

This article explores the benefits of such a rarely used and, in my opinion, undeservedly overlooked data type, as a range. We will first design the structure of the database for storing the age-experience coefficient when calculating the cost of an OSAGO policy within the framework of MySQL familiar to many. Then let’s redesign for PostgreSQL and see how the sql queries look in both cases. And in the final, let’s compare what advantages the use of ranges gives us.
The note is addressed to both MySQL users and PostgreSQL users who have not worked with this type of data in their practice. If your subject area has work with ranges of values, then this post is exactly for you.
This article explores the benefits of such a rarely used and, in my opinion, undeservedly overlooked data type as a range. We will first design the structure of the database for storing the age-experience coefficient when calculating the cost of an OSAGO policy within the framework of MySQL familiar to many. Then let’s redesign for PostgreSQL and see how the sql queries look in both cases. And in the final, let’s compare what advantages the use of ranges gives us.
The note is addressed to both MySQL users and PostgreSQL users who have not worked with this type of data in their practice. If your subject area has work with ranges of values, then this post is exactly for you.
Shared hosting, VPS, Dedicated server
Russia, Germany, Finland, Netherlands, Europe, Belarus, Kazakhstan
Wed. ticket response time:

Shared hosting, VPS, Dedicated server

Shared hosting, Dedicated server, VPS

Shared hosting, VPS, Dedicated server
Wed ticket response time:

Shared hosting, VPS, Dedicated server
Russia, Ukraine, Germany, Europe, Netherlands, Switzerland, USA

Shared hosting, VPS

Shared hosting, VPS, Dedicated server
Russia, Israel, Moldova, Netherlands, USA

Shared hosting, VPS, Dedicated server

Shared hosting, VPS, Dedicated server

Shared hosting, VPS, Dedicated server
Russia, Germany, Europe
Database structure for mysql
Two implementation options immediately come to mind:
use of one table, the rows of which store all variants of the age-experience-coefficient links
the use of three tables, two of which store ranges (one for age, the other for length of service), and the third contains the age-experience relationship and the value of the coefficient;
Let’s consider both of these options and fill the tables with data. But first, let’s set the boundary conditions. According to Wikipedia, the oldest living inhabitant of the planet, Lucille Randonlet, lived to be 118 in 2022 ( List of the oldest people in the world
). Driving license can be obtained from the age of 16. Potentially, Lucille’s driving experience could be 102 years. To fill the database with data, we will proceed from the calculation: age from 16 to 118 years, driving experience from 0 to 102 years.
Now let’s create the necessary tables for both options.
One table

create or replace table kvs
( age int not null comment 'Возраст', experience int not null comment 'Стаж', value decimal(4, 2) not null comment 'Значение КВС', primary key (age, experience)
) comment 'Коэффициент Возраст-Стаж'; Inserting data. As a result, we get 9314 entries:

A composite index on the age-experience fields will save us from erroneous insertion of duplicates in future changes in the coefficient. A request for a coefficient for a driver of 23 years and a driving experience of 3 years in this case will look like:
SELECT value FROM kvs WHERE age = 22 AND experience = 3 Such a query is quite simple, a unique index will not allow you to insert duplicates, but due to the large number of records, working with such a table can be very inconvenient.
Three tables

create table kvs_age_range
( `id` integer not null AUTO_INCREMENT, `from` integer not null comment "Начало диапазона", `to` integer not null comment "Окончание диапазона", primary key (id)
) comment 'Диапазоны возраста';
create table kvs_experience_range
( `id` integer not null AUTO_INCREMENT, `from` integer not null comment "Начало диапазона", `to` integer not null comment "Окончание диапазона", primary key (id)
) comment 'Диапазоны стажа';
create table kvs_value
( age_id int not null, experience_id int not null, value decimal(4, 2) null comment 'Значение КВС', constraint kvs_value_age_id_experience_id_uindex unique (age_id, experience_id), constraint kvs_age_id___fk foreign key (age_id) references kvs_age_range (id) on delete cascade, constraint kvs_experience_id___fk foreign key (experience_id) references kvs_experience_range (id)
) comment 'Величина КВС'; Insert data:

The number of records has decreased, but the request to get the SWR value has become more complicated:
SELECT value FROM kvs_value AS v INNER JOIN kvs_age_range AS age ON v.age_id = age.id INNER JOIN kvs_experience_range AS experience ON v.experience_id = experience.id
WHERE (age.`from` <= 22 AND age.`to` >= 22) AND (experience.`from` <= 3 AND experience.`to` >= 3) The query has become much more complicated, there is no duplicate control (you can insert overlapping ranges), it is more difficult to visually work with data because it is required to switch attention between tables.
PostgreSQL base structure
For PostgreSQL, let’s use a schema with one table:

create table if not exists kvs
( age int4range not null, experience int4range not null, value numeric(4, 2), exclude using gist (age WITH &&, experience WITH &&)
);
comment on table kvs is 'Коэффициент Возраст-Стаж';
comment on column kvs.age is 'Диапазоны возраста';
comment on column kvs.value is 'Величина КВС'; (See below for the EXCLUDE USING GIST construct.) Insert data:

Insert range syntax:
INSERT INTO kvs VALUES ('[16,21]', '[0,0]', 1.87) As you can see, in this case, you get 50 entries (they can be reduced to 20, I suggest you think and write in the comments how to do this). Constraint-exclusions
EXCLUDE USING GIST will save us from inserting overlapping ranges by mistake. For example, if we try to add a new coefficient for age 16-30 and experience 5-6 years, we will get an error:

Request for odds looks like:
SELECT value FROM kvs WHERE age @> 22 AND experience @> 3 The request turned out to be simple, the scheme provides control of non-intersection of inserted ranges, it is visually more convenient to work with such a table, because it is similar to the table we received in the TOR.
Database structure for mysql
Two implementation options immediately come to mind:
use of one table, in the rows of which all variants of age-experience-coefficient links are stored;
use of three tables, two of which store ranges (one for age, the other for seniority), and the third contains the age-experience relationship and the value of the coefficient.
Consider both of these options and fill the tables with data. But first, let’s set the boundary conditions. According to Wikipedia, the oldest living inhabitant of the planet, Lucille Randonlet, lived to 118 in 2022 ( List of the oldest people in the world
). Driving license can be obtained from the age of 16. Potentially, Lucille’s driving experience could be 102 years. To fill the database with data, we will proceed from the calculation: age from 16 to 118 years, driving experience from 0 to 102 years.
Now let’s create the necessary tables for both options.
One table
create or replace table kvs
( age int not null comment 'Возраст', experience int not null comment 'Стаж', value decimal(4, 2) not null comment 'Значение КВС', primary key (age, experience)
) comment 'Коэффициент Возраст-Стаж'; Inserting data. As a result, we get 9314 entries:
A composite index on the age-experience fields will save us from erroneous insertion of duplicates in future changes in the coefficient. A request for a coefficient for a driver of 23 years and a driving experience of 3 years in this case will look like:
SELECT value FROM kvs WHERE age = 22 AND experience = 3 Such a query is quite simple, a unique index will not allow you to insert duplicates, but due to the large number of records, working with such a table can be very inconvenient.
Three tables
create table kvs_age_range
( `id` integer not null AUTO_INCREMENT, `from` integer not null comment "Начало диапазона", `to` integer not null comment "Окончание диапазона", primary key (id)
) comment 'Диапазоны возраста';
create table kvs_experience_range
( `id` integer not null AUTO_INCREMENT, `from` integer not null comment "Начало диапазона", `to` integer not null comment "Окончание диапазона", primary key (id)
) comment 'Диапазоны стажа';
create table kvs_value
( age_id int not null, experience_id int not null, value decimal(4, 2) null comment 'Значение КВС', constraint kvs_value_age_id_experience_id_uindex unique (age_id, experience_id), constraint kvs_age_id___fk foreign key (age_id) references kvs_age_range (id) on delete cascade, constraint kvs_experience_id___fk foreign key (experience_id) references kvs_experience_range (id)
) comment 'Величина КВС'; Inserting data:
The number of entries has decreased, but the request to get the SWR value has become more complicated:
SELECT value FROM kvs_value AS v INNER JOIN kvs_age_range AS age ON v.age_id = age.id INNER JOIN kvs_experience_range AS experience ON v.experience_id = experience.id
WHERE (age.`from` <= 22 AND age.`to` >= 22) AND (experience.`from` <= 3 AND experience.`to` >= 3) The query has become much more complicated, there is no duplicate control (you can insert overlapping ranges), visually working with data is more difficult because it is required to switch attention between tables.
Comparison of options
As you can see, when using the range data type, we get the minimum number of rows, a simple query, and control of «non-crossing» of ranges. For greater clarity, I made a pivot table:
I hope that you are convinced of the power of using this mechanism and apply it in your practice. It can be used, for example, in room reservation systems or in scheduling. Please share your experience of using the range data type in the comments. What use cases did you use ranges for?
Coefficient of insurance rates
To begin with, let’s dive into the subject area a little. The calculation scheme is regulated by the document “ Instruction of the Bank of Russia dated September 19, 2014 No. 3384-U
«. When calculating the cost of the policy, a certain amount is taken, called the “Base Rate”, and multiplied by several different coefficients, which can either increase the final cost of the policy or lower it. One of them is the coefficient of insurance rates depending on the age and experience of the driver ( FAC
). Dependence is presented in the table:
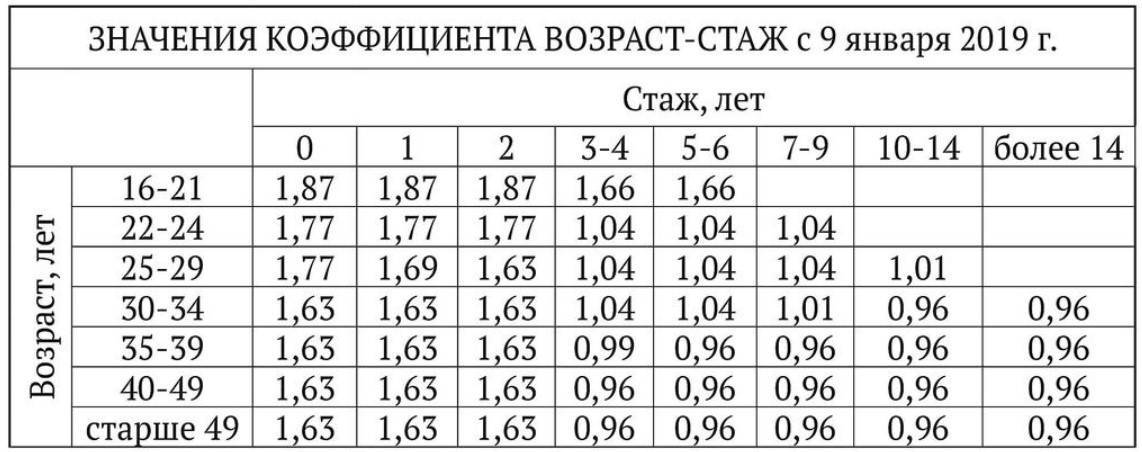
Here we see ranges of numbers according to input criteria (experience and age), which encourages the use of a range data type. But imagine that we have MySQL as the RDBMS and that this type is not available to us. What will the base look like? Let’s design!
Coefficient of insurance rates
To begin with, let’s dive into the subject area a little. The calculation scheme is regulated by the document “ Instruction of the Bank of Russia dated September 19, 2014 No. 3384-U
«. When calculating the cost of the policy, a certain amount is taken, called the “Base Rate”, and multiplied by several different coefficients, which can either increase the final cost of the policy or lower it. One of them is the coefficient of insurance rates depending on the age and experience of the driver ( FAC
). Dependence is presented in the table:
Here we see ranges of numbers according to input criteria (experience and age), which encourages the use of a range data type. But imagine that we have MySQL as the RDBMS and that this type is not available to us. What will the base look like? Let’s design!
Compare options
As you can see, when using the range data type, we get the minimum number of rows, a simple query, and control of «non-crossing» ranges. For greater clarity, I made a pivot table:
I hope that you are convinced of the power of using this mechanism and apply it in your practice. It can be used, for example, in room reservation systems or in scheduling. Please share your experience of using the range data type in the comments. What use cases did you use ranges for?
PostgreSQL base structure
For PostgreSQL, let’s use a schema with one table:
create table if not exists kvs
( age int4range not null, experience int4range not null, value numeric(4, 2), exclude using gist (age WITH &&, experience WITH &&)
);
comment on table kvs is 'Коэффициент Возраст-Стаж';
comment on column kvs.age is 'Диапазоны возраста';
comment on column kvs.value is 'Величина КВС'; (See below for the EXCLUDE USING GIST construct.) Insert data:
Insert range syntax:
INSERT INTO kvs VALUES ('[16,21]', '[0,0]', 1.87) As you can see, in this case there are 50 entries (they can be reduced to 20, I suggest you think and write in the comments how to do this). Restriction-exclusions
EXCLUDE USING GIST will save us from inserting overlapping ranges by mistake. For example, if we try to add a new coefficient for age 16-30 and 5-6 years of experience, we will get an error:
A request for obtaining a coefficient looks like:
SELECT value FROM kvs WHERE age @> 22 AND experience @> 3 The request turned out to be simple, the scheme provides control of non-intersection of the inserted ranges, it is visually more convenient to work with such a table, because it is similar to the table we received in the TOR.
