

Работа с базами данных в . NET Framework — SQL Server 2012 — Выполнение SQL-запросов в Management Studio
Исходники баз данных
Среда SQL Server Management Studio предоставляет завершенное средство для создания всех типов запросов. С ее помощью можно создавать, сохранять, загружать и редактировать запросы. Кроме этого, над запросами можно работать без подключения к какому-либо серверу. Этот инструмент также предоставляет возможность разрабатывать запросы для разных проектов.
Предоставляется возможность работать с запросами как посредством редактора запросов, так и с помощью обозревателя решений. В этой статье рассматриваются оба эти инструмента. Кроме этих двух компонентов среды SQL Server Management Studio мы рассмотрим отладку SQL-кода, используя встроенный отладчик.
- Редактор запросов
- Обозреватель решений
- Отладка SQL Server
- Структура базы данных
- Базовые запросы SQL
- Ключевые слова в SQL
- CREATE TABLE
- ALTER TABLE
- INSERT
- SELECT
- WHERE
- Операторы AND, OR, BETWEEN в SQL
- ORDER BY
- GROUP BY
- LIMIT
- UPDATE
- DELETE
- DROP COLUMN
- DROP TABLE
- Итоги
- Зачем мне изучать SQL, если я занимаюсь данными?
- Обработка и выполнение SQL-запросов
- Получайте только нужные данные
- Ограничьте свои результаты
- Пишите запросы как можно проще
- База данных сотрудников
- Влияние ORDER BY на план выполнения запроса
- GROUP BY и HAVING
- Добавим выражение HAVING
- Новый оператор — JOIN
Редактор запросов
Чтобы открыть панель редактора запросов Query Editor (Редактор запросов), на панели инструментов среды SQL Server Management Studio нажмите кнопку New Query (Создать запрос). Эту панель можно расширить, чтобы отображать кнопки создания всех возможных запросов, а не только запросов компонента Database Engine. По умолчанию создается новый запрос компонента Database Engine, но, нажав соответствующую кнопку на панели инструментов, можно также создавать запросы MDX, XMLA и др.
Строка состояния внизу панели редактора запросов указывает статус подключения редактора к серверу. Если подключение к серверу не выполнено автоматически, при запуске редактора запросов выводится диалоговое окно подключения к серверу, в котором можно выбрать сервер для подключения и режим проверки подлинности.
Редактор запросов можно использовать для выполнения следующих задач:
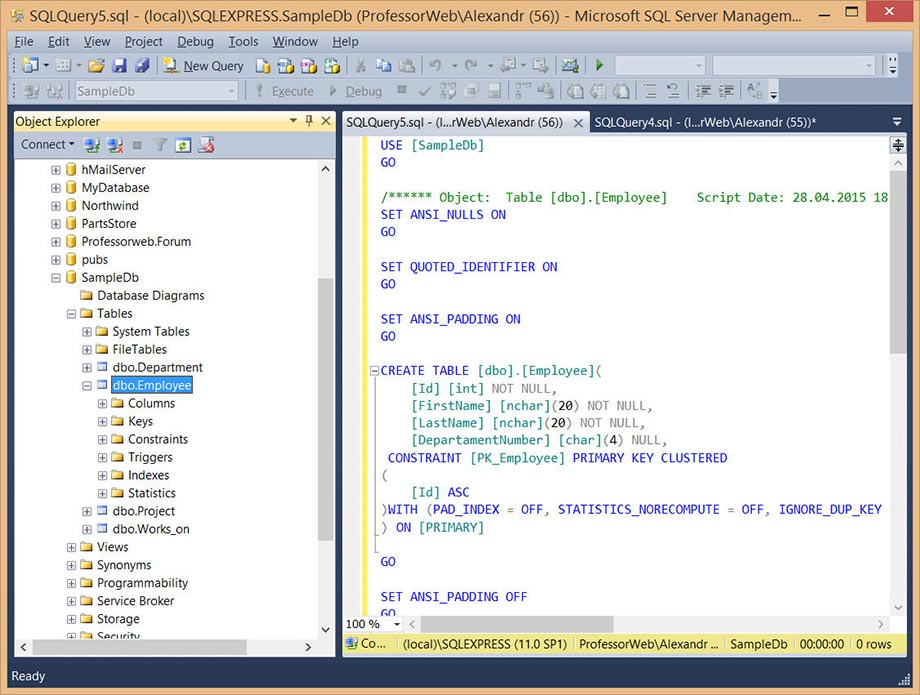
Редактор запросов содержит встроенный текстовый редактор и панель инструментов с набором кнопок для разных действий. Главное окно редактора запросов разделено по горизонтали на панель запросов (вверху) и панель результатов (внизу). Инструкции Transact-SQL (т.е. запросы) для исполнения вводятся в верхнюю панель, а результаты обработки системой этих запросов отображаются в нижней панели. На рисунке ниже показан пример ввода запроса в редактор запросов и результатов выполнения этого запроса:

В первой инструкции запроса USE указывается использовать базу данных SampleDb в качестве текущей базы данных. Вторая инструкция — SELECT — извлекает все строки таблицы Employee. Чтобы выполнить этот запрос и вывести результаты, в панели инструментов редактора запросов нажмите кнопку Execute (Выполнить) или клавишу F5.
Можно открыть несколько окон редактора запросов, т.е. выполнить несколько подключений к одному или нескольким экземплярам компонента Database Engine. Новое подключение создается нажатием кнопки New Query в панели инструментов среды SQL Server Management Studio.
В строке состояния внизу окна редактора запросов отображается следующая информация, связанная с выполнением инструкций запроса:
Кроме этого, редактор запросов оснащен контекстно-зависимой справкой, называющейся Dynamic Help, посредством которой можно получить сведения о конкретной инструкции. Если вы не знаете синтаксиса инструкции, выделите ее в редакторе, а потом нажмите клавишу F1. Также можно выделить параметры различных инструкций Transact-SQL, чтобы получить справку по ним из электронной документации.
В SQL Management Studio поддерживается инструмент SQL Intellisense, который является видом средства автозавершения. Иными словами, этот модуль предлагает наиболее вероятное завершение частично введенных элементов инструкций Transact-SQL.
Обозреватель решений
Для каждого созданного проекта в обозревателе решений отображаются папки Connections (Соединения), Queries (Запросы) и Miscellaneous (Разное). Чтобы открыть новое окно редактора запросов для данного проекта, щелкните правой кнопкой его папку Queries и в контекстном меню выберите пункт New Query.
Отладка SQL Server
На рисунке ниже показан пакет, который подсчитывает количество сотрудников, работающих над проектом p1. Если это количество равно 4 или больше, то выводится соответствующее сообщение. В противном случае выводятся имена и фамилии сотрудников.

Информация, связанная с процессом отладки, отображается в двух панелях внизу окна редактора запросов. Информация о разных типах информации об отладке сгруппирована в этих панелях на нескольких вкладках. Левая панель содержит вкладку Autos (Автоматические), Locals (Локальные) и до пяти вкладок Watch (Видимые). Правая панель содержит вкладки Call Stack (Стек вызовов), Threads (Потоки), Breakpoints (Точки останова), Command Window (Окно команд), Immediate Window (Окно интерпретации) и Output (Вывод). На вкладке Locals отображаются значения переменных, на вкладке Call Stack — значения стека вызовов, а на вкладки Breakpoints — информация о точках останова.
В SQL Server 2012 функциональность встроенного в SQL Server Management Studio отладчика расширена несколькими новыми возможностями. Теперь в нем можно выполнять ряд следующих операций:
В этой статье мы рассмотрим некоторые базовые запросы SQL, с изучения которых стоит начинать новичкам в этом языке. Вы научитесь создавать базу данных и таблицы, вносить в них данные и делать выборки нужных сведений.

Аббревиатура SQL расшифровывается как «Structured Query Language» — язык структурированных запросов. С помощью этого языка вы можете работать с записями в базах данных.
SQL состоит из команд и декларативных ключевых слов, которые являются как бы инструкциями для базы данных.
При помощи команд SQL можно создавать и удалять таблицы в базах данных, добавлять в них данные или вносить изменения, искать и быстро находить нужные сведения.
В этой статье мы рассмотрим основные ключевые слова и операторы SQL и разберем, как с их помощью запрашивать конкретную информацию из базы данных.
Структура базы данных
Прежде чем мы начнем разбирать запросы, нужно, чтобы вы поняли иерархию базы данных.
База данных SQL — это набор взаимосвязанных сведений, хранящихся в таблицах. В каждой таблице есть столбцы, описывающие хранящиеся в них данные, и строки, в которых эти данные хранятся. Поле — это отдельный кусочек данных в строке. Чтобы найти нужные данные, мы должны написать, что именно мы хотим получить.
Возьмем для примера некую компанию, штат которой разбросан по всему миру. Допустим, у этой компании есть много баз данных. Чтобы увидеть их полный список, нужно набрать SHOW DATABASES;
Результат может выглядеть как-то так:
В каждой отдельной базе данных может быть много таблиц. Чтобы увидеть, какие таблицы есть в базе данных employees из нашего примера, нужно набрать SHOW TABLES in employees;. В таблицах могут содержаться данные по разным командам, что отражается в названиях: engineering, product, marketing, sales.
Все таблицы состоят из различных столбцов, описывающих данные.
Чтобы просмотреть столбцы таблицы Engineering, используйте Describe Engineering; Каждый столбец этой таблицы может описывать какой-то один атрибут сотрудника, например: employee_id, first_name, last_name, email, country и salary.
Таблицы также состоят из строк — отдельных записей. В нашем примере в строках будут указаны id, имена, фамилии, email, зарплата и страны проживания сотрудников. Каждая строка будет касаться одного сотрудника, допустим, из команды Engineering.
Базовые запросы SQL
Все операции, которые можно осуществлять с данными, входят в понятие «CRUD».
CRUD расшифровывается как Create, Read, Update и Delete (создать, прочесть, обновить, удалить). Это четыре основных операции, которые мы осуществляем, делая запросы к базе данных.
Мы создаем информацию в базе (CREATE), мы читаем, получаем информацию из базы (READ), мы обновляем данные или осуществляем какие-то манипуляции с ними (UPDATE) и, при желании, можем удалять данные (DELETE).
Для осуществления различных операций с данными в SQL есть специальные ключевые слова (операторы). Ниже мы рассмотрим некоторые простые запросы SQL и их синтаксис.
Ключевые слова в SQL
Для создания базы данных с именем engineering мы используем следующий код:
CREATE DATABASE engineering;
CREATE TABLE
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype
);
Этот запрос создает новую таблицу в базе данных.
В нем задается имя таблицы, а также имена столбцов, которые нам нужны.
Что касается типов данных (datatype), они могут быть разными. Самые распространенные — INT, DECIMAL, DATETIME, VARCHAR, NVARCHAR, FLOAT и BIT.
В нашем примере запрос может быть таким:
CREATE TABLE engineering (
employee_id int
NOT NULL,
first_name varchar
NOT NULL,
last_name varchar
NOT NULL,
email varchar(255) NOT NULL,
country varchar
,
salary decimal(10,2) NOT NULL
);
Таблица, созданная по этому запросу, будет выглядеть так:
ALTER TABLE
После создания таблицы мы можем изменять ее путем добавления столбцов.
ALTER TABLE table_name
ADD column_name datatype;
Допустим, мы хотим добавить в только что созданную таблицу столбец с днями рождения сотрудников. Это можно сделать так:
ALTER TABLE engineering
ADD birthday date;
Теперь таблица выглядит немного иначе:
INSERT
Это ключевое слово служит для вставки данных в таблицы и создания новых строк. В аббревиатуре CRUD это соответствует букве C.
INSERT INTO table_name(column1, column2, column3,.)
VALUES(value1, ‘value2’, value3,.);
Этот запрос создает новую запись в таблице, т. е. новую строку.
В части INSERT INTO мы указываем столбцы, которые хотим заполнить информацией. В VALUES указана информация, которую нужно сохранить.
При вставке строковых значений их нужно брать в одинарные кавычки.
Теперь таблица будет выглядеть так:
SELECT
Это ключевое слово служит для выборки данных из базы. В CRUD эта операция соответствует букве R.
SELECT column1,column2
FROM table_name;
В нашем примере этот запрос будет выглядеть следующим образом:
SELECT first_name,last_name
FROM engineering;
Ключевое слово SELECT указывает на конкретный столбец, из которого мы хотим выбрать данные.
В части FROM определяется сама таблица.
Вот еще один пример запроса SELECT:
SELECT * FROM table_name;
Астериск (звездочка) означает, что нам нужна вся информация из указанной таблицы (а не отдельный столбец).
WHERE
WHERE позволяет составлять более специфичные (конкретные) запросы.
Например, мы можем использовать WHERE, чтобы выбрать из нашей таблицы Engineering сотрудников с определенным уровнем зарплаты.
Таблица из предыдущего примера:
Теперь вывод будет такой:
Данные отфильтрованы, и нам показывается только то, что отвечает условию. То есть в выводе мы получаем только строки, где зарплата больше 1500.
Операторы AND, OR, BETWEEN в SQL
Эти операторы позволяют еще больше уточнить запрос. С их помощью можно добавить больше критериев в блоке WHERE.
Оператор AND принимает два условия, причем, чтобы строка попала в результат, оба условия должны быть истинными.
SELECT column_name
FROM table_name
WHERE column1 =value1
AND column2 = value2;
OR тоже принимает два условия, но чтобы строка попала в результат, достаточно истинности хотя бы одного.
SELECT column_name
FROM table_name
WHERE column_name = value1
OR column_name = value2;
Оператор BETWEEN отфильтровывает результаты в определенном диапазоне чисел или текста.
SELECT column1,column2
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
Все эти операторы можно комбинировать друг с другом.
Допустим, наша таблица выглядит так:
Если мы напишем такой запрос:
SELECT * FROM engineering
WHERE employee_id BETWEEN 3 AND 7
AND
country = ‘Germany’;
Мы получим следующий результат:
Были выбраны все столбцы, где employee_id от 3 до 7, а страна проживания — Германия.
ORDER BY
Ключевое слово ORDER BY позволяет отсортировать выдачу по столбцам, указанным в SELECT.
Отсортированные результаты выводятся в порядке возрастания или убывания.
SELECT employee_id, first_name, last_name,salary
FROM engineering
ORDER BY salary DESC;
В этом примере мы отсортировали зарплату сотрудников в команде engineering и представили вывод в порядке убывания числовых значений (DESC — от англ. descending — «нисходящий»).
GROUP BY
Ключевое слово GROUP BY в SQL позволяет комбинировать строки с идентичными и похожими данными.
Это полезно для приведения в порядок дублирующихся данных и записей, которые повторяются в таблице многократно.
SELECT column_name, COUNT(*)
FROM table_name
GROUP BY column_name;
Здесь COUNT(*) подсчитывает все строки и возвращает число строк в указанной таблице, группируя строки-дубликаты.
От редакции Techrocks: о COUNT и других агрегатных функциях можно почитать в статье «Агрегатные функции в SQL: объяснение с примерами запросов».
LIMIT
При помощи LIMIT можно указать максимальное число строк, которые должны попасть в результат.
Это бывает полезно при работе с большими наборами данных. Если данных много, запрос может обрабатываться слишком долго. Но когда будет достигнут лимит результатов, обработка прекратится.
SELECT column1,column2
FROM table_name
LIMIT number;
UPDATE
Ключевое слово UPDATE позволяет обновлять записи в таблице. В CRUD этой операции соответствует буква U.
UPDATE table_name
SET column1 = value1,
column2 = value2
WHERE condition;
В условии WHERE указывается запись, которую нужно отредактировать.
UPDATE engineering
SET country = ‘Spain’
WHERE employee_id = 1
Прежде наша таблица выглядела так:
Теперь, после выполнения запроса, она выглядит так:
Обновилась страна проживания сотрудника с id 1.
Обновить информацию можно и с помощью значений из другой таблицы. Для этого применяется ключевое слово JOIN.
UPDATE table_name
SET table_name1.column_name1 = table_name2.column_name1
table_name1.column_name2 = table_name2.column2
FROM table_name1
JOIN table_name2
ON table_name1.column_name = table_2.column_name;
DELETE
Ключевое слово DELETE служит для удаления записей из таблицы. В CRUD операция удаления представлена буквой D.
DELETE FROM table_name
WHERE condition;
Пример с нашей таблицей:
DELETE FROM engineering
WHERE employee_id = 2;
При выполнении запроса будет удалена запись о сотруднике с id 2 из команды engineering.
DROP COLUMN
Чтобы удалить из таблицы столбец, можно воспользоваться следующим кодом:
ALTER TABLE table_name
DROP COLUMN column_name;
DROP TABLE
Для удаления всей таблицы выполните следующий запрос:
DROP TABLE table_name;
Итоги
В этой статье мы пробежались по самым базовым запросам, с которых начинают все новички в SQL.
Мы научились создавать таблицы и строки, группировать и обновлять данные и, наконец, удалять их. Попутно мы также разобрали SQL-запросы в привязке к операциям CRUD.
Перевод статьи «Learn SQL Queries – Database Query Tutorial for Beginners».
Канал Nuances of programming опубликовал перевод статьи Karlijn Willems «SQL Tutorial: How To Write Better Queries».

Язык структурированных запросов – SQL, является незаменимым навыком в области науки о данных и, вообще говоря, приобрести этот навык довольно просто. Однако большинство забывают, что в написание запросов SQL – это только первый шаг. Обеспечение выполнения запросов в соответствии с требуемым контекстом – это уже совсем другое.
Вот почему в этом руководстве по SQL предоставлен пошаговый обзор, которые позволит вам оценить качество вашего запроса:
Вам требуется пройти курс по SQL? Рассмотрите в качестве варианты курс на DataCamp под названием «Введение в SQL и науку о данных»!
Зачем мне изучать SQL, если я занимаюсь данными?
SQL весьма далек от забвения – напротив, это один из самых востребованных навыков, который вы можете найти в описаниях вакансий в области обработки больших данных, независимо от того, хотите ли вы устроиться на должность аналитика данных, инженера по данным, научного сотрудника в области данных или в качестве еще кого-либо. Этот факт подтверждается результатами исследования рынка труда, проведенным O’Reilly в 2016 году: 70% респондентов, участвовавших в опросе, подтвердили, что в своей профессиональной деятельности они используют SQL. Более того, в обзоре результатов этого исследования язык SQL занимает более высокую позицию, по сравнению с другими языками программирования, такими как R (57%) и Python (54%).
Теперь вы понимаете в чем тут дело: SQL является обязательным навыком, если вы хотите получить работу в сфере обработки больших данных.
Неплохо для языка, который был разработан еще в начале 1970-х годов прошлого века, не правда ли?
Но почему так часто используется именно этот язык? И почему он до сих пор не мертв, как многие другие языки того же поколения?
Для объяснения этого факта можно найти несколько причин: во-первых, компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в системах управления реляционными потоками данных (RDSMS), и SQL требуется для доступа к таким хранимым данным. S QL – это универсальный язык данных: он дает вам возможность взаимодействовать практически с любой базой данных или даже создавать свои локальные базы данных!
Только имейте в виду, что существует немало реализаций SQL, которые несовместимы между собой и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является обязательным для каждого, желающего найти свой путь в это наукоемкой отрасли.
Кроме того, можно с уверенностью сказать, что SQL также включается в новые технологии, такие как Hive, SQL-подобный язык запросов, ориентированный на запросы и управление большими наборами данных, или Spark SQL, которые вы можете использовать для выполнения SQL запросов. Но еще раз напоминаем, SQL, который вы найдете в этих технологиях, будет отличаться от стандартного, который вы, возможно, уже знаете, но разобраться в особенностях конкретной реализации, зная стандартный SQL, вам будет значительно проще.
Если хотите, можем привести такую аналогию с линейной алгеброй: сосредоточив все усилия только на этой одной области математики, вы сможете использовать полученные знания и как хорошую основу для овладения машинным обучением!
Короче говоря, вот причины, по которым вам следует изучить язык структурированных запросов:
И чего же ты все еще ждешь? 🙂
Обработка и выполнение SQL-запросов
Чтобы повысить производительность вашего SQL-запроса, вам сначала нужно знать, что происходит, когда вы запускаете запрос на выполнение.
Во-первых, производится грамматический разбор и строится синтаксическое дерево запроса. Запрос анализируется с целью выявления того, насколько он удовлетворяет синтаксическим и семантическим требованиям. Парсер создает внутреннее представление входящего запроса. Затем это внутреннее представление передается обработчику кода.
Затем в дело вступает оптимизатор – его задача найти оптимальное выполнение или построить оптимальный план данного запроса. План выполнения точно определяет, какой алгоритм используется для каждой операции, и как координируется выполнение операций.
Чтобы действительно найти наиболее оптимальный план выполнения, оптимизатор рассчитывает все возможные планы выполнения, определяет качество или стоимость каждого плана, берет информацию о текущем состоянии базы данных и затем выбирает наилучший план как окончательный и пригодный для выполнения. Оптимизаторы запросов могут быть неидеальными, поэтому пользователям баз данных и администраторам иногда приходится вручную проверять и настраивать планы выполнения запросов, предложенные оптимизатором, чтобы повысить производительность выполнения запроса.
Теперь вы, вероятно, задаетесь вопросом, что считается «хорошим планом запроса».
Как вы уже прочитали выше, критерий стоимости плана играет огромную роль. А именно, для оценки плана необходимы такие вещи, как количество дисковых операций ввода-вывода, стоимость процессора и общее время отклика, которое может наблюдаться для клиента базы данных, а также общее время выполнения. Именно здесь появляется понятие временной сложности. Но об этом вы узнаете чуть позже.
Затем выполняется выбранный план запроса, они оцениваются механизмом выполнения системы и после этого возвращаются результаты вашего запроса.
Таким образом эту последовательность можно записать в виде следующего списка шагов (см. картинку с английской терминологией ниже):
Это означает, что есть некоторые вещи, которые вы можете сделать, когда пишете запрос. Как мы уже во введении, ваша ответственность за качество написания запроса складывается из двух составляющих: в написании запросов, соответствующих определенному стандарту, и понимании того, где могут возникать проблемы при исполнении вашего запроса.
Идеальной отправной точкой является анализ узких мест в ваших запросах, то есть тех мест, в которых могут возникнуть проблемы. И, в общем, есть четыре причины и ключевых слова, где новичков могут ожидать проблемы с производительностью:
Конечно, такой подход слишком прост и наивен, но для новичка эти утверждения являются хорошими указателями, и можно с уверенностью сказать, что, когда вы только начинаете, эти точки – как раз те места, где происходят неправильные действия и, как это ни парадоксально, где их также трудно обнаружить.
Прочитайте наш на следующий раздел, чтобы познакомиться подробнее с анти-шаблонами и альтернативными подходами к написанию запросов. Эти советы и трюки послужат для вас неким ориентиром. Нужно ли вам переписать свой запрос и как это сделать, если его действительно нужно переписать, зависит от количества данных, базы данных и количества раз, которое вам потребуется выполнять запрос. А здесь решающее значение имеет уже только цель вашего запроса и наличие некоторых предварительных знаний о структуре базе данных, к которой вы хотите обратиться!
Получайте только нужные данные
Идеология «чем больше данных, тем лучше» ‑ это не то, что вам нужно для написания SQL-запросов: вы рискуете не только затуманить свои идеи, получая данных на много больше, чем вам нужно, но также производительность вашего запроса может пострадать от того, что он будет выбираться слишком много данных.
Вот почему обычно рекомендуется заботиться об инструкции SELECT, операторах DISTINCT и LIKE.
Первое, что вы уже можете проверить, когда вы написали свой запрос, является ли оператор SELECT максимально возможно компактным. При этом ваша цель – удалить ненужные столбцы из оператора SELECT. Таким образом вы будете запрашивать только те данные, которые служат цели вашего запроса.
Если у вас есть коррелированные подзапросы с оператором EXISTS, вы должны попытаться использовать константу в инструкции SELECT для этого подзапроса вместо того, чтобы выбирать фактическое значение столбца. Это особенно удобно, когда вы проверяете только наличие определенного столбца в таблице.
Помните, что коррелированный подзапрос – это подзапрос, который использует значения из внешнего запроса. И обратите внимание, что, хотя NULL и может здесь использоваться в качестве «константы», это выглядит очень запутанно для понимания вашего запроса другими разработчиками!Рассмотрим следующий пример, чтобы понять, что мы подразумеваем под использованием константы:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS (SELECT ‘1’ FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr);
SELECT driverslicensenr, name
FROM drivers
INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr;
Оператор SELECT DISTINCT используется для возврата только различных значений. DISTINCT – это условие, которого, при возможности, лучше всего избегать. Как вы можете видеть и на других примерах, время выполнения увеличивается только в том случае, если вы добавили это предложение в свой запрос. Поэтому всегда стоит подумать над тем, действительно ли вам нужна операция DISTINCT, чтобы получить нужный вам результат.
Когда вы используете оператор LIKE в запросе, индекс не используется, если шаблон начинается с % или _. Эти шаблоны запрещают использование индексов базы данных (если он имеются). Ну и конечно, с другой стороны, этот тип запроса потенциально оставляет открытой возможность для извлечения слишком большого количества записей, которые не обязательно могут удовлетворять цели вашего запроса.
Отметим еще раз – знания структуры хранимых данных могут помочь вам сформулировать шаблон, который будет правильно фильтровать все данные, чтобы выбрать из базы только те строки, которые действительно важны для вашего запроса.
Ограничьте свои результаты
В тех случаях, когда вам не удается избежать фильтрации в инструкции SELECT, вы можете ограничить свои результаты другими способами. Ниже приведены другие подходы, такие как оператор LIMIT и преобразования типов данных.
Вы можете добавить оператор LIMIT или TOP к своим запросам, чтобы установить максимальное число выбираемых в результате строк. Вот некоторые примеры:
SELECT TOP 3 * FROM Drivers;
Обратите внимание, что вы можете дополнительно указать PERCENT, например, если вы измените первую строку запроса с помощью SELECT TOP 50 PERCENT *.
SELECT driverslicensenr, name FROM Drivers LIMIT 2;
Кроме того, вы также можете добавить оператор ROWNUM, что эквивалентно использованию LIMIT в запросе:
SELECT *
FROM Drivers
WHERE driverslicensenr = 123456 AND ROWNUM <= 3;
Вы всегда должны использовать самые эффективные, то есть самые маленькие, типы данных. Всегда существует риск, когда вы предоставляете огромный тип данных, когда меньший будет более достаточным.
Однако, когда вы добавляете преобразование типа данных в свой запрос, вы увеличиваете время выполнения.
Альтернатива заключается лишь в том, чтобы стараться избегать преобразования типа данных, насколько это возможно. Обратите также внимание, что не всегда возможно удалить или опустить преобразование типа данных из запросов, но вы должны определенно стремиться быть осторожным в их использовании, а в случае использования, советуем проверять эффект применения преобразования типа перед запуском запроса.
Пишите запросы как можно проще
Преобразования типов данных приводят вас к следующему: вы не должны чрезмерно усложнять свои запросы. Старайтесь сохранять их простыми и эффективными. Этот совет может показаться слишком простым или глупым, особенно потому, что запросы могут быть и сложными.
Тем не менее, вы увидите на наших примерах в следующих разделах, действительно можно легко начать делать простые запросы более сложными, гораздо сложнее, чем это необходимо на самом деле.
Когда вы используете оператор OR в запросе, вероятно, вы не можете воспользоваться индексом.
Помните, что индекс — это структура данных, которая повышает скорость поиска данных в таблице базы данных, но она имеет свою стоимость: для поддержания индексной структуры данных необходимы дополнительные записи и дополнительное пространство для хранения. Индексы используются для быстрого поиска или поиска данных без необходимости поиска к каждой строке базы данных каждый раз, когда обращается к таблице баз данных. Индексы могут быть созданы на основе одного или нескольких столбцов в таблице базы данных.
Если вы не используете индексы, имеющиеся в базе данных, выполнение вашего запроса неизбежно займет больше времени. Вот почему лучше всего искать альтернативы использованию оператора OR в запросе.
Рассмотрим следующий запрос:
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr = 123456 OR driverslicensenr = 678910 OR driverslicensenr = 345678;
Вы можете заменить оператор на:
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr IN (123456, 678910, 345678);
Два оператора SELECT с UNION.
Совет. Здесь вам нужно быть осторожным, и излишне не прибегать к использованию операции объединения UNION, потому что в этом случае вы проходите одну и ту же таблицу несколько раз. С другой стороны, вы должны понимать, что при использовании UNION в запросе время выполнения увеличивается. Альтернативой операции UNION является переформулировка запроса таким образом, чтобы все условия были помещены в одну инструкцию SELECT или с использованием OUTER JOIN вместо UNION.
Совет. Помните также, что, хотя OR и другие операторы, которые будут упомянуты в следующих разделах, вероятно, не используют индекс, индексные запросы не всегда предпочтительны!
Когда ваш запрос содержит оператор NOT, вероятно, индекс не используется, как и для оператора OR. А это неизбежно замедлит выполнение вашего запроса. Если вы не понимаете, что мы подразумеваем, рассмотрите следующий запрос:
SELECT driverslicensenr, name FROM Drivers WHERE year <= 1980;
Это уже выглядит аккуратно, не так ли?
Оператор AND – это другой оператор, который не использует индекс и тоже может замедлить выполнение вашего запроса, особенно если он используется слишком сложным и неэффективным способом, как в примере ниже:
Лучше переписать этот запрос и использовать оператор BETWEEN:
SELECT driverslicensenr, name
FROM Drivers
WHERE year BETWEEN 1960 AND 1980;
Кроме того, операторы ALL и ALL ‑ это такие операторы, с которыми нужно обращаться очень осторожно, потому что, включение их приводит к отказу от использования индекса. Альтернативными вариантами, которые могут здесь пригодится, являются функции агрегации, такие как MIN или MAX.
Также в тех случаях, когда столбец используется в вычислениях или в скалярной функции, индекс не используется. Возможное решение проблемы состоит в том, чтобы просто изолировать конкретный столбец, чтобы он больше не являлся частью операции вычисления или функции. Рассмотрим следующий пример:
SELECT driverslicensenr, name
FROM Drivers
WHERE year + 10 = 1980;
Это выглядит причудливо, да? Попробуйте вместо этого пересмотреть расчет и переписать запрос примерно так:
SELECT driverslicensenr, name
FROM Drivers
WHERE year = 1970;
Перевод статьи «SQL Order of Operations».
Мы привыкли, что компьютер выполняет команды программиста последовательно, в том порядке, который указал автор кода. Однако SQL относится к декларативным языкам, то есть SQL-запрос описывает ожидаемый результат, а не способ его получения.
Давайте разберём, в какой последовательности выполняются шесть операций в SQL: SELECT, FROM, WHERE, GROUP BY, HAVING и ORDER BY.
База данных сотрудников
В этой статье мы поработаем с типичной базой сотрудников, относящихся к разным отделам. По каждому сотруднику известны его ID, имя, фамилия, зарплата и отдел:
Проанализировать порядок выполнения команд в запросах помогут типичные задачи:
Начнем с получения имён сотрудников отдела IT:
SELECT LAST_NAME, FIRST_NAME
FROM EMPLOYEE
WHERE DEPARTMENT = ‘IT’
В первую очередь выполняется FROM EMPLOYEE:
Затем наступает очередь WHERE DEPARTMENT = ‘IT’, который фильтрует колонку DEPARTMENT:
Наконец, SELECT FIRST_NAME, LAST_NAME скрывает ненужные колонки и возвращает финальный результат:
Отлично! После первого препарирования выяснилось, что простой запрос с операторами SELECT, FROM, и WHERE выполняется по следующей схеме:
Влияние ORDER BY на план выполнения запроса
Допустим, что начальнику не понравился отчет, основанный на предыдущем запросе, потому что он хочет видеть имена в алфавитном порядке. Исправим это с помощью ORDER BY:
SELECT LAST_NAME, FIRST_NAME
FROM EMPLOYEE
WHERE DEPARTMENT = ‘IT’
ORDER BY FIRST_NAME
Выполняться такой запрос будет так же, как и предыдущий. Только в конце ORDER BY отсортирует строки в алфавитном порядке по колонке FIRST_NAME:
Таким образом, команды SELECT, FROM, WHERE и ORDER BY выполняются в следующей последовательности:
GROUP BY и HAVING
Усложним задачу. Посчитаем количество сотрудников каждого отдела с зарплатой выше 80 000 и остортируем результат по убыванию. Нам подойдёт следующий запрос:
Как обычно, в первую очередь выполнится FROM EMPLOYEE и вернет сырые данные:
Затем применяется GROUP BY. При этом генерируется по одной записи для каждого отдельного значения в указанной колонке. В нашем примере мы создаем по одной записи для каждого отдельного значения колонки DEPARTMENT:
После этого применяется SELECT с COUNT(*), производя промежуточный результат:
Применение ORDER BY завершает выполнение запроса и возвращает конечный результат:
План выполнения данного запроса следующий:
Добавим выражение HAVING
HAVING — это аналог WHERE для GROUP BY. С его помощью можно фильтровать агрегированные данные.
Давайте применим HAVING и определим, в каких отделах (за исключением отдела продаж) средняя зарплата сотрудников больше 80 000.
По уже известной нам схеме сначала выберем все данные из таблицы при помощи FROM EMPLOYEE:
Затем конструкция WHERE избавит нас от данных по отделу SALES:
GROUP BY сгенерирует следующие записи:
А SELECT вернет финальный результат:
Порядок выполнения для данного запроса следующий:
Новый оператор — JOIN
До этого момента мы имели дело с одной таблицей. А что если воспользоваться JOIN и добавить ещё одну? Выясним фамилии и ID сотрудников, работающих в отделе с бюджетом более 275 000:
FROM EMPLOYEE как обычно запрашивает данные из таблицы EMPLOYEES:
А теперь JOIN запросит сырые данные из DEPARTMENT и скомбинирует данные двух таблиц по условию ON DEPARTMENT = DEPT_NAME:
SELECT EMPLOYEE_ID, LAST_NAME покажет финальный результат:
Для этого запроса план выполнения следующий:
Примеры разных запросов убедительно продемонстрировали, что существует строгий порядок выполнения операций. Но этот порядок может меняться в зависимости от набора команд в запросе. Вот универсальная шпаргалка по очередности выполнения операций в SQL-запросах:
Помните, что если исключить из этого списка один из операторов, то план выполнения может измениться.
