

- Ловушки из Логсташа
- Мониторинг Logstash
- Что дальше?
- Интеграции
- Удары
- Состояние кластера
- Кластерное состояние
- Статистика кластера
- Статистика узлов
- Информация об узлах
- Незавершенные кластерные задачи
- Управление задачами
- Информация об удаленном кластере
- Исключения конфигурации голосования
- Конфигурации кластера Elasticsearch для производства
- Избегайте «расщепленного мозга»
- Настройка размера кучи JVM
- Отключение подкачки
- Настройка виртуальной памяти
- Увеличение лимита дескрипторов открытых файлов
- Учебное пособие по стеку ELK – Резюме
- ELK в производстве
- Не теряйте данные журнала
- Отслеживание исключений Logstash/Elasticsearch
- Не отставайте от роста и всплесков
- ELK Эластичность
- Кафка
- Бегать в разных зонах доступности (но не в разных регионах)
- Безопасность
- Ремонтопригодность
- Хранение данных
- Улучшения
- Проверка стека ELK
- Что такое ELK Stack
- Что такое Логсташ?
- Конфигурация Логсташа
- Плагины ввода
- Плагины фильтров
- Плагины вывода
- Кодеки Logstash
- Пример конфигурации
- Конфигурация Кибана
- Что нового?
- Установка кластера Elasticsearch
- Установка Java
- Установка узлов Elasticsearch
Ловушки из Логсташа
Как подразумевалось выше, Logstash страдает от некоторых внутренних проблем, связанных с его конструкцией. Logstash требует запуска JVM, и эта зависимость может быть основной причиной значительного потребления памяти, особенно когда задействовано несколько конвейеров и расширенная фильтрация.
Нехватка ресурсов, плохая конфигурация, ненужное использование плагинов, изменения в входящих журналах — все это может привести к проблемам с производительностью, которые, в свою очередь, могут привести к потере данных, особенно если вы не установили систему безопасности.
Существуют различные способы использования этой системы безопасности, как встроенные в Logstash, так и некоторые, которые включают добавление компонентов промежуточного программного обеспечения в ваш стек. Вот список некоторых лучших практик, которые помогут вам избежать некоторых распространенных ловушек Logstash:
Дополнительные подводные камни, на которые следует обратить внимание, см. в статье 5 подводных камней Logstash.
Мониторинг Logstash
Logstash автоматически записывает некоторую информацию и метрики на узле, на котором запущены Logstash, JVM и запущенные конвейеры, которые можно использовать для мониторинга производительности. Чтобы получить доступ к этой информации, вы можете использовать API мониторинга.
Например, вы можете использовать API Hot Threads для просмотра потоков Java с высокой загрузкой ЦП и длительным временем выполнения:
В качестве альтернативы вы можете использовать пользовательский интерфейс мониторинга в Kibana, доступный по базовой лицензии Elastic.
Что дальше?
Logstash — критический элемент в вашем ELK Stack, но вам нужно знать, как использовать его как в качестве отдельного инструмента, так и вместе с другими компонентами в стеке. Ниже приведен список других ресурсов, которые помогут вам использовать Logstash.
Интеграции
Практически любой источник данных можно использовать для отправки данных журнала в стек ELK. Какой метод вы выберете, будет зависеть от ваших требований, конкретной среды, предпочтительного набора инструментов и многого другого.
За последние несколько лет мы написали большое количество статей, описывающих различные способы интеграции стека ELK с различными системами, приложениями и платформами. Метод варьируется от источника данных к источнику данных — это может быть контейнер Docker, Filebeat или другой бит, Logstash и так далее. Просто сделайте свой выбор.
Ниже приведен список этих интеграций на тот случай, если вы планируете их внедрить. Мы постарались разделить их на отдельные категории для более удобной навигации.
Обратите внимание, что большинство из них также содержат инструкции для Logz.io, в том числе готовые информационные панели, которые являются частью нашей библиотеки приложений ELK. Отмечены интеграции с инструкциями по интеграции с ELK Logz.io.
Удары
Elasticsearch поддерживает большое количество специфичных для кластера операций API, которые позволяют вам управлять кластером Elasticsearch и отслеживать его. Большинство API позволяют определить, какой узел Elasticsearch вызывать, используя внутренний идентификатор узла, его имя или адрес.
Ниже приведен список нескольких основных операций API, которые вы можете использовать. Подробнее об использовании кластерных API см. в этом сообщении в блоге
.
Состояние кластера
Этот API можно использовать для просмотра общей информации о кластере и оценки его состояния:
curl -XGET ‘localhost:9200/_cluster/health?pretty’
Кластерное состояние
На этот API можно подать в суд, чтобы просмотреть подробный отчет о состоянии всего вашего кластера. Вы можете отфильтровать результаты, указав параметры в URL-адресе вызова.
curl -XGET ‘localhost:9200/_cluster/state?pretty’
Статистика кластера
Чрезвычайно полезно для мониторинга показателей производительности всего вашего кластера:
curl -XGET ‘localhost:9200/_cluster/stats?human&pretty’
Вы также можете нацеливаться на определенные группы узлов с помощью фильтров узлов.
Статистика узлов
Если вы хотите проверить метрики для определенных узлов в кластере, используйте этот API. Вы можете просмотреть информацию обо всех узлах, определенном узле или попросить просмотреть только статистику по индексу или ОС/процессу.
curl -XGET ‘localhost:9200/_nodes/stats?pretty’
Конкретный узел:
curl -XGET ‘localhost:9200/_nodes/node-1/stats?pretty’
curl -XGET ‘localhost:9200/_nodes/stats/indices?pretty’
curl -XGET ‘localhost:9200/_nodes/stats/ingest?pretty’
curl -XGET ‘localhost:9200/_nodes/stats/ingest,fs?pretty’
Или все показатели в любом из этих двух форматов:
curl -XGET ‘localhost:9200/_nodes/stats/_all?pretty’
curl -XGET ‘localhost:9200/_nodes/stats?metric=_all?pretty’
Информация об узлах
Если вы хотите собрать информацию о каком-либо или всех узлах вашего кластера, используйте этот API.
Получить для одного узла:
curl -XGET ‘localhost:9200/_nodes/?pretty’
Или несколько узлов:
curl -XGET ‘localhost:9200/_nodes/node1,node2?pretty’
Получить данные о плагинах или загрузить:
curl -XGET ‘localhost:9200/_nodes/plugins
curl -XGET ‘localhost:9200/_nodes/ingest
Информация о процессорах загрузки должна выглядеть следующим образом (в примере показано гораздо больше, чем три типа):
Незавершенные кластерные задачи
Этот API отслеживает изменения на уровне кластера, включая, помимо прочего, обновленное сопоставление, неудачное сегментирование и создание индекса.
curl -XGET ‘localhost:9200/_cluster/pending_tasks?pretty’
Управление задачами
Подобно API отложенных кластерных задач, API управления задачами будет получать данные о запущенных в данный момент задачах на соответствующих узлах.
Чтобы получить информацию обо всех выполняемых в данный момент задачах, введите:
curl -XGET «localhost:9200/_tasks
Чтобы получить текущие задачи по конкретным узлам И дополнительно задачи, связанные с кластером, введите имена узлов как таковые, а затем добавьте &actions к GET:
curl -XGET ‘localhost:9200/_tasks?nodes=node1,node2&actions=cluster:*&pretty’
Получить информацию о конкретной задаче (или ее дочерних задачах), введя _tasks/, а затем индивидуальный идентификатор задачи:
curl -XGET ‘localhost:9200/_tasks/43r315an3xamp13’
И для дочерних задач:
curl -XGET ‘localhost:9200/_tasks?parent_task_id=43r315an3xamp13’
Этот API также поддерживает переиндексацию, поиск, группировку задач и отмену задач.
Информация об удаленном кластере
Получить информацию об удаленном кластере с помощью:
curl -XGET ‘localhost:9200/_remote/info?pretty’
Исключения конфигурации голосования
Это удалит главные узлы. Удалите все исключения:
Или добавить узел в список исключений:
Конфигурации кластера Elasticsearch для производства
Мы уже определили различные роли для узлов в нашем кластере, но есть некоторые дополнительные рекомендуемые настройки для кластера, работающего в производственной среде.
Избегайте «расщепленного мозга»
Ситуация «расщепленного мозга» возникает, когда связь между узлами в кластере прерывается либо из-за сбоя сети, либо из-за внутреннего сбоя одного из узлов. В таком сценарии более чем один узел может считать себя главным узлом, что приводит к состоянию несогласованности данных.
Чтобы избежать этой ситуации, мы можем внести изменения в директиву в файле конфигурации Elasticsearch, которая определяет, сколько узлов должно быть в состоянии связи (кворума) для выбора мастера.
В случае кластера с тремя узлами, тогда:
Настройка размера кучи JVM
Чтобы обеспечить Elasticsearch достаточную свободу действий, размер кучи JVM по умолчанию (минимум/максимум 1 ГБ) должен быть скорректирован.
Как показывает практика, максимальный размер кучи должен составлять 50% вашей оперативной памяти, но не более 32 ГБ (из-за неэффективности указателя Java в больших кучах). Elastic также рекомендует, чтобы значения максимального и минимального размера кучи были одинаковыми.
Эти значения можно настроить с помощью настроек Xmx и Xms в
sudo vim /etc/elasticsearch/jvm.options
-Xms2g
-Xmx2g
Отключение подкачки
Выгрузка неиспользуемой памяти — известное поведение, но в контексте Elasticsearch может привести к разрывам соединения, плохой производительности и в целом — нестабильному кластеру.
Чтобы избежать свопинга, вы можете либо отключить все свопинги (рекомендуется, если Elasticsearch — единственная служба, работающая на сервере), либо использовать блокировку процесса Elasticsearch в оперативной памяти.
Для этого откройте конфигурационный файл Elasticsearch на всех нодах кластера:
sudo vim /etc/elasticsearch/elasticsearch.yml
Затем откройте файл /etc/default/elasticsearch:
sudo vim /etc/default/elasticsearch
Перезапустите Elasticsearch, когда закончите.
Настройка виртуальной памяти
Чтобы избежать нехватки виртуальной памяти, увеличьте количество ограничений на количество mmap:
sudo vim /etc/sysctl.conf
Обновите соответствующие настройки соответствующим образом:
В DEB/RPM этот параметр настраивается автоматически.
Увеличение лимита дескрипторов открытых файлов
Другой важной конфигурацией является ограничение дескрипторов открытых файлов. Поскольку Elasticsearch использует большое количество файловых дескрипторов, вы должны убедиться, что установленного лимита достаточно, иначе вы можете потерять данные.
Общая рекомендация для этого параметра — 65 536 и выше. В DEB/RPM параметры по умолчанию уже настроены в соответствии с этим требованием, но вы, конечно, можете их настроить.
sudo vim /etc/security/limits.conf
Установить лимит:
— nofile 65536
Учебное пособие по стеку ELK – Резюме
Стек ELK требует правильной настройки Java 1.8. Я столкнулся с трудностями при запуске этих инструментов из-за более старого JDK в системном пути.
Напишите мне свои вопросы в разделе комментариев.
Счастливого обучения!!
ELK в производстве
Управление журналами стало обязательным действием для любой организации для решения проблем и обеспечения работоспособности приложений. Таким образом, управление журналами стало, по сути, критически важной системой.
Когда вы устраняете производственную проблему или пытаетесь определить угрозу безопасности, система должна работать круглосуточно. В противном случае вы не сможете устранять неполадки или решать возникающие проблемы, что может привести к снижению производительности, простоям или нарушению безопасности. Постоянно работающая система аналитики журналов может предоставить вашей организации средства для отслеживания и обнаружения конкретных проблем, которые наносят ущерб вашей системе.
Вообще говоря, есть несколько основных требований, которым должна отвечать реализация ELK производственного уровня:
Как этого можно достичь?
Не теряйте данные журнала
Если вы устраняете проблему и просматриваете набор событий, достаточно одной отсутствующей строки лога, чтобы получить неправильные результаты. Каждое событие журнала должно быть зафиксировано. Например, вы просматриваете набор событий в MySQL, который заканчивается исключением базы данных. Если вы потеряете одно из этих событий, может быть невозможно точно определить причину проблемы.
Рекомендуемый метод обеспечения отказоустойчивости конвейера данных — разместить перед Logstash буфер, который будет служить точкой входа для всех событий журнала, отправляемых в вашу систему. Затем он будет буферизовать данные до тех пор, пока у нижестоящих компонентов не будет достаточно ресурсов для индексации.
Чаще всего в этом контексте используется буфер Kafka, хотя также используются Redis и RabbitMQ.
Elasticsearch — это ядро ELK. Он очень чувствителен к нагрузке, а это значит, что вам нужно быть предельно осторожным при индексировании и увеличении количества документов. Когда Elasticsearch занят, Logstash работает медленнее, чем обычно, и именно здесь в игру вступает ваш буфер, накапливая больше документов, которые затем можно отправить в Elasticsearch. Это важно, чтобы не потерять события журнала.
При наличии необходимого опыта и времени создание надежного конвейера журналов ELK абсолютно осуществимо — некоторые из крупнейших компаний в мире анализируют свои критически важные данные журналов с помощью ELK. Тем не менее, не все инженерные или ИТ-команды обладают таким опытом или временем, поэтому Logz.io избавляет от времени, опыта и усилий, необходимых для поддержания надежного конвейера ведения журналов, предоставляя высокодоступную платформу для хранения, обработки и анализа журналов. готов к использованию в несколько кликов.
Отслеживание исключений Logstash/Elasticsearch
Logstash может дать сбой при попытке проиндексировать журналы в Elasticsearch, которые не вписываются в автоматически созданное сопоставление.
Например, предположим, что у вас есть запись в журнале, которая выглядит следующим образом:
В первом случае для поля ошибки используется число. Во втором случае используется строка. В результате Elasticsearch НЕ будет индексировать документ — он просто вернет сообщение об ошибке, и журнал будет удален.
Чтобы убедиться, что такие журналы все еще индексируются, вам необходимо:
В Logz.io мы решаем эту проблему, создавая конвейер для обработки исключений сопоставления, который в конечном итоге индексирует эти документы таким образом, который не противоречит существующему сопоставлению.
Не отставайте от роста и всплесков
Как правило, решения для управления журналами потребляют много ресурсов ЦП, памяти и хранилища. Лог-системы по своей природе скачкообразны, и типичны спорадические всплески. Если файл удаляется из вашей базы данных, частота получаемых вами журналов может варьироваться от 100 до 200 и до 100 000 журналов в секунду.
В результате вам необходимо выделить до 10 раз больше мощности, чем обычно. Когда возникает реальная производственная проблема, многие системы обычно сообщают о сбоях или отключениях, из-за чего они создают гораздо больше журналов. Именно в этот момент системы управления журналами нужны как никогда.
ELK Эластичность
Одна из самых больших проблем при развертывании ELK — сделать его масштабируемым.
Допустим, у вас есть сайт электронной коммерции, и вы сталкиваетесь с растущим числом входящих файлов журналов в определенное время года. Чтобы этот приток данных журналов не стал узким местом, необходимо убедиться, что ваша среда легко масштабируется. Это требует масштабирования на всех фронтах — от Redis (или Kafka) до Logstash и Elasticsearch — что сложно во многих отношениях.
Независимо от того, где вы развертываете свой стек ELK — будь то на AWS, GCP или в вашем собственном центре обработки данных — мы рекомендуем иметь кластер узлов Elasticsearch, которые работают в разных зонах доступности или в разных сегментах данных. центр, чтобы обеспечить высокую доступность.
Кафка
Как упоминалось выше, размещение буфера перед вашим механизмом индексации имеет решающее значение для обработки непредвиденных событий. Это могут быть конфликты карт, проблемы с обновлением, проблемы с оборудованием или внезапное увеличение объема журналов. Какой бы ни была причина, вам нужен механизм переполнения, и здесь на сцену выходит Кафка.
Действуя как буфер для журналов, которые должны быть проиндексированы, Kafka должна сохранять ваши журналы как минимум в 2 репликах и хранить ваши данные (даже если они уже были использованы Logstash) в течение как минимум 1-2 дней. .
Это противоречит планированию локального хранилища, доступного для Kafka, а также пропускной способности сети, предоставляемой брокерам Kafka. Не забывайте учитывать огромные всплески входящего трафика журналов (в десятки раз больше, чем «нормальный»), так как это те случаи, когда ваши журналы понадобятся вам больше всего.
Подумайте, сколько рабочей силы вам придется выделить для устранения проблем в вашей инфраструктуре при планировании емкости хранения в Kafka.
Еще одно важное соображение касается кластера управления ZooKeeper — у него есть свои требования. Не забывайте о требованиях к производительности диска для ZooKeeper, а также о доступности этого кластера. Используйте кластер из трех или пяти узлов, распределенный по стойкам/зонам доступности (но не по регионам).
Kafka также предоставляет множество операционных показателей, некоторые из которых чрезвычайно важны для мониторинга: пропускная способность сети, процент простоя потоков, недостаточно реплицированные разделы и многое другое. При рассмотрении потребления из Kafka и индексации вы должны учитывать, какой уровень параллелизма вам нужно реализовать (в конце концов, Logstash не очень быстр). Это важно для понимания парадигмы потребления и соответствующего планирования количества разделов, которые вы используете в своих темах Kafka.
Знание того, сколько экземпляров Logstash нужно запускать, само по себе является искусством, и ответ зависит от множества факторов: объема данных, количества конвейеров, размера вашего кластера Elasticsearch, размера буфера, допустимой задержки и т. д. немного.
Разверните масштабируемый механизм очередей с различными масштабируемыми работниками. Когда очередь слишком занята, масштабируйте дополнительных рабочих операций для чтения в Elasticsearch.
Определив необходимое количество экземпляров Logstash, запустите каждый из них в разных зонах доступности (на AWS). Это обходится дорого из-за передачи данных, но гарантирует более отказоустойчивый конвейер данных.
Вам также следует разделить Logstash и Elasticsearch, используя для них разные машины. Это очень важно, потому что они оба работают как JVM и потребляют большой объем памяти, что делает их невозможными для эффективной работы на одном компьютере.
Спецификации оборудования различаются, но рекомендуется выделять для Logstash максимум 30 ГБ или половину памяти на каждой машине. Однако в некоторых сценариях также рекомендуется освободить место для кэшей и буферов.
Мы рекомендуем построить кластер Elasticsearch, состоящий как минимум из трех мастер-узлов из-за частого возникновения разделения мозга, которое, по сути, является спором между двумя узлами относительно того, какой из них на самом деле является мастером.
Что касается узлов данных, мы рекомендуем иметь как минимум два узла данных, чтобы ваши данные реплицировались хотя бы один раз. В результате получается как минимум пять узлов: три главных узла могут быть небольшими машинами, а два узла данных необходимо масштабировать на солидных машинах с очень быстрым хранилищем и большим объемом памяти.
Бегать в разных зонах доступности (но не в разных регионах)
Мы рекомендуем, чтобы ваши узлы Elasticsearch работали в разных зонах доступности или в разных сегментах центра обработки данных, чтобы обеспечить высокую доступность. Это можно сделать с помощью параметра Elasticsearch, который позволяет настроить репликацию каждого документа между разными зонами доступности. Как и в случае с Logstash, итоговые затраты на такое развертывание могут быть довольно высокими из-за передачи данных.
Безопасность
Из-за того, что журналы могут содержать конфиденциальные данные, крайне важно защитить, кто что может видеть. Как вы можете ограничить доступ к определенным информационным панелям, визуализациям или данным внутри вашей платформы аналитики журналов? В стеке ELK нет простого способа сделать это.
Компания Elastic недавно объявила о том, что некоторые функции безопасности станут бесплатными, в т.ч. шифрование, доступ на основе ролей и аутентификация. Однако более продвинутые конфигурации безопасности и интеграции, например. L Поддержка DAP/AD, SSO, шифрование при хранении недоступны по умолчанию.
Другим вариантом является SearchGuard, который предоставляет бесплатный подключаемый модуль безопасности для Elasticsearch, включая управление доступом на основе ролей и зашифрованную связь между узлами SSL/TLS. Также стоит упомянуть OpenSearch, который поставляется с подключаемым модулем безопасности с открытым исходным кодом с аналогичными возможностями.
И последнее, но не менее важное: будьте осторожны при раскрытии конечных точек Elasticsearch, чтобы избежать утечки данных. Есть несколько основных шагов, которые помогут вам защитить ваши экземпляры Elasticsearch.
Ремонтопригодность
Logstash обрабатывает и анализирует журналы в соответствии с набором правил, определенных подключаемыми фильтрами. Поэтому, если у вас есть журнал доступа из nginx, вам нужна возможность просматривать каждое поле и создавать визуализации и информационные панели на основе определенных полей. Вам необходимо применить соответствующие возможности синтаксического анализа к Logstash, что оказалось довольно сложной задачей, особенно когда речь идет о создании groks, их отладке и фактическом анализе журналов, чтобы иметь соответствующие поля для Elasticsearch и Kibana.
В конце концов, при использовании Logstash очень легко допустить ошибку, поэтому вам следует тщательно тестировать и поддерживать все конфигурации вашего журнала с помощью контроля версий. Таким образом, хотя вы можете начать использовать nginx и MySQL, вы можете добавлять собственные приложения по мере роста, что приводит к большим и сложным в управлении файлам журналов. Сообщество разработало множество решений по этой теме, но метод проб и ошибок чрезвычайно важен для самоуправляемых инструментов, прежде чем использовать их в рабочей среде.
Синтаксический анализ данных журнала имеет решающее значение для обеспечения возможности поиска по журналу и визуализации, но сделать это правильно может быть сложно. Если вы не хотите полностью заниматься синтаксическим анализом своих журналов, вы можете использовать синтаксический анализ как услугу Logz.io, где один из наших инженеров службы поддержки просто проанализирует ваши журналы для вас.
Хранение данных
Другой аспект ремонтопригодности вступает в игру с избыточными индексами. В зависимости от того, как долго вы хотите хранить данные, вам нужно настроить процесс, который будет автоматически удалять старые индексы — в противном случае у вас останется слишком много данных, и ваш Elasticsearch выйдет из строя, что приведет к потере данных.
Чтобы этого не произошло, вы можете использовать Elasticsearch Curator для удаления индексов. Мы рекомендуем иметь задание cron, которое автоматически порождает Curator с соответствующими параметрами для удаления любых старых индексов, гарантируя, что вы не держите слишком много данных. Обычно требуется сохранять журналы в S3 в корзине для соответствия требованиям, поэтому вы должны быть уверены, что у вас есть копии журналов в их исходном формате.
Улучшения
Основные версии стека выпускаются довольно часто, с отличными новыми функциями, но также и критическими изменениями. Всегда полезно прочитать и изучить, что эти изменения означают для вашей среды, прежде чем приступать к обновлению. Последнее не всегда лучшее!
Выполнение обновлений Elasticsearch может быть довольно трудоемким, но также стало более безопасным из-за некоторых недавних изменений. Прежде всего, вам нужно убедиться, что вы не потеряете данные в результате этого процесса. Сначала запустите тесты в непроизводственной среде. В зависимости от того, с какой версии и до какой вы выполняете обновление, убедитесь, что вы понимаете процесс и его последствия.
Обновления Logstash, как правило, проще, но обратите особое внимание на совместимость между Logstash и Elasticsearch и критические изменения.
Обновления Kibana могут быть проблематичными, особенно если вы используете более старую версию. Импорт объектов «обычно» поддерживается, но вам следует сделать резервную копию ваших объектов и протестировать процесс обновления перед обновлением в рабочей среде. Как всегда — изучайте критические изменения!
Для некоторых время, усилия и опыт, необходимые для запуска промышленной системы ELK в масштабе, не являются проблемой — некоторые из крупнейших компаний в мире используют ELK. Но для других это время, которое лучше потратить в другом месте.
Если ваша команда не может позволить себе тратить часы на разработку, управление кластерами Elasticsearch, настройку для устранения проблем с производительностью, обновление и внедрение политик безопасности, лучше использовать управляемую службу ведения журналов, основанную на стеке с открытым исходным кодом. . Все зависит от ваших предпочтений по распределению ресурсов.
Проверка стека ELK
Теперь, когда все компоненты настроены и работают, давайте проверим всю экосистему.
Зайдите в приложение и пару раз проверьте конечные точки, чтобы журналы были сгенерированы, а затем перейдите в консоль Kibana и убедитесь, что журналы правильно сложены в Kibana с множеством дополнительных функций, таких как фильтрация, просмотр различных графиков и т. д. в построен.
Вот вид сгенерированных логов в Kibana.
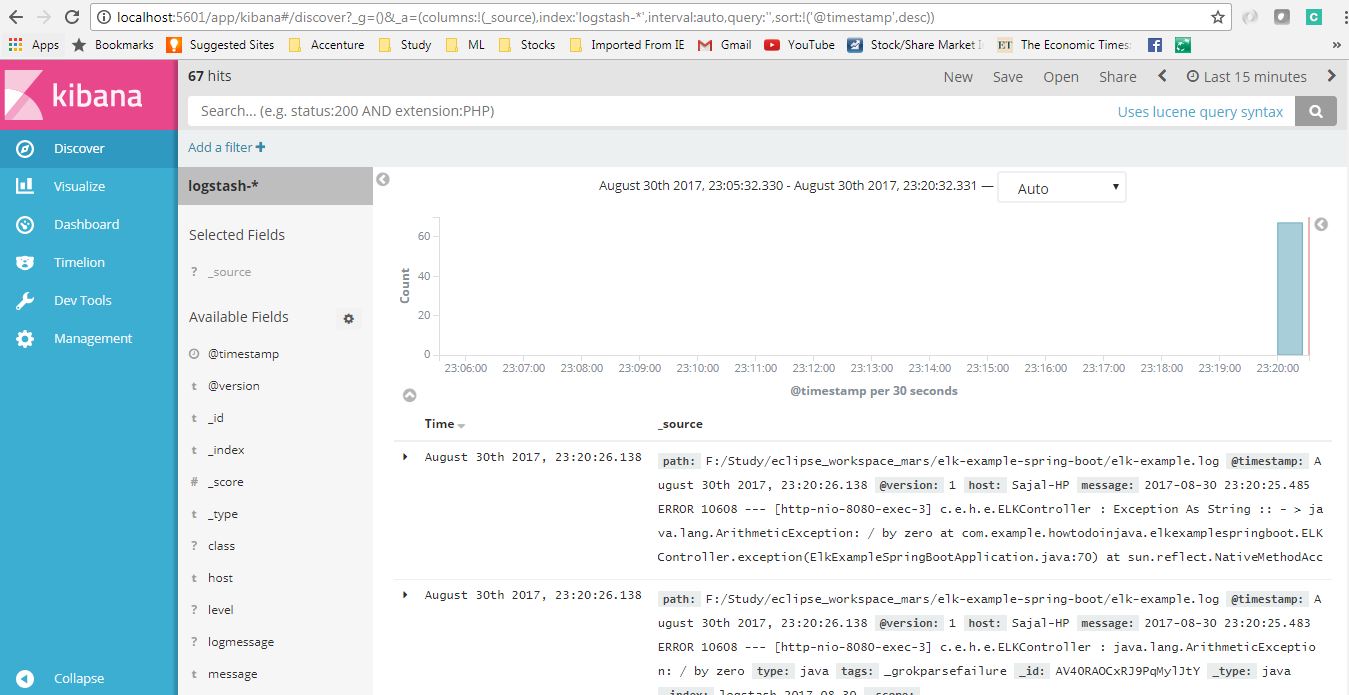
Обзор журналов Kibana
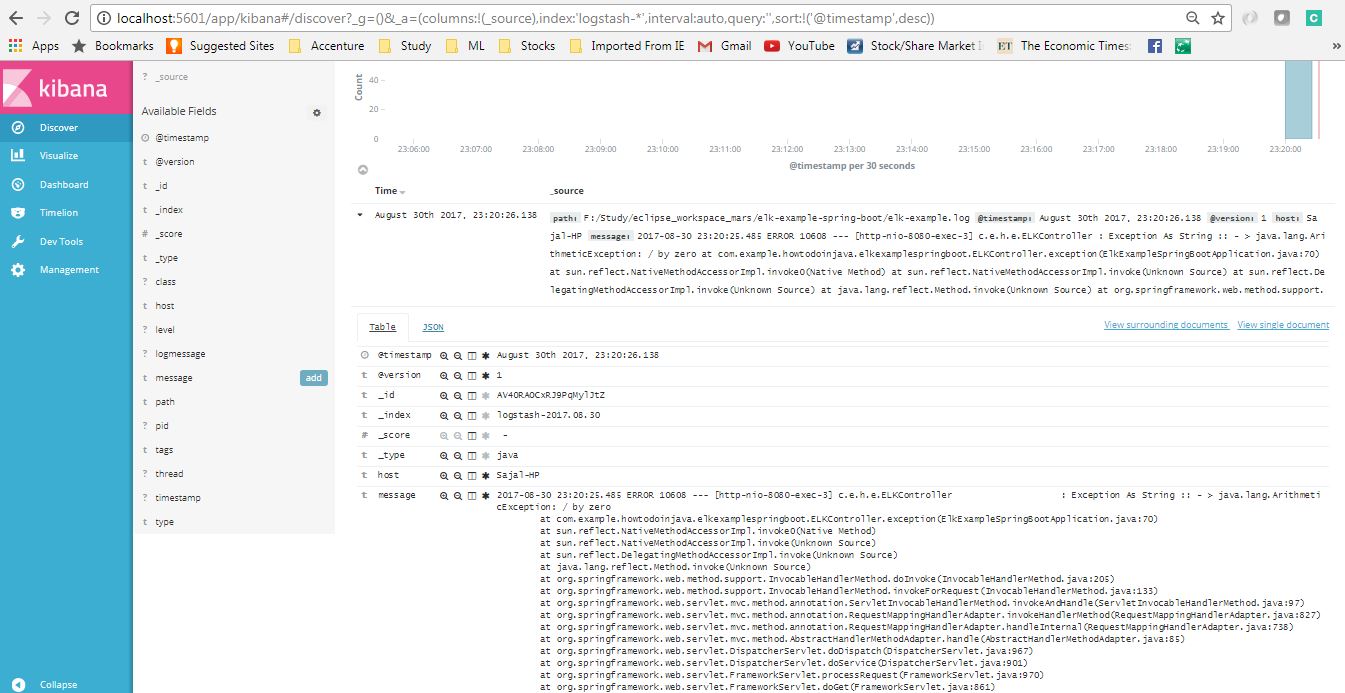
Экран сведений Kibana Logs
Что такое ELK Stack
Logstash обрабатывает файлы журналов приложений на основе установленных нами критериев фильтрации и отправляет эти журналы в Elasticsearch. С помощью Kibana мы просматриваем и анализируем эти журналы, когда это необходимо.
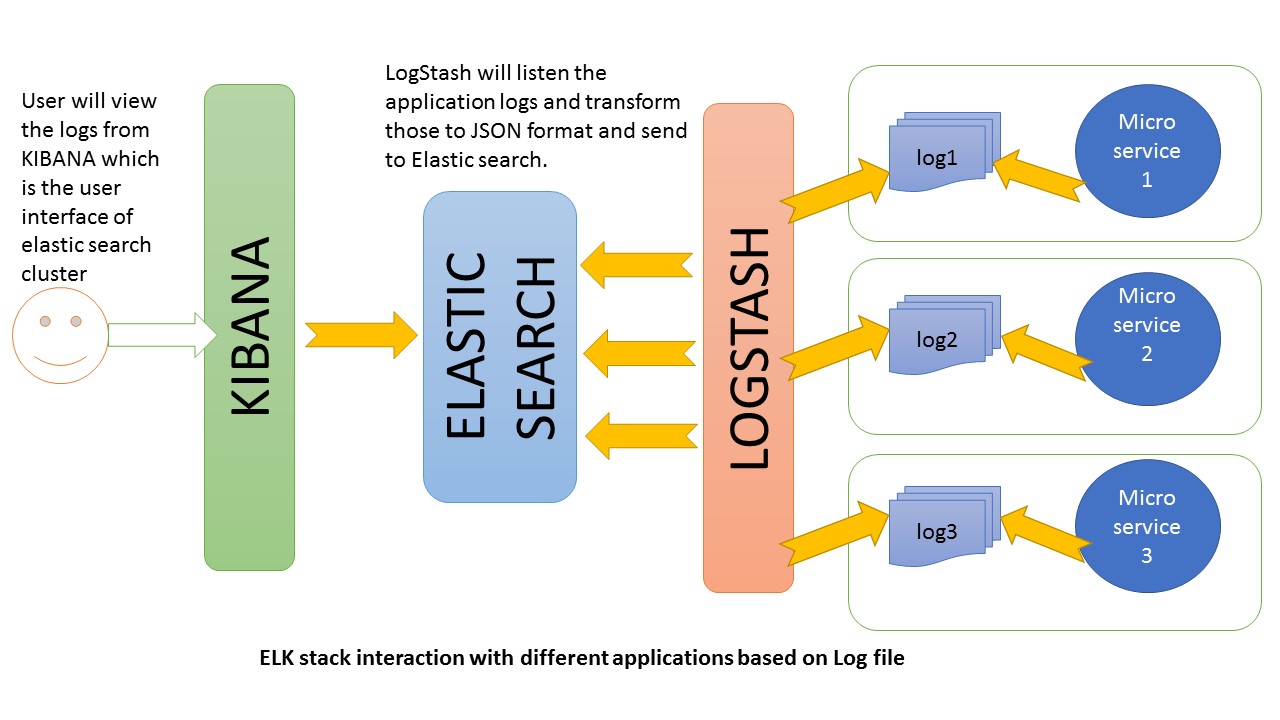
ЛОСЬ в действии
Эффективный анализ журналов основан на хорошо структурированных журналах. Структура — это то, что позволяет вам легче искать, анализировать и визуализировать данные в любом инструменте регистрации, который вы используете. Структура также дает контекст вашим данным. Если возможно, эту структуру необходимо адаптировать к журналам на уровне приложения. В других случаях, например, для журналов инфраструктуры и системы, вы сами определяете структуру журналов, анализируя их.
Logstash можно использовать для придания вашим журналам такой структуры, чтобы их было легче искать и визуализировать.
К сожалению, Logstash часто ломается и оставляет большой компьютерный след. По этим причинам многие современные развертывания ELK на самом деле являются развертываниями EFK, заменяя Logstash облегченными альтернативами, такими как Fluentd или FluentBit.
В Logz.io наш инструмент управления журналами использует проект с открытым исходным кодом под названием Sawmill для обработки журналов, а не для обслуживания Logstash. Для распространенных типов журналов данные анализируются автоматически. Для менее распространенных журналов вы можете обратиться к нашему инженеру службы поддержки через чат приложения, и они проанализируют ваши журналы за считанные минуты!
Что такое Логсташ?
В стеке ELK (Elasticsearch, Logstash и Kibana) решающая задача анализа данных возложена на «L» в стеке — Logstash.
Logstash начинался как инструмент с открытым исходным кодом, разработанный для обработки потоковой передачи большого количества данных журнала из нескольких источников. После того, как он был включен в стек ELK, он превратился в рабочую лошадку стека, отвечающую также за обработку сообщений журнала, их улучшение и массирование, а затем отправку их в определенное место для хранения (сохранение).
Благодаря большой экосистеме плагинов Logstash можно использовать для сбора, обогащения и преобразования широкого спектра данных различных типов. Существует более 200 различных плагинов для Logstash, и обширное сообщество использует его расширяемые функции.
Тем не менее, несмотря на эти недостатки, Logstash по-прежнему остается важным компонентом стека. Были предприняты большие шаги, чтобы попытаться облегчить эти проблемы, внедрив улучшения в сам Logstash, такие как совершенно новый механизм выполнения, доступный в версии 7.0, что в конечном итоге помогло сделать ведение журнала с помощью ELK намного более надежным, чем раньше.
Конфигурация Логсташа
События, собираемые и обрабатываемые Logstash, проходят три этапа: сбор, обработка и отправка. Какие данные собираются, как они обрабатываются и куда отправляются, определяется в файле конфигурации Logstash, который определяет конвейер.
Каждый из этих этапов определяется в файле конфигурации Logstash с помощью так называемых плагинов — плагинов «Ввод» для этапа сбора данных, плагинов «Фильтр» для этапа обработки и плагинов «Вывод» для этапа диспетчеризации. Плагины ввода и вывода поддерживают кодеки, которые позволяют вам кодировать или декодировать ваши данные (например, json, многострочный, простой).
Плагины ввода
Одна из вещей, которая делает Logstash таким мощным, — это его способность объединять журналы и события из различных источников. Используя более 50 подключаемых модулей ввода для различных платформ, баз данных и приложений, Logstash можно настроить для сбора и обработки данных из этих источников и отправки их в другие системы для хранения и анализа.
Наиболее часто используемые входные данные: файл, beats, syslog, http, tcp, udp, stdin, но вы можете получать данные из множества других источников.
Плагины фильтров
Logstash поддерживает ряд чрезвычайно мощных подключаемых модулей фильтров, которые позволяют вам обогащать журналы, манипулировать ими и обрабатывать их. Именно сила этих фильтров делает Logstash очень универсальным и ценным инструментом для анализа данных журналов.
Фильтры можно комбинировать с условными операторами для выполнения действия, если выполняется определенный критерий.
Плагины вывода
Как и в случае ввода, Logstash поддерживает ряд подключаемых модулей вывода, которые позволяют вам передавать данные в различные места, службы и технологии. Вы можете сохранять события, используя выходные данные, такие как File, CSV и S3, преобразовывать их в сообщения с помощью RabbitMQ и SQS или отправлять их в различные службы, такие как HipChat, PagerDuty или IRC. Количество комбинаций входов и выходов в Logstash делает его действительно универсальным преобразователем событий.
События Logstash могут поступать из нескольких источников, поэтому важно проверить, должно ли событие обрабатываться конкретным выходом. Если вы не определите вывод, Logstash автоматически создаст вывод stdout. Событие может проходить через несколько плагинов вывода.
Кодеки Logstash
Кодеки могут использоваться как на входе, так и на выходе. Входные кодеки обеспечивают удобный способ декодирования данных перед их поступлением на вход. Выходные кодеки обеспечивают удобный способ кодирования данных до того, как они покинут вывод.
Некоторые распространенные кодеки:
Пример конфигурации
Logstash имеет простую конфигурацию DSL, которая позволяет вам указать входы, выходы и фильтры, описанные выше, вместе с их конкретными параметрами. Порядок имеет значение, особенно в отношении фильтров и выходов, поскольку конфигурация в основном преобразуется в код, а затем выполняется. Помните об этом, когда будете писать свои конфиги и пытаться их отлаживать.
Раздел ввода в файле конфигурации определяет используемый плагин ввода. Каждый плагин имеет свои собственные параметры конфигурации, которые вы должны изучить перед использованием.
Здесь мы используем плагин для ввода файлов. Мы ввели путь к файлу, который хотим собрать, и определили начальную позицию как начало обработки логов с начала файла.
Раздел filter в файле конфигурации определяет, какие плагины фильтров мы хотим использовать, или, другими словами, какую обработку мы хотим применить к журналам. Каждый плагин имеет свои собственные параметры конфигурации, которые вы должны изучить перед использованием.
В этом примере мы обрабатываем журналы доступа Apache:
Конфигурация Кибана
Прежде чем просматривать журналы в Kibana, нам нужно настроить шаблоны индексов. Мы можем настроить logstash-* как конфигурацию по умолчанию. Мы всегда можем изменить этот шаблон индекса на стороне logstash и настроить в Kibana. Для простоты мы будем работать с конфигурацией по умолчанию.
Страница управления шаблоном индекса будет выглядеть так, как показано ниже. В этой конфигурации мы указываем Kibana на индекс(ы) Elasticsearch по вашему выбору. Logstash создает индексы с шаблоном имени logstash-YYYY. мм. DD Мы можем выполнить все эти настройки в консоли Kibana http://localhost:5601/app/kibana и перейти по ссылке «Управление» на левой панели.
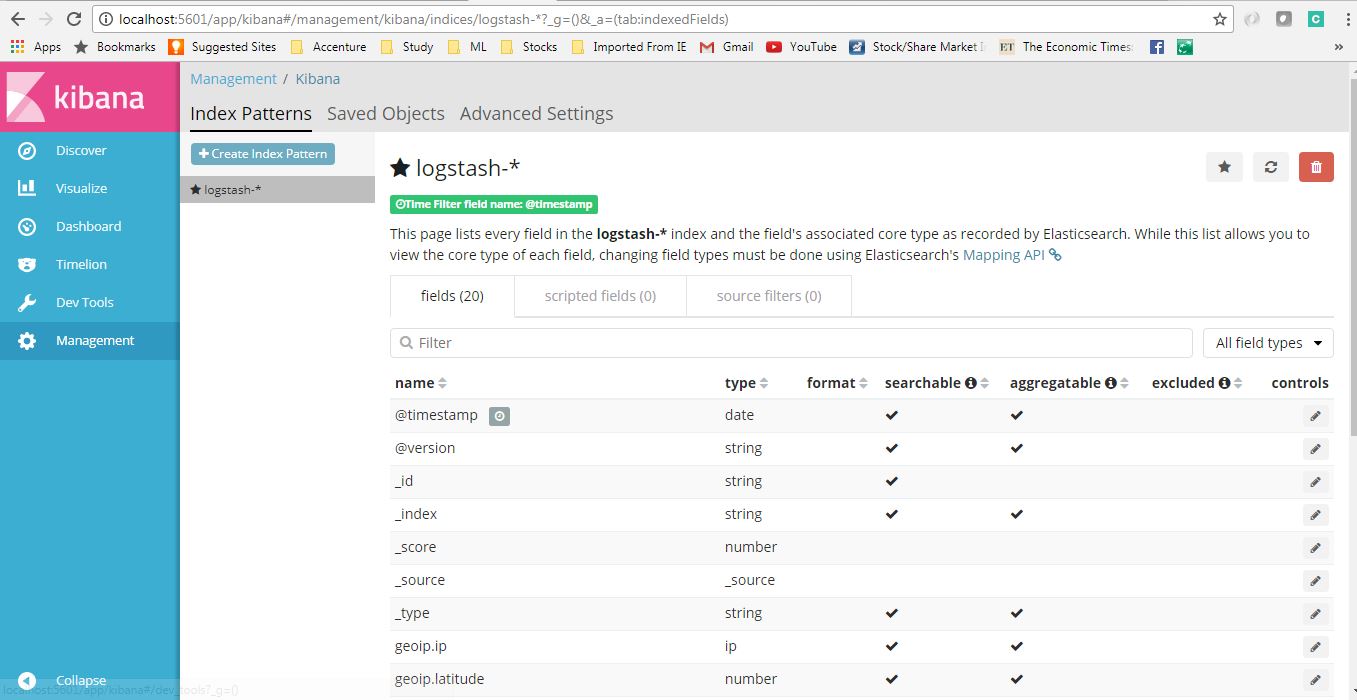
Конфигурация Logstash в Kibana
Что нового?
Как и следовало ожидать от чрезвычайно популярного набора инструментов, стек ELK постоянно и часто обновляется новыми функциями. Быть в курсе этих изменений непросто, поэтому в этом разделе мы расскажем о новых функциях, представленных в основных выпусках.
Elasticsearch 7.x намного проще в настройке, так как теперь он поставляется вместе с Java. Улучшения производительности включают настоящий прерыватель цепи памяти, улучшенную производительность поиска и политику 1-shard. Кроме того, новый уровень координации кластера делает Elasticsearch более масштабируемым и устойчивым.
Версии Elasticsearch 8.x, которые не являются открытым исходным кодом, включают такие усовершенствования, как оптимизация индексов для данных временных рядов и включение функций безопасности по умолчанию.
Механизм исполнения Logstash Java (объявленный экспериментальным в версии 6.3) включен по умолчанию в версии 7.x. Заменяя старый исполнительный механизм Ruby, он может похвастаться более высокой производительностью, меньшим использованием памяти и в целом — более быстрой работой.
Kibana претерпевает серьезные изменения с новыми страницами и улучшениями удобства использования. Последний выпуск включает темный режим, улучшенные запросы и фильтрацию, а также улучшения Canvas.
Beats 7.x соответствуют новой Elastic Common Schema (ECS) — новому стандарту форматирования полей. Metricbeat поддерживает новый модуль AWS для извлечения данных из Amazon CloudWatch, Kinesis и SQS. Новые модули также были представлены в Filebeat и Auditbeat.
Когда Elastic закрыл исходный код стека ELK, они также незаметно запретили Beats отправлять данные в:
Установка кластера Elasticsearch
Как всегда, существует несколько способов настройки кластера Elasticsearch. Вы можете использовать инструмент управления конфигурацией, такой как Puppet или Ansible, для автоматизации процесса. Однако в этом случае мы покажем вам, как вручную настроить кластер, состоящий из одного главного узла и двух узлов данных, все в экземплярах Ubuntu 16.04 на AWS EC2, работающих в одном и том же VPC. Группа безопасности была настроена на доступ из любого места с использованием SSH и TCP 5601 (Kibana).
Установка Java
Elasticsearch построен на Java, и для его запуска требуется как минимум Java 8 (1.8.0_131 или более поздняя версия). Поэтому наш первый шаг — установить Java 8 на все узлы в кластере. Обратите внимание, что на всех узлах Elasticsearch в кластере должна быть установлена одна и та же версия.
Сначала обновите свою систему:
обновление sudo apt-get
Затем установите Java с помощью:
sudo apt-get install default-jre
версия openjdk «1.8.0_151»
Среда выполнения OpenJDK (сборка 1.8.0_151-8u151-b12-0ubuntu0.16.04.2-b12)
64-битная виртуальная машина сервера OpenJDK (сборка 25.151-b12, смешанный режим)
Установка узлов Elasticsearch
Наш следующий шаг — установить Elasticsearch. Как и прежде, повторите шаги, описанные в этом разделе, на всех ваших серверах.
Во-первых, вам нужно добавить ключ подписи Elastic, чтобы можно было проверить загруженный пакет (пропустите этот шаг, если вы уже установили пакеты из Elastic):
Для Debian нам нужно установить
sudo apt-get install apt-transport-https
Следующим шагом будет добавление определения репозитория в вашу систему:
Осталось обновить репозитории и установить Elasticsearch:
обновление sudo apt-get
sudo apt-get установить elasticsearch
