whether you are using Elastic Cloud or another version of Elasticsearch
Configure Fluent Bit
Input Configuration
Fluent Bit accepts data from a variety of sources using input plugins. Плагин ввода Tail позволяет читать из текстового файла журнала, как если бы вы запускали tail -f
команда
[INPUT] Name tail Path /var/log/*.log Tag ec2_logs Конфигурация выхода
Как и в случае ввода, Fluent Bit использует плагины вывода для отправки собранных данных в нужные места.
Чтобы настроить конфигурацию, вам потребуется собрать некоторую информацию из развертывания Elasticsearch:
Конечная точка — см. изображение ниже, как найти из консоли
Идентификатор облака — см. изображение ниже, как найти его с консоли
Номер порта — при использовании Elastic Cloud это будет 9243
Учетные данные для аутентификации — они были предоставлены вам при создании кластера Elasticsearch. Если вы не записали их , вы можете сбросить пароль
.

[OUTPUT] Name es Match * Host https://sample.es.us-central1.gcp.cloud.es.io Cloud_auth elastic:yRSUzmsEep2DoGIyNT7bFEr4 Cloud_id sample:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvOjQ0MyQ2MDA4NjljMjA4M2M0ZWM2YWY2MDQ5OWE5Y2Y3Y2I0NCQxZTAyMzcxYzAwODg0NDJjYWI0NzIzNDA2YzYzM2ZkYw== Port 9243 tls On tls.verify Off
[OUTPUT] # optional: send the data to standard output for debugging name stdout match * Match *
Параметр указывает, что все данные, собранные Fluent Bit, будут перенаправлены в Elasticsearch. Мы также можем сопоставлять на основе тега, определенного во входном плагине. tls On
гарантирует, что соединение между Fluent Bit и кластером Elasticsearch является безопасным. По умолчанию Port
настроен на 9200, поэтому нам нужно изменить его на 9243, который является портом, используемым Elastic Cloud
Мы также определили дополнительный выход, который отправляет все данные на stdout
. Это не требуется для конфигурации Elasticsearch, но может быть чрезвычайно полезным, если нам нужно отладить нашу конфигурацию
.
Начинайте отправлять свои логи!
После сохранения изменений в файле fluent-bit.conf вам необходимо перезапустить Fluent Bit, чтобы новая конфигурация вступила в силу:
sudo systemctl restart fluent-bit Убедитесь, что Fluent Bit перезапущен правильно.
systemctl status fluent-bit Опять же, эти команды могут различаться в зависимости от вашей системы.
Теперь ваши журналы должны передаваться в Elasticsearch, и вы сможете искать свои данные
.
Дополнительные настройки конфигурации
Fluent Bit также позволяет обрабатывать данные перед их отправкой в конечный пункт назначения. Можно, например:
Маршрутизация особенно эффективна, поскольку позволяет перенаправлять второстепенные данные в более дешевое хранилище (или даже полностью удалять их), что может сэкономить вам тысячи долларов при использовании дорогостоящих приложений для хранения и анализа с ценой потребления.
Зачем использовать Fluent Bit?
Вы можете спросить себя, почему вам следует использовать Fluent Bit, а не Elastic Agent. Это справедливый вопрос.
Fluent Bit не зависит от поставщика
. Fluent Bit не волнует, какой бэкэнд вы используете. Он может отправлять данные во все основные бэкенды, такие как Elasticsearch, Splunk, Datadog и другие. Это поможет вам избежать дорогостоящей привязки к поставщику. Переход на новую серверную часть — это простое изменение конфигурации — нет необходимости устанавливать новый агент конкретного поставщика во всей вашей инфраструктуре.
Fluent Bit легкий
. Fluent Bit был создан как легкая и высокопроизводительная альтернатива Fluentd, предназначенная для развертывания в контейнерах и IOT. Его размер составляет всего ~ 450 КБ, но он, безусловно, превосходит свою весовую категорию, когда дело доходит до способности обрабатывать миллионы записей ежедневно .
.
Fluent Bit с открытым исходным кодом
. Fluent Bit — это дипломированный проект Cloud Native Computing Foundation под эгидой Fluentd.
Fluent Bit заслуживает доверия.
Fluent Bit был загружен и развернут миллиарды раз. Фактически, он включен в основные дистрибутивы Kubernetes, включая Google Kubernetes Engine (GKE), AWS Elastic Kubernetes Service (EKS) и Azure Kubernetes Service (AKS).
Упростите конвейеры Fluent Bit с помощью Calyptia Core
Как мы уже видели, Fluent Bit — мощный компонент конвейера телеметрии, и его относительно просто настроить вручную. Однако такая ручная настройка становится неприемлемой, когда ваша инфраструктура масштабируется до десятков, сотен или даже тысяч источников.
Запланировать демонстрацию
чтобы увидеть, как Calyptia Core может помочь вам сократить расходы и повысить производительность.
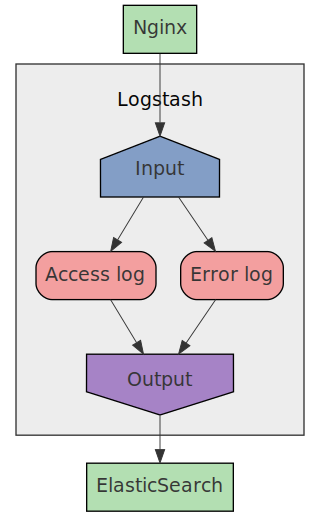
Далее мы настроим Logstash
сначала создав ./logstash
каталог и
затем начните работать над Logstash
Файл конфигурации.
Мы настроим Logstash
использовать:
- 1 вход
дляsyslog - 2 фильтра
обработать доступ
и ошибка
бревна - 1 выход
хранить обработанные журналы вElasticSearch
Мы будем использовать Logstash
Плагин фильтра Grok
для обработки поступающих nginx
журналы. Grok — это плагин, в котором вы пишете patterns
которые извлекают значения из
необработанные данные. Эти шаблоны написаны на соответствующем языке, где вы определяете
упрощенное регулярное выражение и дать ему имя.
METHOD (OPTIONS|GET|HEAD|POST|PUT|DELETE|TRACE|CONNECT)
Затем вы можете комбинировать эти именованные регулярные выражения для анализа более сложных
струны. Предположим, мы хотим разобрать первую строку HTTP-запроса,
может выглядеть так:
-
GET /db HTTP/1.1 -
POST /user/login HTTP/1.1
МЕТОД (ОПЦИИ|ПОЛУЧИТЬ|HEAD|POST|PUT|DELETE|TRACE|CONNECT)
REQUEST_START %{МЕТОД:метод} %{ДАННЫЕ:путь} HTTP/%{ДАННЫЕ:http_версия} Чтобы использовать этот шаблон, мы просто добавляем grok
конфигурация к filter
часть Logstash
файл конфигурации:
{ { => => { => } }
} GET /db HTTP/1.1
{ метод: , путь: , http_версия:
} { метод: , путь: , http_версия:
} Вот как выглядят наши шаблоны grok для доступа nginx
и ошибка
журналы:
МЕТОД (ОПЦИИ|ПОЛУЧИТЬ|HEAD|POST|PUT|DELETE|TRACE|CONNECT)
NGINX_ACCESS %{IPORHOST:visitor_ip} - %{USERNAME:remote_user} \[%{HTTPDATE:time_local}\] %{INT:status} %{INT:body_bytes_sent} %{QS:user_agent} ОШИБКА %{ГОД}/%{МЕСЯЦНОМ}/%{МЕСЯЦДЕНЬ} %{ВРЕМЯ}
NGINX_ERROR %{ERRORDATE:time_local} \[%{LOGLEVEL:level}\] %{INT:process_id}#%{INT:thread_id}: \*(%{INT:connection_id})? %{GREEDYDATA:описание} А вот как мы настраиваем Logstash
настроить syslog
вход, наш грок
узоры и ElasticSearch
выход:
{ { => => 5140 }
} { [] == { { => => { => } => [, ] => { => } => [] } { => [, ] => => } { => => => } } [] == { { => => { => } => [, ] => { => } => [] } { => [, ] => => } }
} { { => [] => правда => правда => => }
} Параметр program
на котором мы основываем наши if-cases, это tag
ценность, которую мы
настроен nginx
чтобы добавить к различным типам журналов:
Отправить журналы в Logstash =logstash:5140,tag=nginx_access logstash; =logstash:5140,tag=уведомление об ошибке nginx; Единственное, что осталось, прежде чем мы создадим Dockerfile, — это создать
ElasticSearch
шаблон для использования. Этот шаблон говорит ElasticSearch
какие поля
наши различные типы элементов журнала будут иметь. Если внимательно посмотреть на это
шаблон, вы заметите, что все определенные поля существуют в фильтре grok
определение.
{ : 50001, : , : { : { : } }, : { : { : { : ЛОЖЬ, : ЛОЖЬ }, : { : { : }, : { : }, : { : }, : { : }, : { : }, : { : }, : { : }, : { : }, : { : }, : { : }, : { : }, : { : }, : { : истинный, : { : { : }, : { : }, : { : }, : { : }, : { : }, : { : } } }, : { : } } }, : { : { : ЛОЖЬ, : ЛОЖЬ }, : { : { : }, : { : }, : { : }, : { : }, : { : }, : { : }, : { : } } } }, : {}
} Теперь, когда у нас есть все наши конфигурации для Logstash
установка, мы можем создать
Докерфайл:
логсташ: 5,5-альпийский PLUGIN_BIN установить logstash-input-syslog установить logstash-filter-date установить logstash-filter-grok установить logstash-filter-useragent установить logstash-output-elasticsearch ./conf /etc/logstash [, ]
код/nginx-elk-logging ├── docker-compose.yaml ├── логсташ │ ├── конф │ │ ├── es_template.json │ │ ├── logstash.conf │ │ └── паттерны │ │ ├── nginx_access │ │ └── nginx_error │ └── Dockerfile └── нгинкс ├── конф │ └── nginx.conf ├── данные │ └── index.html └── Dockerfile 6 каталогов, 9 файлов
24 апреля, 2017 11:55 дп
Работать с данными логов довольно сложно. Логи содержат много полезной информации о безопасности и производительности приложений и серверов. Но, с другой стороны, управление и анализ логов заниматься очень много времени.
Программное обеспечение с вероятным исходным кодом rsyslog, Elasticsearch и Logstash – удобное средство для передачи, преобразования и хранения данных логов.
Это руководство поможет создать централизованное хранилище протоколов нескольких систем и настроить передачу данных в Elasticsearch с помощью Logstash.
Централизованное логирование позволяет быстро выявлять и устранять проблемы серверов или приложений.
В результате вы получите рабочий лист для сбора системных логов нескольких систем.
Rsyslog собирает важную информацию из ядра и программного обеспечения для работы UNIX-подобных серверов. syslog — это стандарт, который многие программные продукты обнаруживают в системном журнале. Централизованное изучение данных журналов, вы можете быстро проверить безопасность, наличие файлов и других важных сведений об почтовых ящиках.
Затем можно переслать данные в Logstash для анализа данных журналов перед отправкой в Elasticsearch.
Требования
Для достижения успеха нужна инфраструктура из трех серверов, находящихся в одном ЦОД, с закрытой частной сетью.
- Сервер 1: Ubuntu 14.04, который будет называться rsyslog-client.
- Сервер 2: Ubuntu 14.04 (минимум 1 Гб), который будет называться rsyslog-server. Надежно хранить логи и Logstash.
- Сервер 3: Ubuntu 14.04 с ранее установленной платформой Elasticsearch (инструкции по установке здесь).
- Пользователь с доступом к sudo на каждом сервере (больше об этом – здесь
). - Частная сеть.
Примечание
: Чтобы увеличить производительность, Logstash выделяет 1 гигабайт памяти по умолчанию, поэтому гарантирует, что размер сервера 2 может быть таким.
1: Определение внутренних IP-адресов
Для этого можно использовать команду:
sudo ifconfig -a
Команда вернёт примерно такой вывод:
eth0 Link encap:Ethernet HWaddr 04:01:06:a7:6f:01
inet addr:123.456.78.90 Bcast:123.456.78.255 Mask:255.255.255.0
inet6 addr: fe80::601:6ff:fea7:6f01/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:168 errors:0 dropped:0 overruns:0 frame:0
TX packets:137 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:18903 (18.9 KB) TX bytes:15024 (15.0 KB)
eth1 Link encap:Ethernet HWaddr 04:01:06:a7:6f:02
inet addr:10.128.2.25 Bcast:10.128.255.255 Mask:255.255.0.0
inet6 addr: fe80::601:6ff:fea7:6f02/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:6 errors:0 dropped:0 overruns:0 frame:0
TX packets:5 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:468 (468.0 B) TX bytes:398 (398.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
2: Настройка адреса Elasticsearch
Если вы следовали руководству Установка и настройка Elasticsearch в Ubuntu 14.04, вы умеете привязывать Elasticsearch к локальному хосту. Но в таком случае другие серверы не смогут взаимодействовать с этим инструментом.
Перейдите на этот сервер (в данном случае это сервер 3) и откройте файл:
sudo nano /etc/elasticsearch/elasticsearch.yml
sudo service elasticsearch restart
Примечание
: Возможность подключаться к Elasticsearch должны иметь только заведомо безопасные серверы. Ограничьте доступ к серверу с помощью брандмауэра (например, iptables).
3: Настройка сервера для централизованного хранения логов
Примечание
: Данный раздел нужно выполнить на сервере rsyslog-server (согласно списку требований, это сервер 2).
Сервер rsyslog-server должен получать данные других серверов на порт 514.
Для этого откройте файл /etc/rsyslog.conf:
sudo nano /etc/rsyslog.conf
Найдите в файле следующие закомментированные строки:
# provides UDP syslog reception
#$ModLoad imudp
#$UDPServerRun 514
# provides TCP syslog reception
#$ModLoad imtcp
#$InputTCPServerRun 514
Строки $ModLoad imudp и $ModLoad imtcp загружают модули imudp (input module udp) и imtcp (input module tcp). Эти модули прослушивают входящие данные, поступающие от других серверов.
Строки $UDPSerververRun 514 и $TCPServerRun 514 указывают, что rsyslog должен запустить серверы UDP и TCP на порт 514 (стандартный порт syslog).
Чтобы включить эти модули и серверы, раскомментируйте строки:
# provides UDP syslog reception
$ModLoad imudp
$UDPServerRun 514
# provides TCP syslog reception
$ModLoad imtcp
$InputTCPServerRun 514
sudo service rsyslog restart
Теперь сервер для централизованного хранения данных будет прослушивать сообщения удалённых серверов syslog.
Примечание
: Чтобы проверить конфигурационный файл rsyslog, запустите:
sudo rsyslogd -N1
4: Настройка rsyslog для удаленной отправки данных
Теперь нужно настроить сервер rsyslog-client (сервер 1) для отправки данных логов на ryslog-server.
В стандартной установке rsyslog в Ubuntu каталог /etc/rsyslog.d содержит два файла:
- 20-ufw.conf
- 50-default.conf
Перейдите на сервер rsyslog-client и откройте конфигурационный файл:
sudo nano /etc/rsyslog.d/50-default.conf
Сохраните и закройте файл.
Чтобы обновить настройки, перезапустите rsyslog:
sudo service rsyslog restart
Примечание
: Чтобы проверить конфигурационный файл rsyslog, запустите:
sudo rsyslogd -N1
5: Преобразование логов в JSON
Elasticsearch требует, чтобы передаваемые данные были в формате JSON. Инструмент rsyslog предоставляет шаблон преобразования данных.
На данном этапе нужно настроить сервер 2 (rsyslog-server) для использования шаблона JSON. Это позволит отформатировать данные, прежде чем передать их в Logstash и Elasticsearch.
Вернитесь на сервер rsyslog-server и создайте новый конфигурационный файл, который будет форматировать логи в JSON.
sudo nano /etc/rsyslog.d/01-json-template.conf
Скопируйте следующие параметры и вставьте их в файл:
Обратите внимание: все строки (кроме первой и последней) содержат запятую в начале. Это должно поддержать структуру JSON и выровнять все отступы. Этот шаблон форматирует сообщения так, как этого требуют Elasticsearch и Logstash. Вот как они будут выглядеть:
Примечание
: На сайте rsyslog можно найти больше переменных для форматирования данных логов.
Шаблон для форматирования готов, теперь нужно настроить сервер для его использования.
6: Настройка отправки данных в Logstash
Теперь нужно настроить сервер rsyslog server для передачи данных в Logstash.
При запуске rsyslog будет читать файлы /etc/rsyslog.d и создавать конфигурации на их основе.
На сервере rsyslog-server создайте файл /etc/rsyslog.d/60-output.conf:
sudo nano /etc/rsyslog.d/60-output.conf
Вставьте в файл следующие строки:
В руководстве используется порт 10514. Logstash должен прослушивать этот же порт и протокол. Последняя часть строки определяет файл шаблона, который указывает, как форматировать данные перед их отправкой.
Не перезапускайте rsyslog. Сначала нужно настроить Logstash для получения сообщений.
7: Настройка Logstash для получения сообщений JSON
Теперь нужно настроить Logstash для получения сообщений rsyslog и передачи полученных данных в Elasticsearch.
Для работы Logstash нужно установить Java 7+. Инструкции по установке можно найти в руководстве Установка и настройка Elasticsearch в Ubuntu 14.04.
Установите ключ репозитория Logstash:
Добавьте определение репозитория в /etc/apt/sources.list:
Обновите индекс пакетов:
sudo apt-get update
sudo apt-get install logstash
По умолчанию конфигурационные файлы Logstash находятся в /etc/logstash/conf.d. Отредактируйте конфигурационный файл:
sudo nano /etc/logstash/conf.d/logstash.conf
Добавьте следующие строки в /etc/logstash/conf.d/logstash.conf:
Согласно определению протоколом syslog является UDP.
Блок input запускает прослушивание Logstash порта 10514. Для прослушивания портов меньше 1024 необходимо запускать Logstash как root, а это может быть опасно для сервера.
Протестируйте изменения настроек Logstash:
sudo service logstash configtest
Команда должна вернуть:
Если команда сообщила об ошибках, исправьте их.
После этого можно запустить Logstash:
sudo service logstash start
sudo service rsyslog restart
Убедитесь, что Logstash прослушивает порт 10514:
Команда должна вернуть:
udp6 0 0 10.128.33.68:10514 :::*
Примечание
: Чтобы устранить неисправности Logstash, остановите службу с помощью команды sudo service logstash stop и запустите:
/opt/logstash/bin/logstash -f /etc/logstash/conf.d/logstash.conf --verbose
8: Тестирование Elasticsearch
Серверы rsyslog-client и rsyslog-server должны отправлять все данные логов в Logstash, а оттуда данные будут передаваться в Elasticsearch. Сгенерируйте сообщение безопасности, чтобы убедиться, что Elasticsearch получает сообщения.
Перейдите на rsyslog-client и введите:
sudo tail /var/log/auth.log
В конце вывода вы увидите сообщение лога локальной системы:
Создайте простой запрос, чтобы проверить работу Elasticsearch.
Запустите следующую команду на сервере Elasticsearch или в любой системе, у которой есть доступ к этой платформе.
curl -XGET 'http://elasticsearch_ip:9200/_all/_search?q=*&pretty'
Обратите внимание: в логе указано имя сервера, который сгенерировал сообщение rsyslog (rsyslog-client).
Теперь установка полностью готова к работе.
Заключение
Вы настроили централизацию логов с помощью Elasticsearch и Logstash.
Tags: ElasticSearch
, JSON
, Logstash
, rsyslog
, Ubuntu 14.04
В одной из предыдущих статей
мы рассматривали особенности развертывания Apache Airflow
в кластере Kubernetes
, а в данном материале поговорим об отправке логов из Airflow
в Elasticsearch
. Давайте разберемся!
Как мы уже знаем, сбор логов в Kubernetes
кластере и отправка их в Elasticsearch
то еще удовольствие, поэтому при использовании Airflow
хотелось получить необходимый функционал “из коробки”. Но не тут то было:
Airflow can be configured to read task logs from Elasticsearch and optionally write logs to stdout in standard or json format. These logs can later be collected and forwarded to the Elasticsearch cluster using tools like fluentd, logstash or others.
То есть, отображать логи из эластика — запросто, а вот отправлять их в Elasticsearch
— без велосипеда никак!
В данном примере таким велосипедом будет связка Filebeat
и знакомые нам elastic pipelines
.
По сравнению с примерами из предыдущей статьи
об Airflow
, нам потребуется изменить:
- Dockerfile (добавив в него установку
filebeat
); - entrypoint-скрипт (перед запуском самого
airflow
будем стартоватьfilebeat
— не лучшая практика работы с docker-образами, но что ж поделать); - конфигмап для
airflow
(появится новая секция в основном конфиге и дополнительный файл с настройкамиfilebeat
).
После внесенных изменения наш Dockerfile превратится в следующий:
Entrypoint-скрипт будет выглядеть так:
Настройки для filebeat
в нашем случае будут (специально опубликую их отдельно):
А манифест для Kubernetes
кластера, вместе со всеми необходимыми объектами (сервис/деплоймент/секрет/измененный конфигмап) станет таким:
Elastic-пайплайн выглядит так:
Данный пайплайн добавляется с помощью следующей команды:
После применения предложенной конфигурации логи запускаемых DAG’ов будут посредством filebeat
отправляться в Elasticsearch
, а благодаря новым секциям
[elasticsearch] host = https://elasticUser:elasticPaasword@elasticHost:9200 log_id_template = {dag_id}|{task_id}|{execution_date}|{try_number} end_of_log_mark = end_of_log frontend = write_stdout = True json_format = True json_fields = asctime, filename, lineno, levelname, message [elasticsearch_configs] use_ssl = True verify_certs = True ca_certs = /es/certs/ca.pem указанным в конфигурационном файле airflow.cfg эти самые логи можно будет увидеть и в UI самого Airflow
.
На этом все, свои способы отправки логов из Airflow
в Elasticsearch
оставляйте в комментариях!
