
Добрый день, в связи с заполнением, стоит задача перенести RAID1, в который сейчас входят два диска по 250гб, на диски по 1тб.
df -h
Файл.система Размер Использовано Дост Использовано% Cмонтировано в
/dev/mapper/vg0-root 938M 644M 247M 73% /
udev 2,0G 4,0K 2,0G 1% /dev
tmpfs 396M 296K 395M 1% /run
none 5,0M 0 5,0M 0% /run/lock
none 2,0G 0 2,0G 0% /run/shm
/dev/mapper/vg0-boot 87M 60M 23M 73% /boot
/dev/mapper/vg0-tmp 2,8G 69M 2,6G 3% /tmp
/dev/mapper/vg0-var 9,2G 993M 7,8G 12% /var
/dev/mapper/vg0-usr 9,2G 806M 8,0G 10% /usr
/dev/mapper/vg0-home 1,9G 106M 1,7G 6% /home
/dev/mapper/vg0-opt 202G 190G 2,1G 99% /opt/dev/md0: Version : 1.2 Creation Time : Wed May 29 18:23:01 2013 Raid Level : raid1 Array Size : 244066112 (232.76 GiB 249.92 GB) Used Dev Size : 244066112 (232.76 GiB 249.92 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Thu Jun 30 09:01:03 2016 State : clean Active Devices : 2
Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Name : mail:0 UUID : c38280a9:88e8f6f9:539896a8:4aad2212 Events : 1059 Number Major Minor RaidDevice State 0 8 17 0 active sync /dev/sdb1 1 8 1 1 active sync /dev/sda1NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 232,9G 0 disk
└─sda1 8:1 0 232,9G 0 part └─md0 9:0 0 232,8G 0 raid1 ├─vg0-boot (dm-0) 252:0 0 92M 0 lvm /boot ├─vg0-root (dm-1) 252:1 0 952M 0 lvm / ├─vg0-swap (dm-2) 252:2 0 1,9G 0 lvm [SWAP] ├─vg0-tmp (dm-3) 252:3 0 2,8G 0 lvm /tmp ├─vg0-var (dm-4) 252:4 0 9,3G 0 lvm /var ├─vg0-usr (dm-5) 252:5 0 9,3G 0 lvm /usr ├─vg0-home (dm-6) 252:6 0 1,9G 0 lvm /home └─vg0-opt (dm-7) 252:7 0 204,9G 0 lvm /opt
sdb 8:16 0 232,9G 0 disk
└─sdb1 8:17 0 232,9G 0 part └─md0 9:0 0 232,8G 0 raid1 ├─vg0-boot (dm-0) 252:0 0 92M 0 lvm /boot ├─vg0-root (dm-1) 252:1 0 952M 0 lvm / ├─vg0-swap (dm-2) 252:2 0 1,9G 0 lvm [SWAP] ├─vg0-tmp (dm-3) 252:3 0 2,8G 0 lvm /tmp ├─vg0-var (dm-4) 252:4 0 9,3G 0 lvm /var ├─vg0-usr (dm-5) 252:5 0 9,3G 0 lvm /usr ├─vg0-home (dm-6) 252:6 0 1,9G 0 lvm /home └─vg0-opt (dm-7) 252:7 0 204,9G 0 lvm /optПрочитав достаточно материалов по теме переноса, представляю это себе так:
- Помечаю один диск сбойным
- удаляю его из массива
- подключаю новый
- копирую на него разделы
- провожу такие же манипуляции со вторым диском.
Интересует вот что: как это провернуть с минимальным шансом потери данных(само собой, резервные копии есть), верен ли мой алгоритм действий и как бы это сделали вы?
Более подробно о переносе, разделы нужно перенести без изменения размеров за исключением /opt, как я понял в рейд завернут lvm, вроде как это должно упростить задачу, но мне все таки сыкатно, это мой первый опыт по переносу массива на диски большего размера.
Пост написан по «горячим следам». Информации будет много. Над каждой операцией рекомендуется думать, а не тупо копипастить
- Замена дисков
- Увеличение размера массива
- Шаг #1. Удаление диска. Переход с MBR на GPT. Изменение размера диска
- Шаг #2. Изменение размера md0
- Шаг #3. Увеличение размера раздела и файловой системы
- P.S.
- 1. Выполнить клонирование разделов на другой носитель
- 2. Писать в саппорт производителя рейд-контроллера
- Подготовка
- Перед тем как писать на саппорт нужно было получить дампы с контроллера
- Результаты
- Проблемы сер?
- Извлечение дисков из живого рейда на adaptec 6805
- Задача:
- В чем сложность?
- Описание:
- Решение:
- Adaptec 5805, 8 дисков RAID5, требуется поменять один. Как?
- Adaptec 5805, 8 дисков RAID5, требуется поменять один. Как?
- Re: Adaptec 5805, 8 дисков RAID5, требуется поменять один. Как?
- Re: Adaptec 5805, 8 дисков RAID5, требуется поменять один. Как?
- Управление массивами RAID Adaptec 6405
- Создание массива RAID Adaptec 6405
- Замена вышедшего из строя диска
- Горячая замена диска Adaptec 6405
- Горячая замена диска Adaptec 6405
- Maxview storage manager замена диска
- Инициализация дисков
- Как создать raid
- Создаем RAID 0
- Создаем RAID 1
- Создаем RAID 5
- Создаем RAID 10
- Описание кэширования LUN
- Maxview storage manager замена диска
- Установка maxView Storage Manager в VMware ESXI 5
- Порядок установки maxview storage manager
- Megaraid bios config utility замена диска
Замена дисков
Прежде, чем работать с массивом размонтируем его
/dev/md0p1 5.5T 4.5T 720G 87% /backup
Проверим состояние массива
Массив синхронизирован, все харды в работе
И какой диск менять?

Чтобы с этим разобраться попросим smartctl показать серийные номера всех хардов. В качестве примера работаем с диском sde. С остальными все аналогично
Serial Number: Z293SBCG
Этот номер записали. Позже будем искать его на наклейке харда
Перед физической заменой програмно даем понять md0, что диск sde сбойный и его нужно удалить из массива
mdadm --manage /dev/md0 --fail /dev/sde1 --remove /dev/sde1mdadm: set /dev/sde1 faulty in /dev/md0
mdadm: hot removed /dev/sde1 from /dev/md0
Если не пометить диск сбойным, а удалять сразу, то получим ошибку
mdadm: hot remove failed for /dev/sde: Device or resource busy
Смотрим, что осталось

Отлично, sde в массиве нет! Выключаем сервер и ищем диск с серийным номером Z293SBCG и меняем его на новый
После запуска сервера копируем разметку со старого «живого» диска на свежеустановленный
Disklabel type: dos
Disk identifier: 0xf90f6227Device Boot Start End Sectors Size Id Type
/dev/sde1 2048 3907029167 3907027120 1.8T fd Linux raid autodetectThe partition table has been altered.
Calling ioctl() to re-read partition table.
Немного ругается на размер, но сейчас это неважно. Добавляем диск в массив
mdadm --manage /dev/md0 --add /dev/sde1mdadm: added /dev/sde1
Это все. Наблюдаем за синхронизацией онлайн
watch 'cat /proc/mdstat'
Время синхронизации 4+ часов после каждой замены
После окончания синхронизации можно приступать к замене следующего диска
В результате инфа перенесена один-в-один с теми же размерами разделов, что и на старых хардах. Дополнительное пространство еще не доступно
Увеличение размера массива
После замены всех дисков и синхронизации (смотрим, что показывает cat /proc/mdstat) можно приступать к процедуре увеличения размера массива, что возможно если текущий RAID имеет тип 1, 4, 5, 6. Для этого необходимо будет выполнить несколько шагов, а именно:
- Удалить диск из массива, увеличить его размер и снова вернуть в массив. Дождаться окончания синхронизации. Эту операцию нужно проделать с каждым диском
- Увеличить размер md0, который кстати не в курсе, что у него диски с большим размером, ему об этом нужно сообщить
- Изменить размер раздела массива и файловой системы расширив их до максимума
Шаг #1. Удаление диска. Переход с MBR на GPT. Изменение размера диска
В ходе работ было видно, что со старых дисков, объем которых был 2ТБ перекочевала и старая схема разделов MBR. У такой схемы есть ограничения — 2ТБ на раздел. Новые диски по 4ТБ, следовательно нужна GPT
Удаляем диск из массива
mdadm --manage /dev/md0 --fail /dev/sde1 --remove /dev/sde1Размер меняем при помощи parted. Для начала посмотрим, что он видит
parted /dev/sde print
Ключевое слово msdos
Сразу создаем новую схему разделов GPT
parted /dev/sde mklabel gptWarning: The existing disk label on /dev/sde will be destroyed and all data on this disk will be lost. Do you want to continue?
отвечаем ‘Y’. И пусть рука не дрогнет 🙂
Создаем раздел с меткой ‘backup’. Размер раздела — все доступное пространство
parted -s /dev/sde mkpart backup 1 100%Смотрим на схему разделов
parted /dev/sde print
Ключевое слово gpt. Изменился размер раздела
и добавляем диск в массив
mdadm --manage /dev/md0 --add /dev/sde1mdadm: re-added /dev/sde1
Может начаться синхронизация. Тогда нужно ждать. У меня кажется такого не было. На всякий случай смотрим, что покажет cat /proc/mdstat
С остальными дисками проделываем те же операции. Кому страшно, может сделать бекап. Бекап бекап-сервера звучит прикольно. Хотя я допускаю, что для кого-то это реалии
Шаг #2. Изменение размера md0
Еще раз убеждаемся, что все диски синхронизированы (опять cat /proc/mdstat. Да, эта команда популярна). Если так, то смотрим, что знает md0 о своем размере и размере диска к нему подлюченного
Array Size : 5860147200 (5588.67 GiB 6000.79 GB)
Used Dev Size : 1953382400 (1862.89 GiB 2000.26 GB)
Из этого ответа ясно, что для md0 до сего момента ничего не изменилось
Увеличим размер массива до максимума
mdadm --grow /dev/md0 -z maxmdadm: component size of /dev/md0 has been set to 3906885632K
И еще раз смотрим на размер массива и устройства
Array Size : 11720656896 (11177.69 GiB 12001.95 GB)
Used Dev Size : 3906885632 (3725.90 GiB 4000.65 GB)
Такс, уже другие цифры. Размер md0 увеличен. Проверяем
parted /dev/md0 printNumber Start End Size File system Name Flags
1 1000kB 6001GB 6001GB ext4 backup
Команда попросила разрешения пофиксить, соглашаемся. Размер md0 изменился, размер раздела 1 остался прежний
Шаг #3. Увеличение размера раздела и файловой системы
Увеличиваем размер раздела (Number 1) до максимального
parted -s /dev/md0 resizepart 1 -1Проверяем, что вышло
parted /dev/md0 printModel: Linux Software RAID Array (md)
Disk /dev/md0: 12.0TB
Sector size (logical/physical): 512B/4096B
Partition Table: gptNumber Start End Size File system Name Flags
1 1000kB 12.0TB 12.0TB ext4 backup
Размер раздела 1 стал больше, как и ожидалось
Проверяем состояние ФС на разделе. Это обязательно
e2fsck -f /dev/md0p1И последний шаг, увеличение размера ФС
Проверяем, что видят md0 и ОС
mount /dev/md0p1 /backup/df -h /backup
/dev/md0p1 11T 4.5T 5.9T 44% /backup
Отлично! Что и требовалось сделать
На следующем этапе работ предстоит заставить ОС увидеть raid-контроллер 3ware, после чего выполнить миграцию системы без LiveCD
P.S.
Практически на любом этапе была возможность примонтировать md0p1 и убедиться, что данные на месте
Все операции с parted выполнялись в командной строке. Само-собой, что их можно выполнить непосредственно в интерфейсе parted выбрав нужный диск
Вся эта работа выполнялась из чисто спортивного интереса. Можно было пойти тремя путями:
- вытащить старые харды, вставить новые, пересоздать массив и получить максимум пространства. После пересоздать структуру папок, куда складываются бекапы с других серверов и раздать им нужные права. Самый быстрый вариант по времени
- поменять харды последовательно, по-одному, как написано в первой части поста с последующим пересозданием массива, папок и прав. Тут нужно больше времени ибо синхронизация, которая длилась 4+ часов после каждой замены. Не очень отличается от п.1
- вставить дополнительно новый хард, переписать инфу на него (пришлось бы пожертвовать частью бекапов, все не поместилось бы), удалить старые харды, создать raid5 из 3 оставшихся новых, переписать инфу на вновь созданный md0 (у которого уже новый UUID) после чего добавить 4-й хард в массив и пережить синхронизацию
Первых два варианта предполагали потерю бекапов и надежды на то, что «сегодня» ничего не навернется и пользователи не попросят что-то восстановить. Третий вариант показался тривиальным. Кроме того хотелось сделать «все красиво». В результате бекапы не пострадали, админ приобрел опыт и написал полезный, как он думает пост
- Системный администратор с 2000 года
- Участник Freelancehunt, Хабр Q&A, cyberforum
- Кейсы
Если вы думаете, что после замены дисков в рейд-массиве на диски большего объёма вы сразу получите дополнительное свободное место, спешу расстроить — не получите. Так просто — не получите. Хорошо если контроллер умеет expand, тогда у вас нет проблем и при помощи этой функции вы свободное место получите. А что делать, если такой функции нет? Вариантов как минимум два:
1. Выполнить клонирование разделов на другой носитель
Убедится, что система загружается штатно. Перегрузится, зайти в биос рейд-контроллера, удалить старый массив и создать новый. Склонировавать разделы с резервного носителя на вновь созданный массив, после этого дисковая утилита ОС должна показать наличие свободного места
2. Писать в саппорт производителя рейд-контроллера
Я выбрал второй вариант. Не потому, что мне первый не подходил, а скорее потому, что хотелось выяснить насколько оперативно и точно работает саппорт
Подготовка
Под рукой был сервер с рейд-контроллером 3ware 9650SE-2LP. На нём был построен raid1 массив из двух дисков номинальным объёмом 200Гб. На замену было два диска номиналом по 320Гб. Последовательно была проведена замена дисков в массиве. В результате я увидел, что размер массива не изменился, соответственно свободное место система и не могла видеть. И не важно, что tw_cli системы, как и биос контроллера показали наличие двух дисков по 320Гб
Перед выполнением действий описаных далее очень желательно иметь бекапПеред тем как писать на саппорт нужно было получить дампы с контроллера
Для этого мне потребовалась загрузочная флешка с ms-dos’ом, куда позже я скинул содержимое архива dumpall. Загрузился с флешки и выполнил dumpdcb.bat. В первый раз софтина подвисла, я перегрузился, запустил снова и через несколько секунд получил дамп с логами. Запаковал *.bin и *.log в архив. Важно сохранить pridcb#-файлы, на тот случай, если что-то пойдёт не так и нужно будет откатить конфигурацию. Вместо значка # будет номер диска на порту контроллера
Результаты
После этого зарегистрировался на саппорт LSI, заполнил заявку, вложил полученый архив и начал ждать. Время реакции саппорта с поправкой на часовой пояс составило часов пять. В результате я получил от них новые pridcb#-файлы и writedcb.bat, которые записал на флешку и загрузился в ДОС. Выполнил writedcb.bat. После перегрузки зашёл в биос контроллера и увидел правильный размер массива.
Проблемы сер?
Если вдруг биос контроллера показывает не тот размер массива, что вы ожидаете, то при старте система не загрузится. Чтобы откатиться нужно загрузиться с флешки и при помощи writedcb.bat накатить старые pridcb#-файлы. Таким образом работоспособность сервера будет восстановлена. У меня всё прошло успешно, сервер загрузился, рейд контроллер принудительно провёл инициализацию массива. Всё работает
P.S. Подобный фокус провернуть с массивом на контроллере PERC 6/i не получится, только следовать варианту №1
- Системный администратор с 2000 года
- Участник Freelancehunt, Хабр Q&A, cyberforum
- Кейсы
>> Как поступить с оставшимся местом?
Ну, а воткнуть два этих больших, собрать на них ещё один RAID, а потом скопировать данные с первого массива, не вариант?
GotF
(12.01.11 10:59:29 MSK)

Не вариант. Нужно именно заменить, т.к. их больше некуда втыкать. В этом и вся проблема.
NEM
(12.01.11 11:02:57 MSK)
- удалить один диск из массива
- вставить новый, и создать на нём degraded-массив уже большего размера
- скопировать туда данные
- удалить первый диск, вставить на его место второй большой
- добавить последний в новый массив
- resync
- PROFIT!
GotF
(12.01.11 11:15:52 MSK)
NEM
(12.01.11 11:24:46 MSK)

А если бы Вы предварительно на этапе инсталляции сервера подумали и задействовали LVM, то можно было бы просто сделать так:
mdadm --create /dev/md2 -n 2 -l raid1 /dev/sdc1 /dev/sdd1
vgextend vgname /dev/md2
pvmove /dev/vgname/volume1 /dev/md2
pvmove /dev/vgname/volume2 /dev/md2
...
pvmove /dev/vgname/volumeN /dev/md2
vgreduce vgname /dev/md1Nastishka
(12.01.11 11:57:18 MSK)
>> Нужно именно заменить, т.к. их больше некуда втыкать.
их больше некуда втыкать
Или я чего-то не понимаю? 🙂
GotF
(12.01.11 12:00:03 MSK)
Кстати да — если ТСу все равно некуда втыкать винты — значит ему так и так устраивать даунтайм, почему бы просто тогда не воткнуть один старый +2 новых в другой комп и там просто все скопировать??? Тут уже никакой разницы, будет ли два рестарта в 30 минут или один даунтайм на те же 30 минут, КМК.
Nastishka
(12.01.11 12:07:13 MSK)
>А если бы Вы предварительно на этапе инсталляции сервера подумали и задействовали LVM
Было это 6 лет назад и об этом не думалось. 🙁
NEM
(12.01.11 12:16:20 MSK)

Было это 6 лет назад
придерживаемся политики «а не заменить ли нам винты после 36 месяцев работы, даже если смарт красивый?». 6 лет — это очень круто!
spunky
(12.01.11 12:20:28 MSK)
>Тут уже никакой разницы, будет ли два рестарта в 30 минут или один даунтайм на те же 30 минут, КМК.
Тогда будет 2х30=60 мин. вместо 30 мин. Или я чего-то не догнал? 🙂
NEM
(12.01.11 12:21:24 MSK)
>6 лет — это очень круто!
🙂 Будут работать заразы до смерти!
NEM
(12.01.11 12:22:48 MSK)

жесть, вот это Ъ-ынтерпрайз.
не буду постить сюда офтоп, кто хочет сам найдет, как эта задача решается в более других системах, но скажу что даунтайм для этого точно не нужен 😉
>ставить новый, и создать на нём degraded-массив уже большего размера
зачем такой велосипед? разве просто расширить границы последних разделов на винтах и resync недостаточно, чтобы оно автоматом расширило последний массив?
почему?
во-первых, знак вопроса
во-вторых, я привык, что после процедуры ниже, все автомагически будет как надо
— вывести диск из массива(ов)
— вытащить
— вставить новый
— разметить как было. подозреваю, в случае линукса, расширить границы последнего раздела до конца нового диска. в zfs нет радостей статических разделов.
— присоединить обратно в массив, подождать пока закончится sync.
— повторить со вторым диском
— magic 😉
Во первых, знака вопроса не должно было быть.
Во вторых, меня не устраивают размеры старых разделов.
Спасибо за еще один совет. 🙂
А мне надо маны по LVM читать.
NEM
(13.01.11 16:14:18 MSK)
>> зачем такой велосипед?
Потому что просто и надёжно. А с ресайзом я сам не пробовал, потому не знаю, работает оно, или нет 🙂
GotF
(13.01.11 16:22:40 MSK)
>>Во вторых, меня не устраивают размеры старых разделов
разделов где-то посреди? что-же за разметка диска такая тогда? =)
даже если и так, стоит попробовать на тестовом стенде раметив первый диск в соответствии с желаемым результатом. mdadm по-идее должно быть по барабану где начинается/кончается раздел, главное чтоб не меньше был.
>> в zfs нет радостей статических разделов.
А как у них с фрагментацией, в таком случае? Ведь возможна ситуация, когда раздел сильно расползётся по разным участкам диска? В LVM можно установить требование непрерывной аллокации. А тут?
GotF
(13.01.11 16:39:20 MSK)
P.S.: да, в LVM разделы не в полном смысле динамические, но тем не менее.
GotF
(13.01.11 16:41:28 MSK)
>разделов где-то посреди? что-же за разметка диска такая тогда? =)
Может я не очень подробно все описал, но на этом массиве нет системы (она в другой паре винтов), а здесь же файлопомойка для Самбы.
NEM
(13.01.11 17:25:00 MSK)
>ну вот реальный шанс узнать.
Не шанс. Сервак рабочий. И надо сделать все быстро.
NEM
(13.01.11 17:27:02 MSK)
Не вариант. Нужно именно заменить, т.к. их больше некуда втыкать. В этом и вся проблема.
Винты IDE/SATA? Можно купить переходников USB->SATA/IDE.
Deleted
(13.01.11 17:30:55 MSK)
САТА. А Вы батенька телепат, однако!
Висит и на УСБ карманчик с одним винтом для не критической информации (т.е. ее утрата может вызвать только легкое сожаление). И не хочется, чтобы важный массив находился вне корпуса системника.
NEM
(13.01.11 17:41:07 MSK)
И не хочется, чтобы важный массив находился вне корпуса системника.
Это же временно, только на время копирования информации.
Deleted
(13.01.11 17:50:29 MSK)
>>но на этом массиве нет системы
это, в общем то, неважно. хотя в лине я уже ничему не удивляюсь, особенно после предложения воткнуть в другой комп )
вариантов надавали, осталось выбрать =)
>Это же временно, только на время копирования информации.
Мне трудно будет обьяснить руководству целесобразность покупки данного девайса для временного использования.
Еще раз спасибо за практические советы!
NEM
(13.01.11 17:56:31 MSK)
rezets
Зарегистрирован: 04.12.2008
Пользователь #: 74,177
Сообщения: 117
Извлечение дисков из живого рейда на adaptec 6805
Задача:
Извлечь 2 харда из raid-10 на логическом уровне (т.е., не извлекая из сервака физически), чтобы собрать из них raid-1, перенести туда систему и подготовить всё что можно к ребуту, таким образом минимизировав время и количество даунтаймов.
В чем сложность?
В 5 серии адаптеков вопрос решался двумя командами:
1. Зафейлили диск: arcconf setstate 1 device 0 0 ddd
2. Перевели в статус Ready: arcconf setstate 1 device 0 0 rdy
3. Делаем с дисками, что хотим.
В 6 серии так не прокатывает. Вне зависимости от того, включен failover или нет, диски возвращаются в состояние Present, и с ними ничего нельзя поделать (думаю, ясно, что сам рейд будет Degraded, пока не пройдет Rebuild).
Попытка обратиться в официальную тех.поддержку была неудачна — ответ я получил, но возникло ощущение, что я использую домашнюю железку, а не сервер, который нельзя просто так дергать туда-сюда:
После того как вы провели команду «arcconf setstate 1 device 0 0 ddd», система была перезагружена? Если нет, то перезагрузите и инициализируете оба диска в БИОСе контроллера. Там сразу же можно и создать RAID-1.
Чтобы стереть мете-данные на диске под Arcconf диск можно инициализировать с командой «arcconf task». Например: arcconf task start 1 device 0 0 initialize
После этого диск должен быть доступным для создания других логических дисков.
Однако, если Вы выбрасываете из RAID-10 два диска, то он остаётся в статусе «Degraded». При ошибке одного из оставшийся в массиве дисков может рухнуть весь массив. Поэтому, возможно, просто сделайте бэкап всех данных, потом просто удалите массив RAID-10 и создавайте два отдельных RAID-1.
Я подумал и решил вопрос очередью экспериментов, после чего смог выполнить поставленную задачу.
Описание:
Имеем logical device с raid-10 на 4 дисках
Необходимо вытащить из него 2 харда (по одному из разных групп) и составить raid-1 из них
Решение:
1. Убеждаемся, что failover включен
2. Фейлим 2 диска из разных групп
Диски станут Inconsistent в logicaldevice и Failed в physicaldevice
3. Переводим эти диски в статус ready
Диски станут Missing в logicaldevice и Ready в physicaldevice
4. Ждем до тех пор, пока failover не запустит rebuilding
Ребилдиться они будут по очереди, т.ч., как только видим у одного из них состояние Rebuilding, делаем пункт 5 сразу, затем для следующего.
5. Фейлим и очень быстро переходим к пункту 6
Диски станут Inconsistent в logicaldevice и Failed в physicaldevice
6. Переводим диски в статус Ready и очень быстро переходим к пункту 7
Диски станут Missing в logicaldevice и Ready в physicaldevice
7. Отключаем failover и очень быстро переходим к пункту 8
8. Инициализируем диски
Ура, можем состряпать из них raid-1
У читателя, возможно, возникнут вопросы, для чего мы провели 2 раза одни и те же действия и почему сразу не отключили failover.
Повторюсь, 6 серия адаптеков не даёт возможности спокойно вывести диски из рейда при отключенном failover после команды:
arcconf setstate 1 device 0 0 rdy мы бы получили статус диска в logicaldrive Present, а статус рейда Degraded, при этом диск в physicaldrive был бы в статусе Online, а не Ready.
И почему же начиная с пункта 5 мы все делаем быстро? Все просто, контроллер через несколько секунд успевает опомниться и сменить статус
дисков, поэтому нужно успеть выполнить команды до того, как он это сделает.
Найти готовое решение не смог, пришлось изобретать свое, надеюсь, кому-то будет полезно — не один же я юзаю 6 серию адаптеков.
UPD. Проапгрейдил 10 серваков, всё прошло успешно. Единственная правка это то что удается за один раз вытащить только один хард из рейда, потом надо повторить действия и вытащить 2ой. Если диск удалось вытащить, но настойчивый контроллер пытается его снова заюзать просто запихните его в JBOD, вытащите 2ой диск, 1ый уберите из JBOD и сможете создать 1 рейд на 2х свободных дисках.
Adblock
detector
Adaptec 5805, 8 дисков RAID5, требуется поменять один. Как?
Adaptec 5805, 8 дисков RAID5, требуется поменять один. Как?
Сообщение redbiz » 10 июл 2012, 19:31
Re: Adaptec 5805, 8 дисков RAID5, требуется поменять один. Как?
Сообщение gs » 10 июл 2012, 19:36
Re: Adaptec 5805, 8 дисков RAID5, требуется поменять один. Как?
Сообщение redbiz » 10 июл 2012, 20:04
Но дело в том, что когда я вынимаю диск «на горячую», и устанавливаю новый диск (или обратно старый), то комп виснет. Диски стоят в корзинах. А если перезагрузить, то массив находится в OFFLINE и никакими танцами с бубном его оттуда не получается вызволить. Если зайти через биос контроллера в раздел Array Manager, и выбрать раздел массива, то в списке присутствуют 7 дисков, а новый обозначен как «—inaccessible disk—«, хотя диск исправный, в разделе «управление дисками» его видно и можно отформатировать и верифицировать.
Управление массивами RAID Adaptec 6405
Управление массивами RAID Adaptec 6405 включает в себя не только создание и удаление массивов, но и задачи, связанные с обслуживанием вышедших из строя дисков или с их плановой заменой . В этой статье я рассмотрю повседневные задачи серверного администратора.
Подробнее о контроллерах Adaptec серии 6xxx читайте в головной статье — RAID-контроллер Adaptec 6405.
Если вам интересны raid-технологии и задачи администрирования raid-контроллеров, рекомендую обратиться к рубрике RAID на моем блоге.
Создание массива RAID Adaptec 6405
При загрузке сервера нажимаем CTRL+A и попадаем в меню контроллера. Нам нужно выбрать Array Configuration Utility:
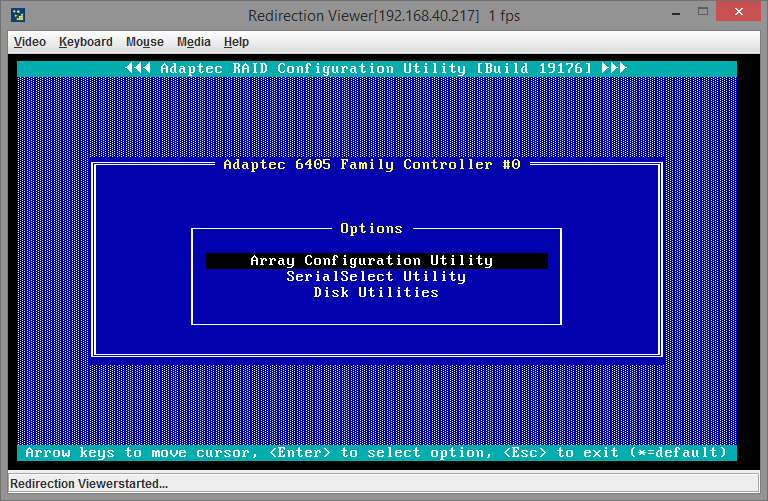
Сначала необходимо зайти в пункт меню Initialize Drives, чтобы сообщить контроллеру какие диски будут использоваться.
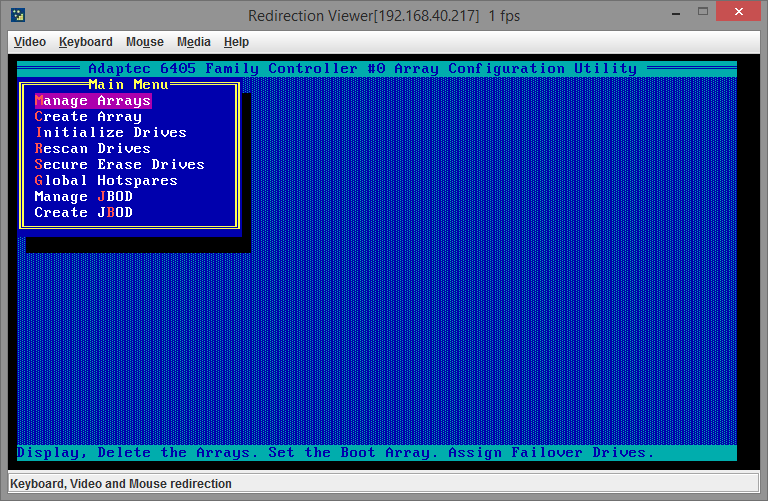
Пробелом нужно отметить каждый диск:
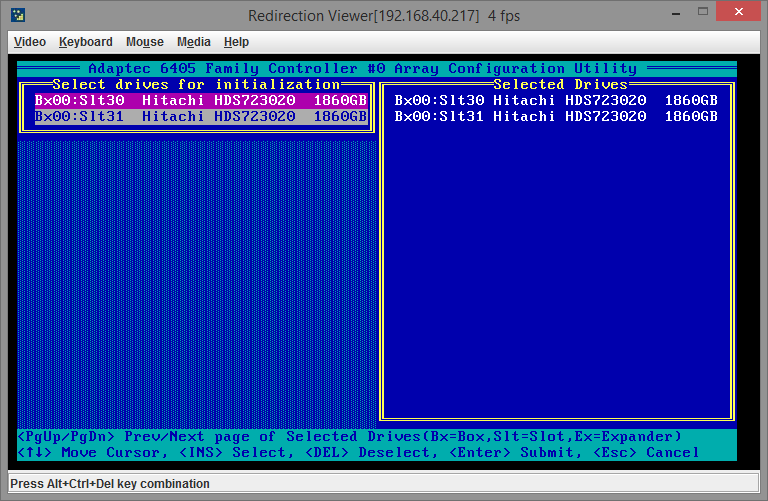
После того как диски выбраны, нажимаем Enter и получаем предупреждение:
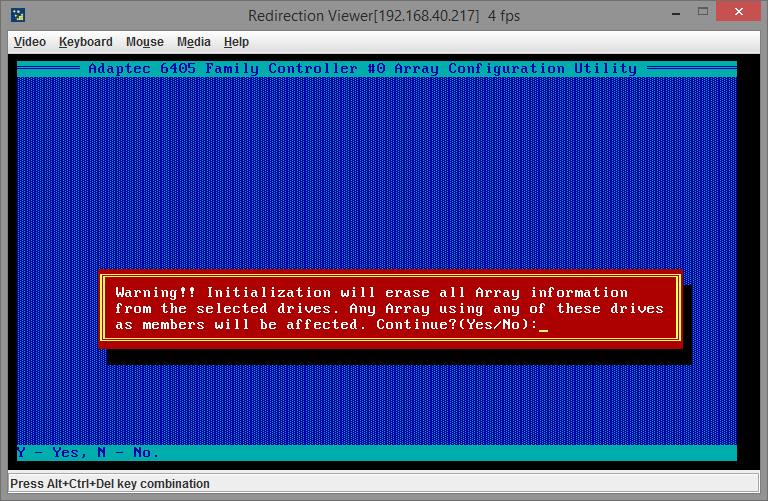 Поскольку данных на дисках пока нет, смело соглашаемся и идем дальше. Следующий пункт, который нам нужен, это пункт меню Создание массива (Create Array). Выбираем его, также пробелами отмечаем нужные диски и нажимаем Enter. Далее нужно выбрать настройки RAID-массива. У меня всего лишь два диска и поэтому я могу создать только RAID уровня 0 или 1, поскольку для других типов массивов нужно больше дисков (подробнее о типах массивов RAID читайте в моей статье Типы RAID-массивов).
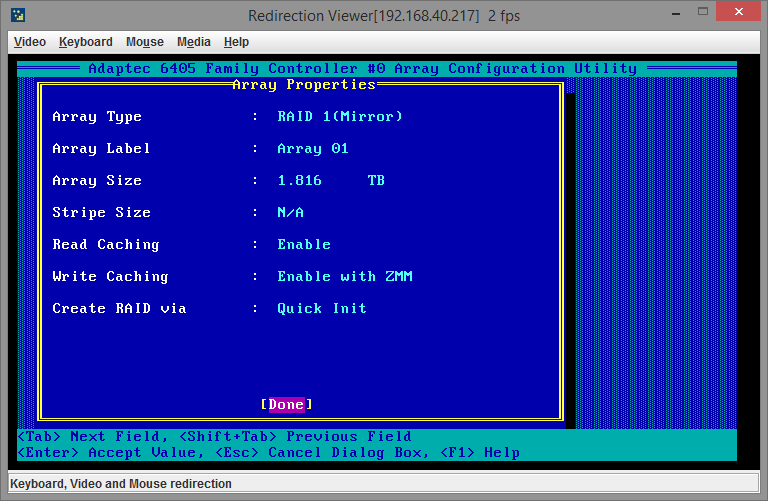
Поскольку данных на дисках пока нет, смело соглашаемся и идем дальше. Следующий пункт, который нам нужен, это пункт меню Создание массива (Create Array). Выбираем его, также пробелами отмечаем нужные диски и нажимаем Enter. Далее нужно выбрать настройки RAID-массива. У меня всего лишь два диска и поэтому я могу создать только RAID уровня 0 или 1, поскольку для других типов массивов нужно больше дисков (подробнее о типах массивов RAID читайте в моей статье Типы RAID-массивов).
- Я остановился на RAID 1;
- Имя массива можете выбрать любое;
- Размер массива тоже лучше не менять, если планируете весь массив отдать под систему. Важный момент — разделы объемом более 2ТБ. О нем скажу чуть позже;
- Кэширование операций чтения оставляйте включенным;
- Кэширование операций записи должно работать только в том случае, если на вашем контроллере есть батарейка и флэш-модуль 1. В противном случае вы можете безвозвратно потерять данные в случае проблем с питанием сервера;
- Если диски новые, то выставляйте метод создания Quick Init. Подробнее о методах создания читайте в официальной документации 2.
В итоге у меня поучились следующие настройки:
Снова получаем предупреждение об использовании функции отложенной записи.
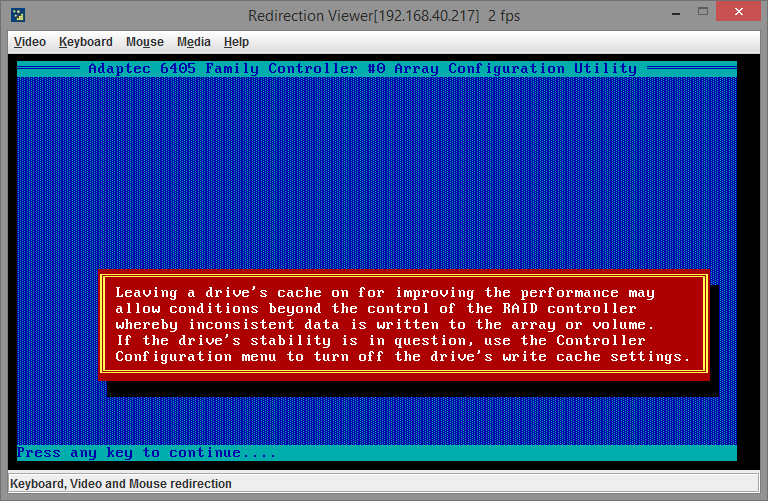
На этом создание массива закончено. Дальше займемся более интересной задачей — заменой вышедшего из строя диска массива.
Замена вышедшего из строя диска
На данном этапе я постараюсь смоделировать выход из строя одного из жестких дисков массива. Поскольку ранее я создал массив типа Raid1, он позволяет сохранить работоспособность при поломке половины дисков. В моем случае половина — это 1 диск (всего их два).
- я отключаю полностью сервер;
- достаю один из дисков и в соседнюю корзину монтирую другой.
В идеале после этого массив должен находиться в деградированном состоянии, но продолжать работать. После подключения третьего диска он не должен автоматически подцепиться к массиву. Во-первых, потому что он не инициализирован; во-вторых, потому что он не был указан как hotspare (диск горячего резерва) при создании массива.
После включения сервера, в bios получаем следующие предупреждения:
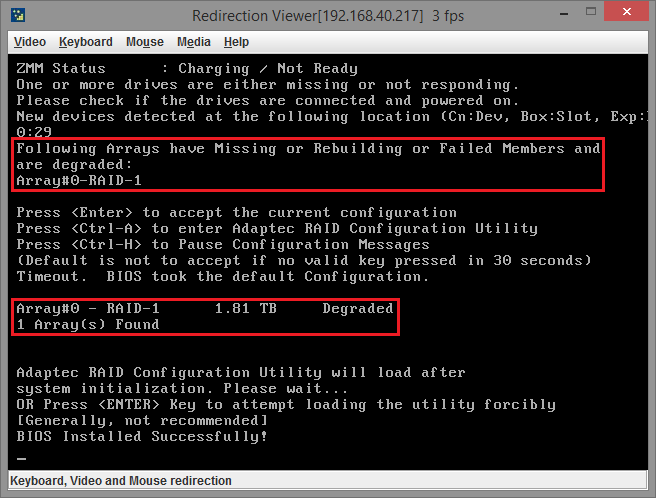
В принципе так оно и должно быть, ведь одного диска в массиве не стало. Кстати, после «пропажи» диска из массива, контроллер стал очень громко и мерзко пищать и ко мне даже стали заходить коллеги и предупреждать о странном шуме из серверной.
Заходим в утилиту управления массивами, смотрим состояние массива в Manage Arrays:
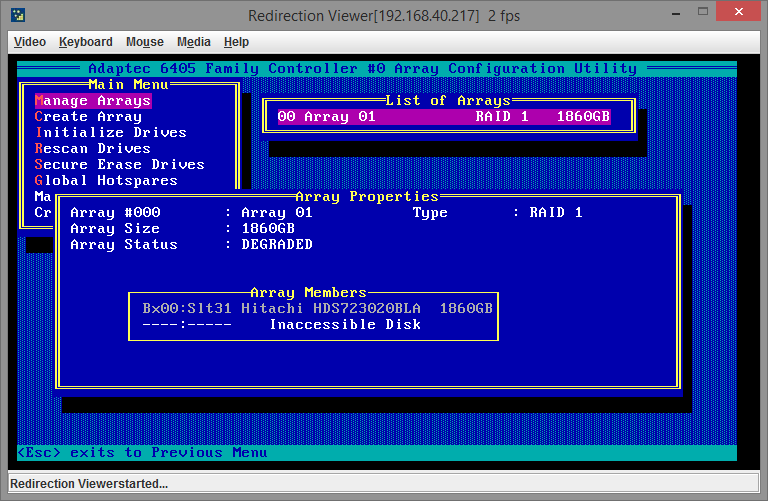
Как видно, одного диска в массиве нет, сам массив находится в деградированном состоянии. Все как и предполагалось.
После этого нам надо инициализировать новый диск. На скриншоте вверху было видно, что в действующем массиве используется один диск в слоте 31, значит новый диск будет в каком-либо другом. Заходим в пункт меню Initialize Drives, инициализируем диск в слоте 29:
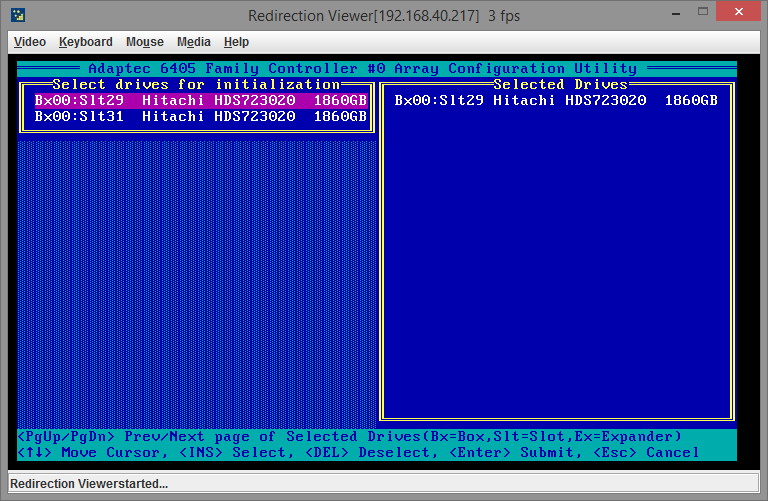
Получаем предупреждение (по-хорошему, к этому моменту у вас уже должны быть бэкапы всей актуальной информации, а сервер выведен на плановое обслуживание, если конечно это возможно):
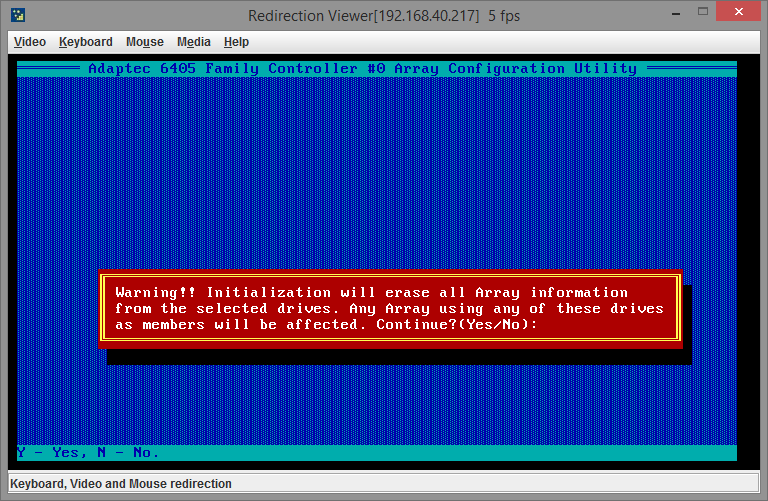
Теперь нам необходимо сообщить контроллеру, что он должен использовать новый диск, чтобы включить его в массив вместо вышедшего из строя. Сделать это нужно через пункт меню Manage Arrays — нажимаем Enter, стрелочками вверх/вниз выделяем нужный массив (если их несколько), нажимаем CTRL+S и попадаем на страницу управления Global Hotspare:
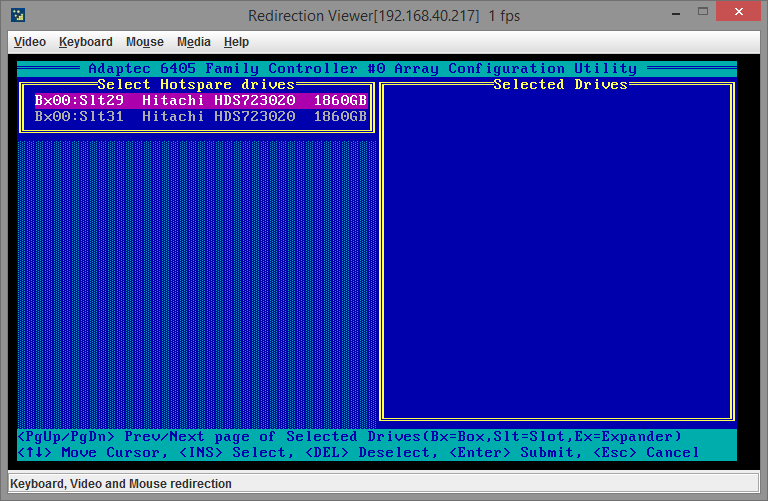
Выбрать вы можете только диски, которые не находятся в данный момент ни в каких массивах. Пробелом выделяем нужный диск:
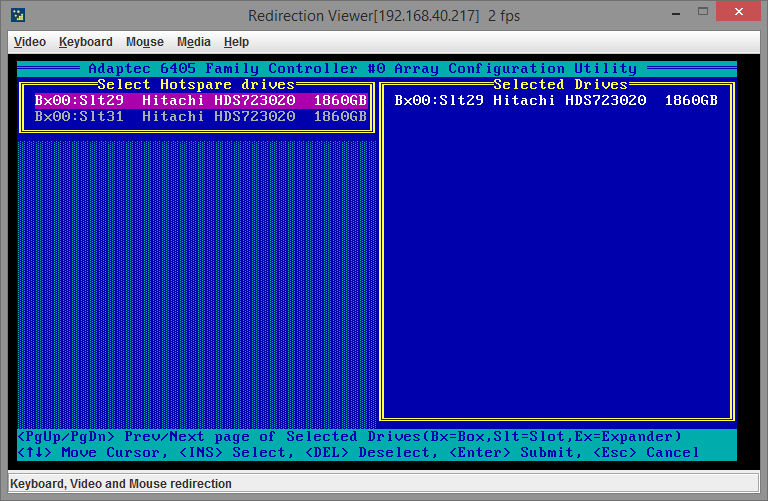
Нажимаем Enter. Выйдет диалоговое окно подтверждения изменения, вводим Y. Поскольку диск мы сделали диском горячей замены, то контроллер должен автоматически сделать его частью массива и сразу же начать процесс ребилда (rebuild array), проверить это можно все также из пункта меню Manage Arrays:
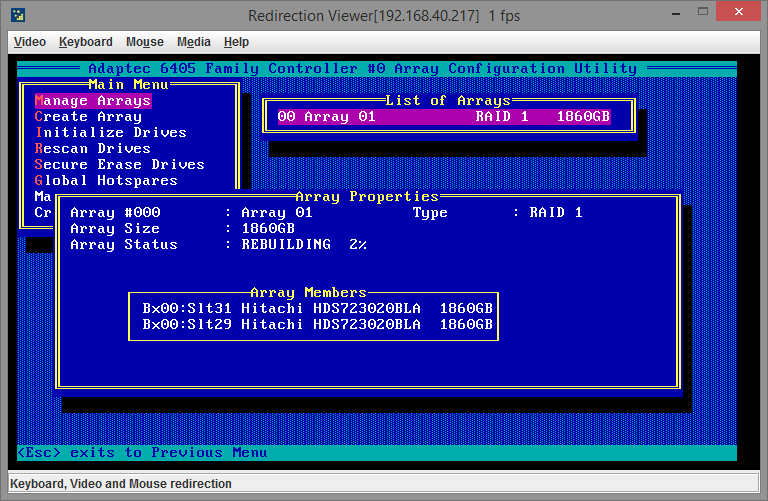
С этого момента вы можете загружать сервер в нормальном режиме и работать дальше. Полный ребилд представляет из себя достаточно длительный процесс и зависит от множества параметров — производительности контроллера/дисков, текущей нагрузки на контроллер/диски и др. Можно сделать вывод, что скорость ребилда значительно изменится в большую сторону, если вы начнете использовать массив сразу после добавления диска. Если есть возможность, лучше дать контроллеру время спокойно завершить перестройку массива и уже после этого давать на него реальную нагрузку 3 (это особенно касается массивов RAID5).
Процесс ребилда физически будет сопровождаться миганием красного светодиода на корзине того диска, который был только что добавлен в массив.

В утилите Adaptec Storage Manager перестроение массива выглядит таким образом:
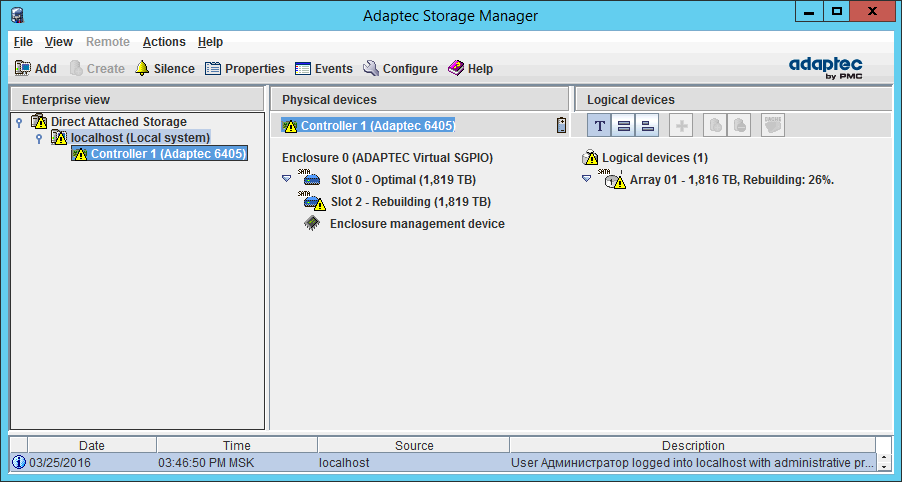
Кстати, утилита запущена с того же самого сервера. На этом обзор задач управления массивами RAID Adaptec 6405 завершен.
Горячая замена диска Adaptec 6405
Горячая замена диска Adaptec 6405 официально поддерживается RAID-контроллером и осуществляется достаточно просто. При этом вам все же лучше будет полностью протестировать этот процесс пока сервер ещё не введен в работу, а также задокументировать эти шаги . Если какой-либо диск (или несколько дисков) все же выйдут из строя на массиве с полезной нагрузкой, вам будет не до выяснения нюансов работы контроллера, нужно будет выполнять замену диска и лучше, чтобы вы были полностью уверены в этом процессе. Для тех, кто поленился сделать для себя подробный гайд step by step главным образом и предназначается эта статья (ну а также разумеется для меня самого и моих коллег).
Подробнее о контроллерах Adaptec серии 6xxx читайте в головной статье — RAID-контроллер Adaptec 6405.
Если вам интересны raid-технологии и задачи администрирования raid-контроллеров, рекомендую обратиться к рубрике RAID на моем блоге.
Горячая замена диска Adaptec 6405
Для начала нужно определить в какой корзине находится диск, который нам нужно заменить. Есть несколько способов это сделать:
1) При должной настройке диск скорее всего сидит в корзине с тем порядковым номером, в какой и должен (судя по информации из ASM. Учтите, что номера корзин начинаются с 0);
2) На всякий случай можно подстраховаться и точно определить корзину. Для этого в утилите Adaptec Storage Manager нажимаем правой кнопкой на нужном диске — Blink physical disk.
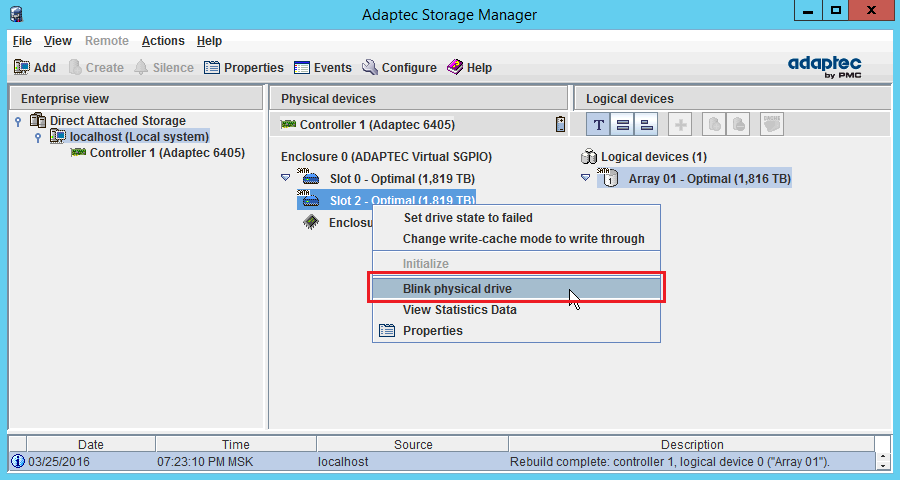
На этом моменте корзина диска должна ритмично замигать красным светодиодом.

3) Ничего не делать и просто через ASM перевести диск в состояние Failed. В этом случае контроллер начнет издавать мерзкий писк и будет непрерывно светиться красный светодиод на корзине с проблемным диском.
Отлично, допустим диск определен (или вы пропустили этот шаг), двигаемся дальше. Теперь нужно подготовить диск к изъятию. Можно конечно его просто выдернуть, но не думаю, что это хорошее решение, тем более когда все можно сделать правильно. К тому же так рекомендуют сделать и в официальной документации 1 .
When removing a drive to simulate a failure or pro-actively replace a questionable drive, it is recommended to use the Storage Manager «set drive state to failed» or CLI / ARCCONF «force fail» option prior to removing the drive. When the drive is marked as failed, it is safe to remove and replace the drive.
Нажимаем правой кнопкой на нужном диске — Set drive state to failed:
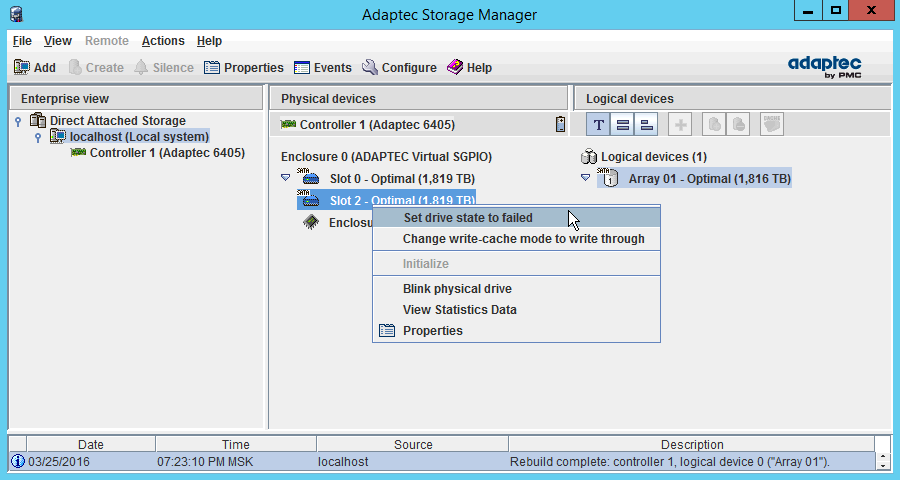
Сразу выскочит предупреждение, что массив будет переведен в деградированное состояние:
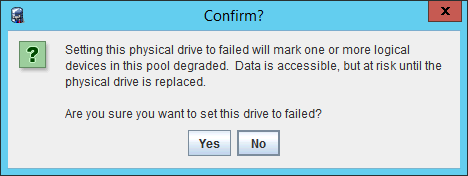
Подтверждаем. В реальной среде вышедший из строя диск скорее всего и так будет в состоянии Failed, а массив в деградированном виде. У меня же эксперимент на тестовой среде и я перевожу диск в нужное состояние вручную. Вот как изменятся показания ПО:
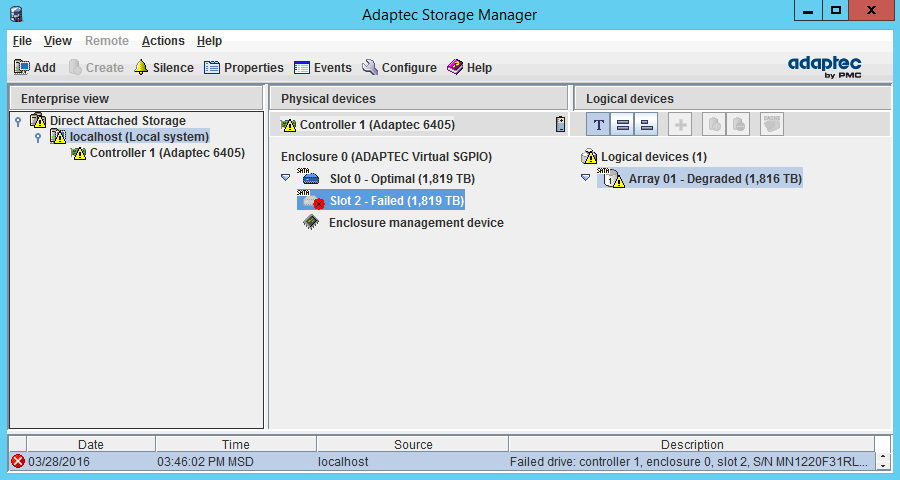
Напоминаю, что массив при этом у меня формально остался в рабочем состоянии, ведь я использую RAID1 и он обеспечивает работоспособность при выходе из строя до половины дисков.
На этом этапе можно смело идти и заменять диск на новый (объем диска вплоть до байта должен быть больше или равен объему других дисков в действующем массиве). Контроллер при этом будет издавать писк (как я и говорил выше), а корзина с проблемным диском сигнализировать о проблеме непрерывно горящим красным светодиодом .
После замены показания ASM будут выглядеть следующим образом:
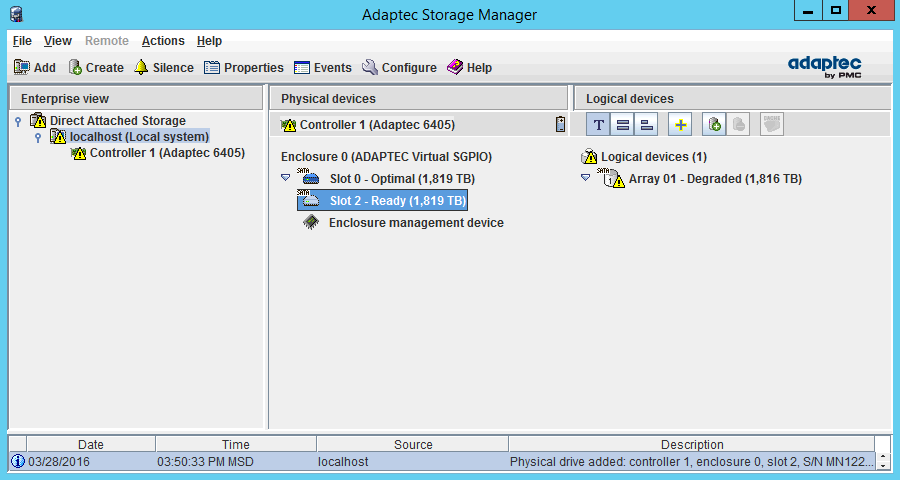
Новый диск готов к использованию и нужно его инициализировать. Нажимаем правой кнопкой на диске — Initialize:
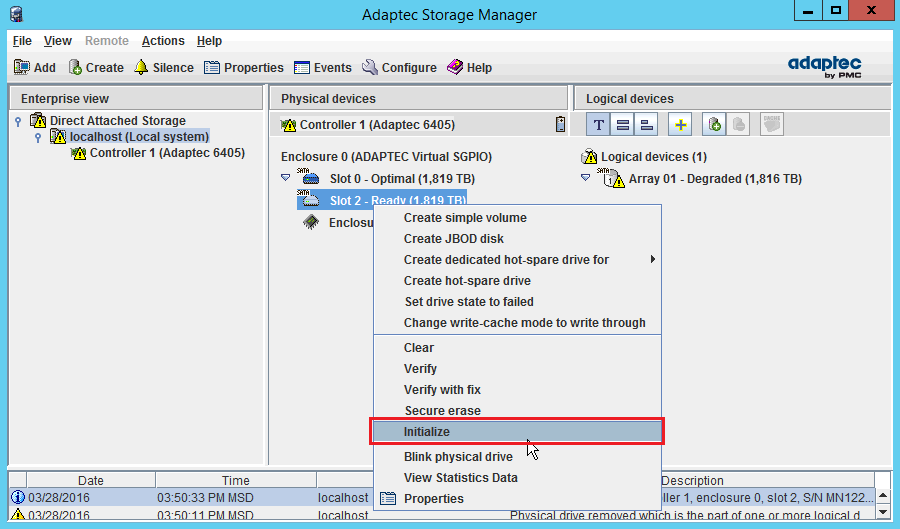
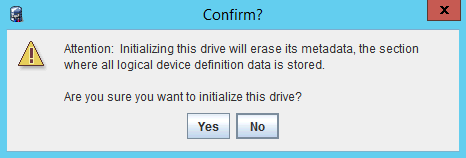
Получаем предупреждение и соглашаемся с ним:
Далее нужно дать понять контроллеру, что он может использовать новый диск вместо недавно «вышедшего из строя» и замененного диска. Для этого нужно сделать новый диск диском горячей замены (правой кнопкой на новом диске — Create dedicated hot-spare drive for):
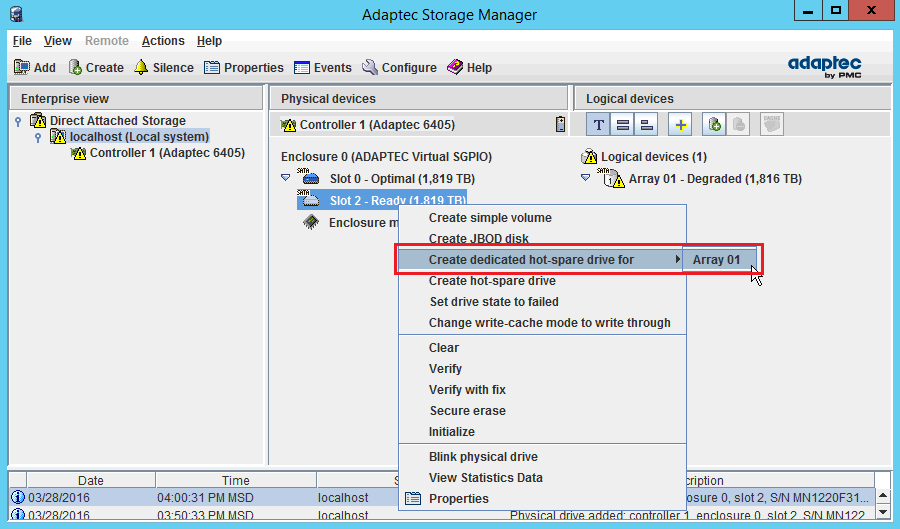
Никаких дополнительных диалоговых окон выскочить не должно, а диск сразу станет частью массива:
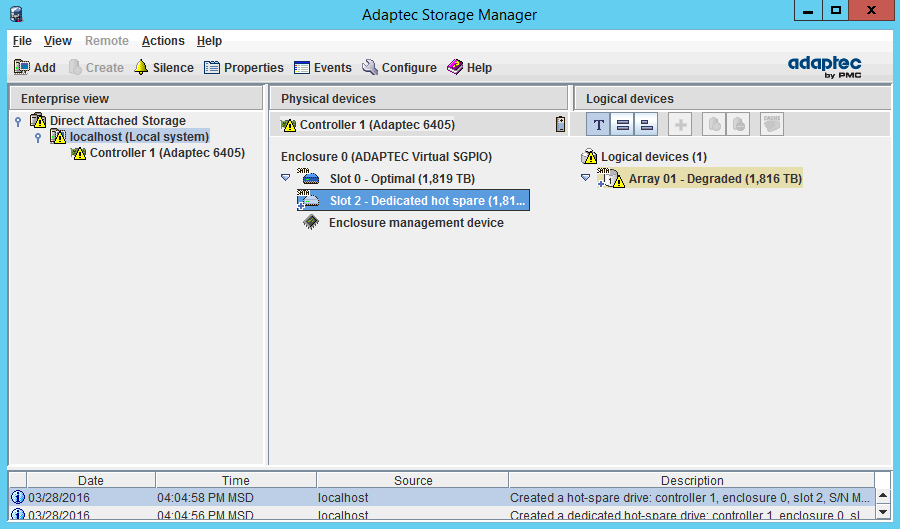
и автоматически запустится процесс ребилда:
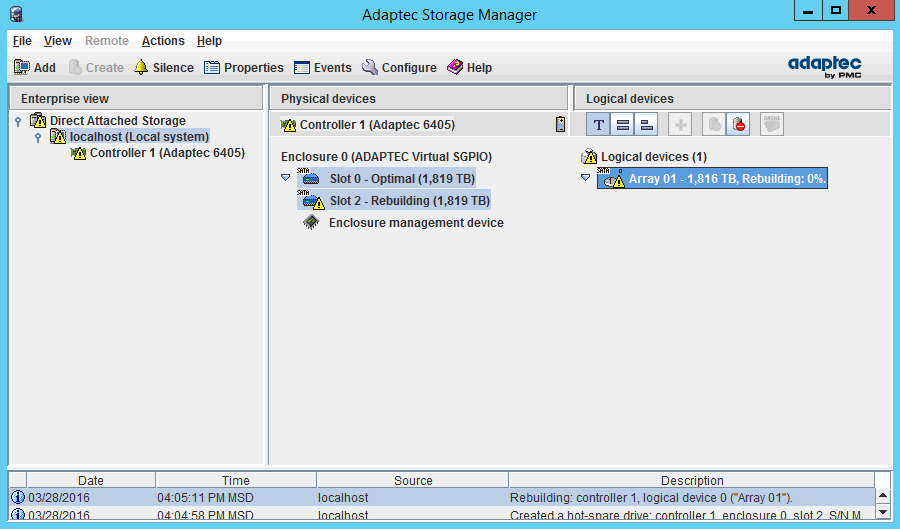
Во время процесса работа сервера может не прекращаться (для наглядности скриншоты ASM я снимал как раз с того же сервера, на котором проводил тестирование). Только учтите один момент: ребилд — достаточно ресурсоемкий процесс и если в вашем массиве небольшое количество низкопроизводительных дисков (а сейчас это фактически любые диски, кроме SSD), то лучше провести технические обслуживание, предварительно сняв полезную нагрузку с сервера. Это особенно касается массивов RAID5 (и им подобных), которые в продакшене вообще использовать не рекомендуется (почему, читайте подробнее в моей статье — Типы RAID-массивов).
Maxview storage manager замена диска

Всем привет, рад, что вы решили посмотреть вторую часть статьи по настройке и созданию raid массивов на контроллере adaptec raid 8885. Сегодня мы будем рассматривать, самые распространенные виды RAID, со всеми нюансами и рекомендациями, которые предписывают производители железа, но в любом случая, я вас призываю не верить на слово и производить свое тестирование со всеми настройками.
И так общие настройки для контроллера посмотрите в первой части настройки adaptec raid 8885.
Инициализация дисков
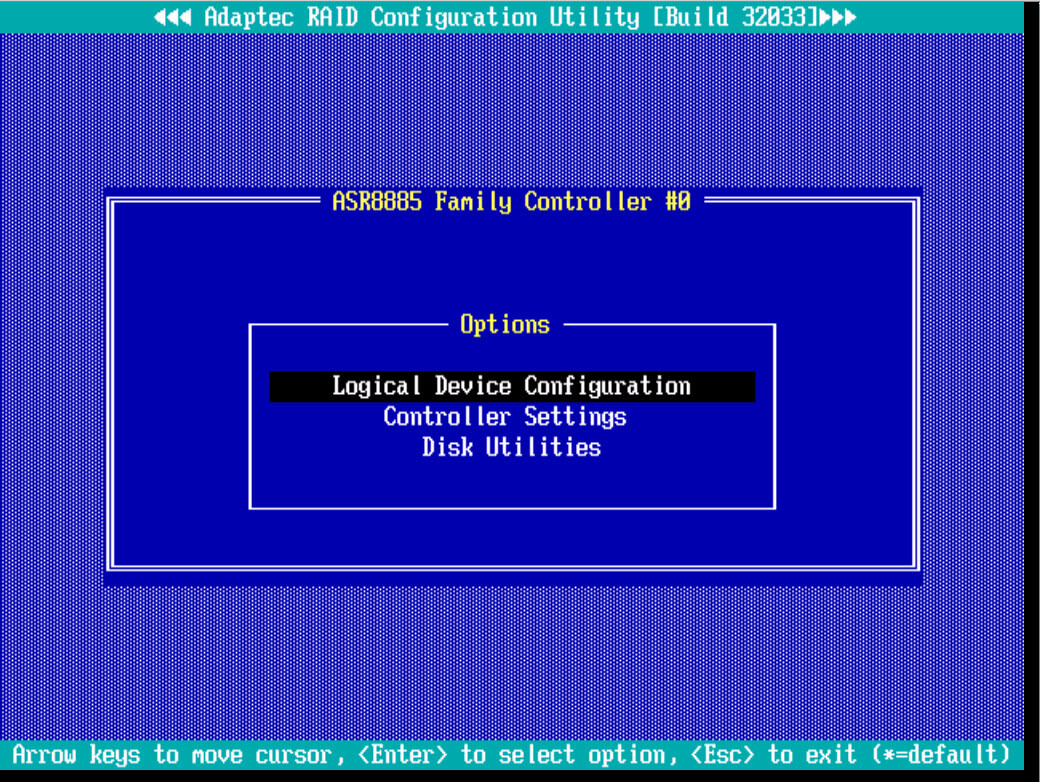
Выбираем в главном меню пункт Logical Device Configuration
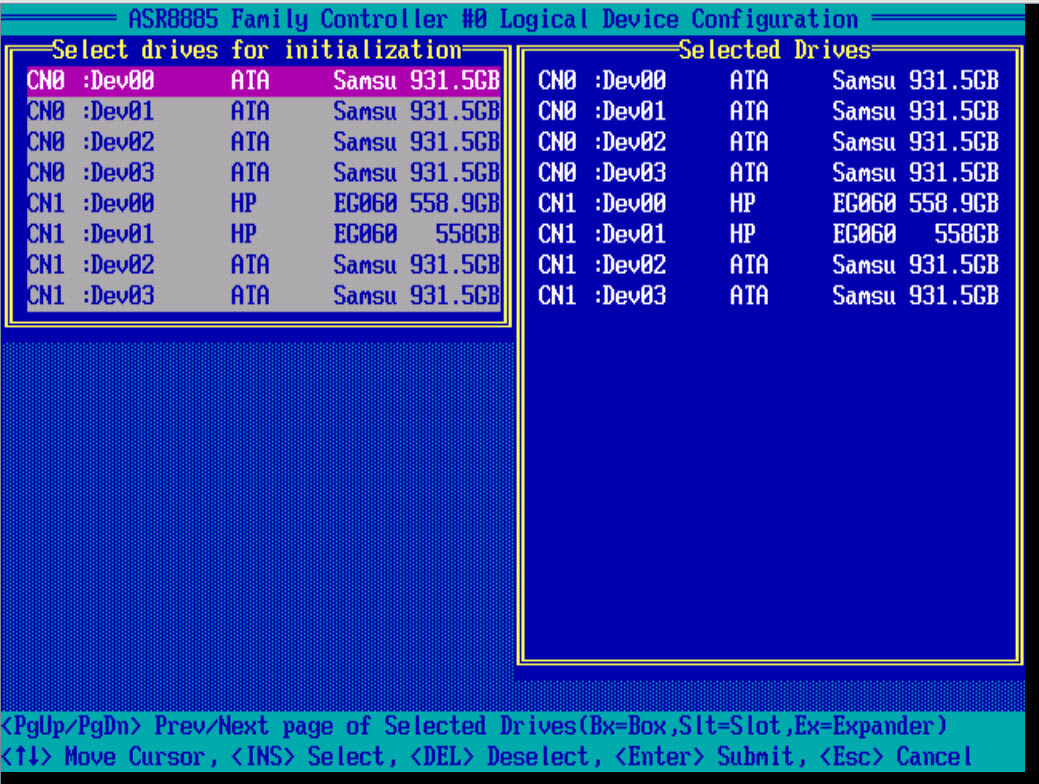
Первым делом, что бы вы могли создать создать raid массив, вам нужно проинициализировать ваши диски, для этого выбираем initialize Drives.

Пробелом выбираем нужный диск, он сразу будет у вас отображаться в правой части окна. Для подтверждения выбора жмем Enter.
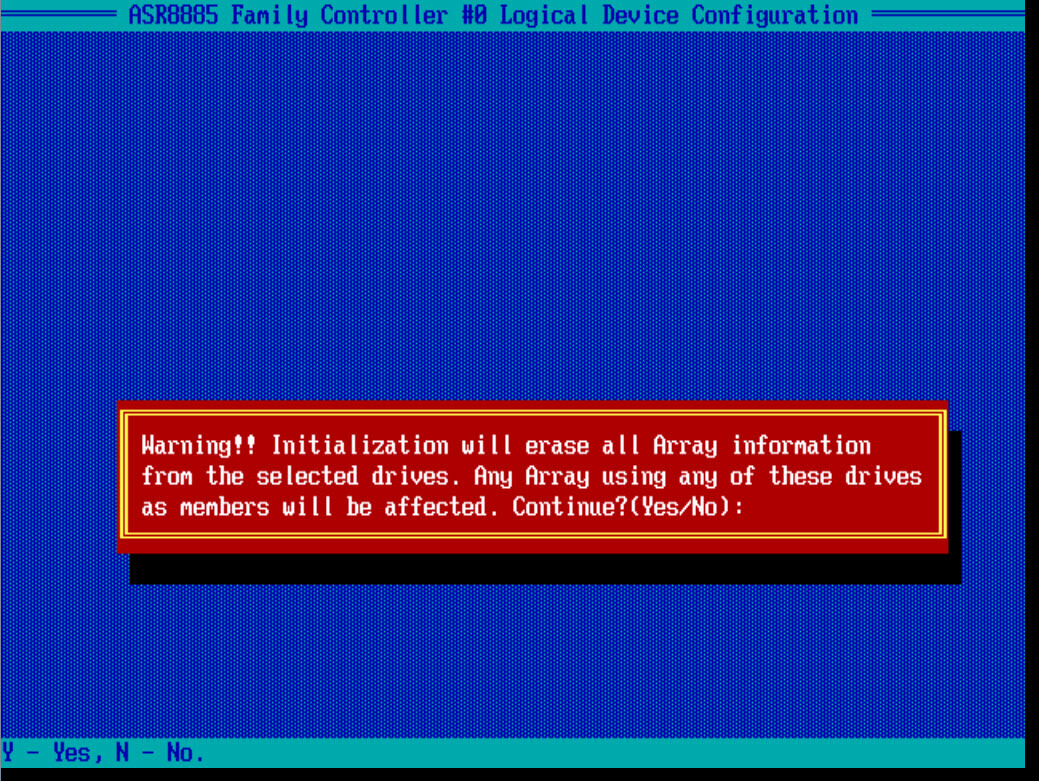
Вас предупредят, что вся информация с дисков будет удалена, жмем Y и соглашаемся
Как создать raid
И так давайте рассмотрим как создать raid на данном контроллере adaptec. После инициализации рассмотрим создание RAID 0 и RAID 1 под систему, почитать по виды RAID можно по ссылке слева. Выбираем Create Array.
Создаем RAID 0
Создать raid массив 0, можно из любого количества дисков или твердотельных SSD. Я выбираю пробелом два HP SAS диска по 600 гб.
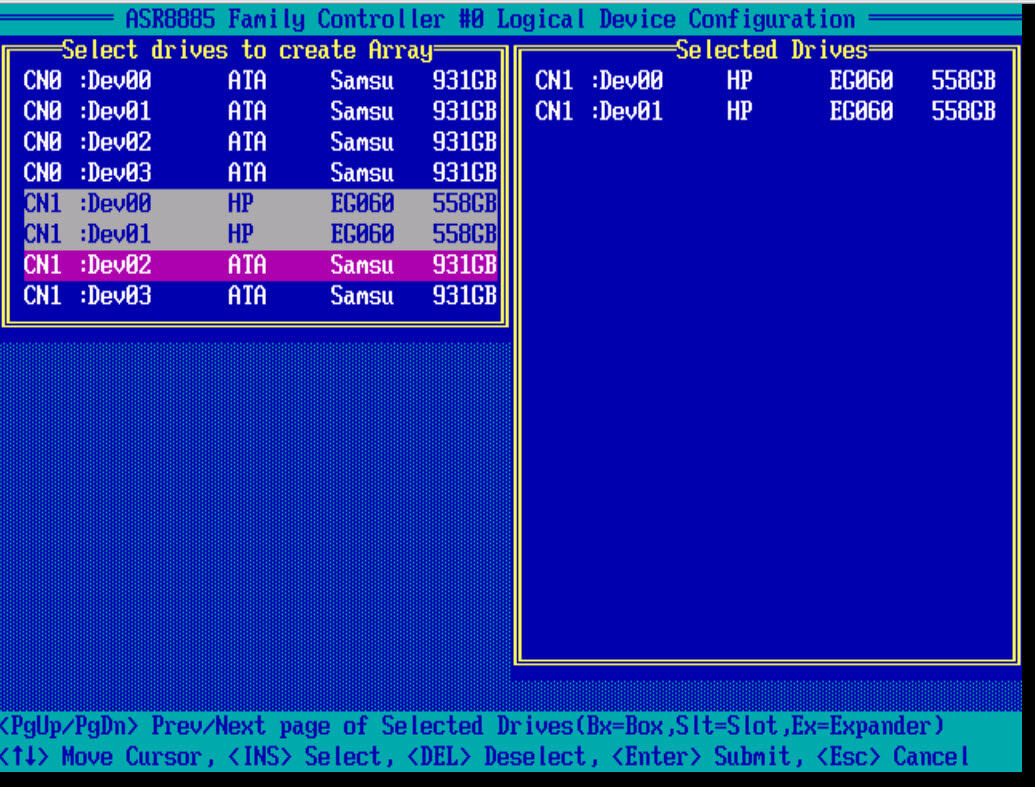
- Выбираем RAID 0
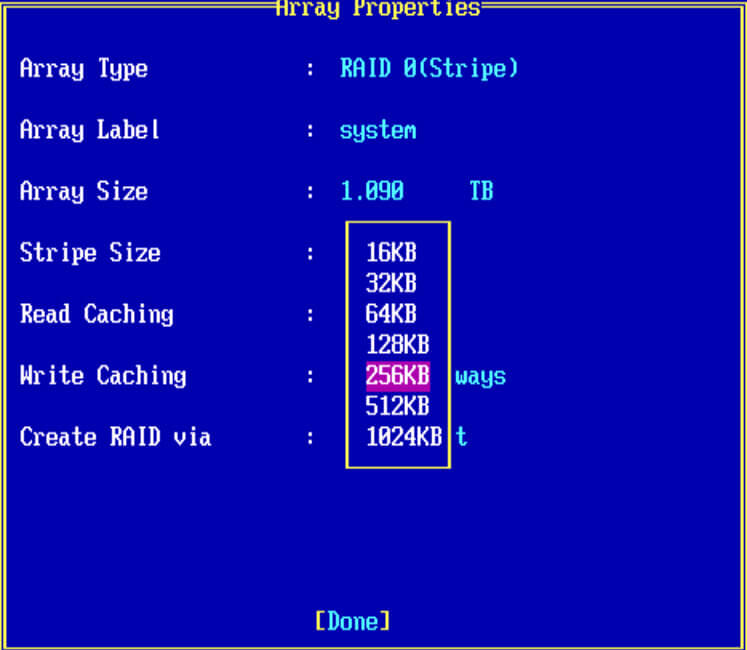
- в Array Label можно написать предназначение массива
- Array Size > указываете нужный вам размер
- Stripe Size > размер блока, может принимать разные значения от 16-1024 кб, все зависит от задачи
- Read Cachin > кэш на чтение
- Write Caching > кэш на запись, про оба кэша в конце статьи.
- Criate RAID via > инициализация массива.
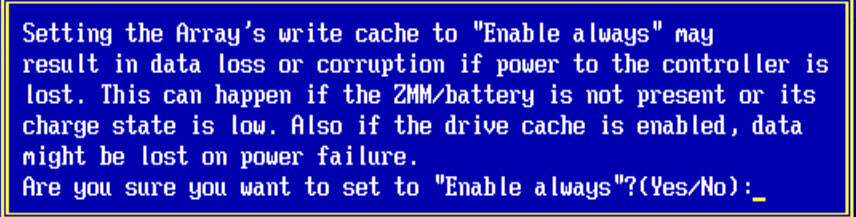
Жмем enter, вас предупредят, что все данные у вас будут уничтожены.
Создаем RAID 1
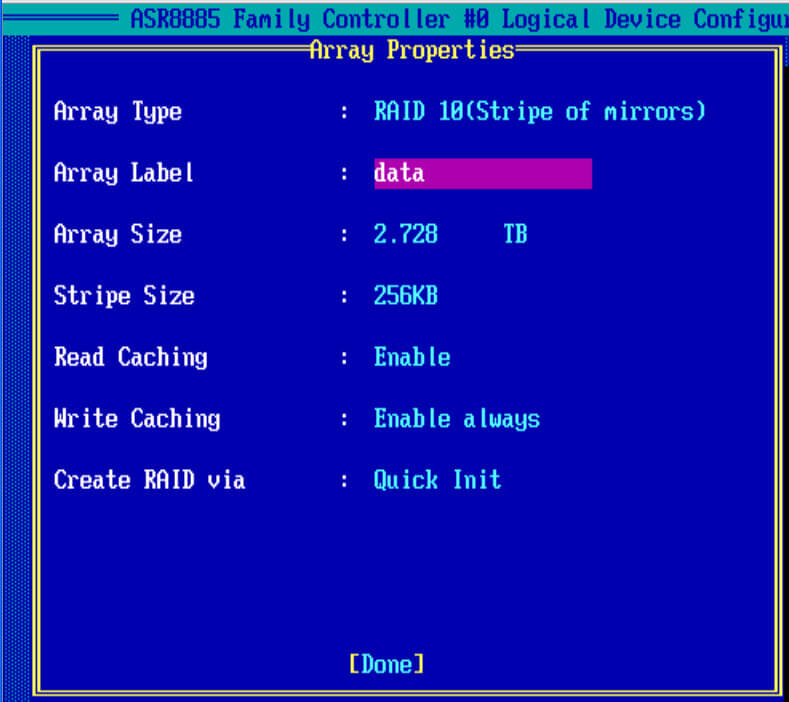
И так, так же как и с 0 рейдом, создадим на контроллере adaptec, зеркальный массив под установку системы. В Array Type выбираем RAID 1 (Mirror), для его создания нужно четное число дисков.
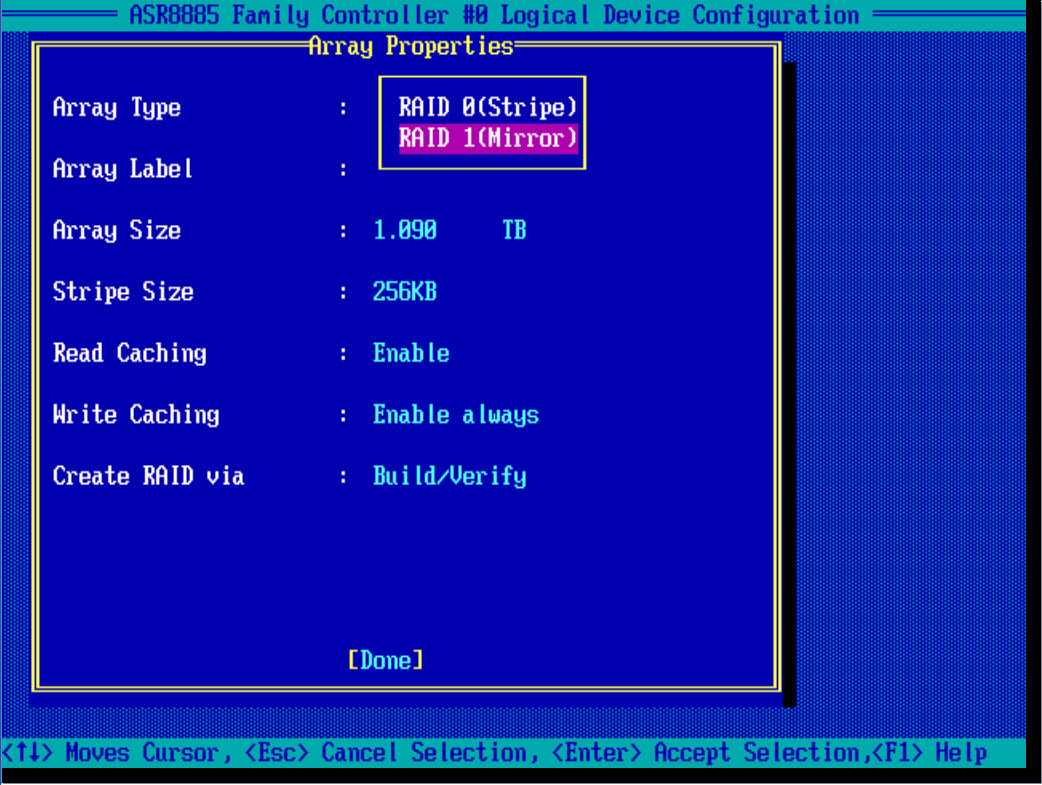
Также задаем описание, у меня это system. Stripe к сожалению задать не удается, режимы кэширования оставим по умолчанию
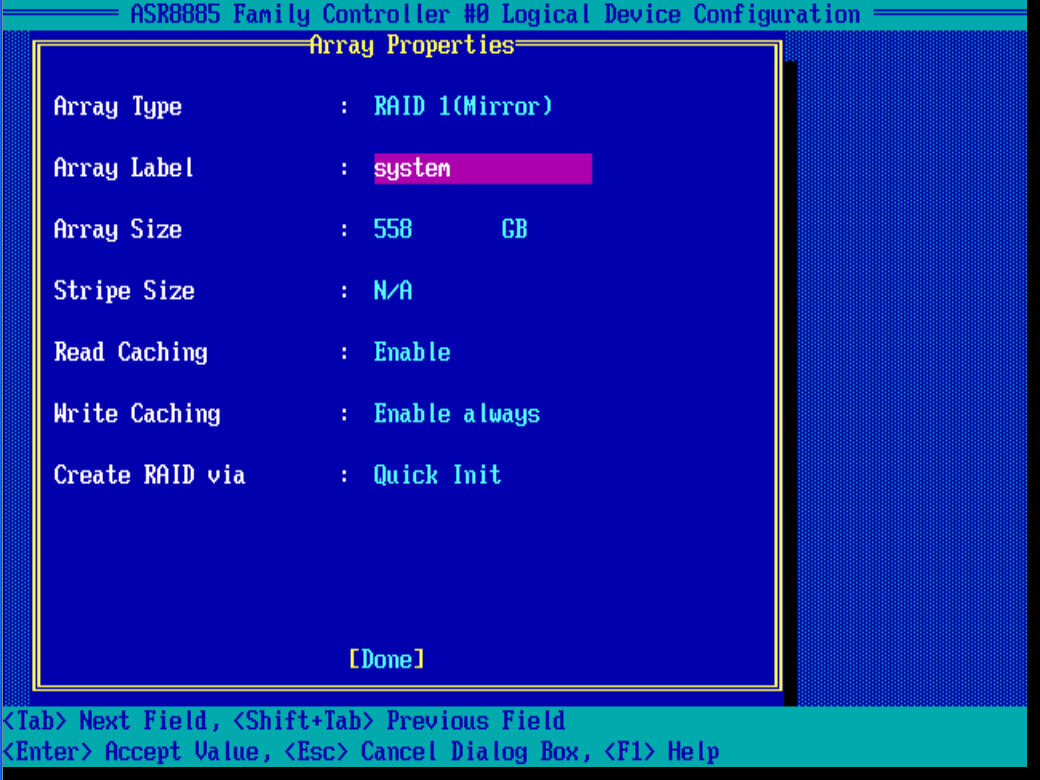
В пункте Create RAID via выбираем Quick init, быстрое формтирование массива.
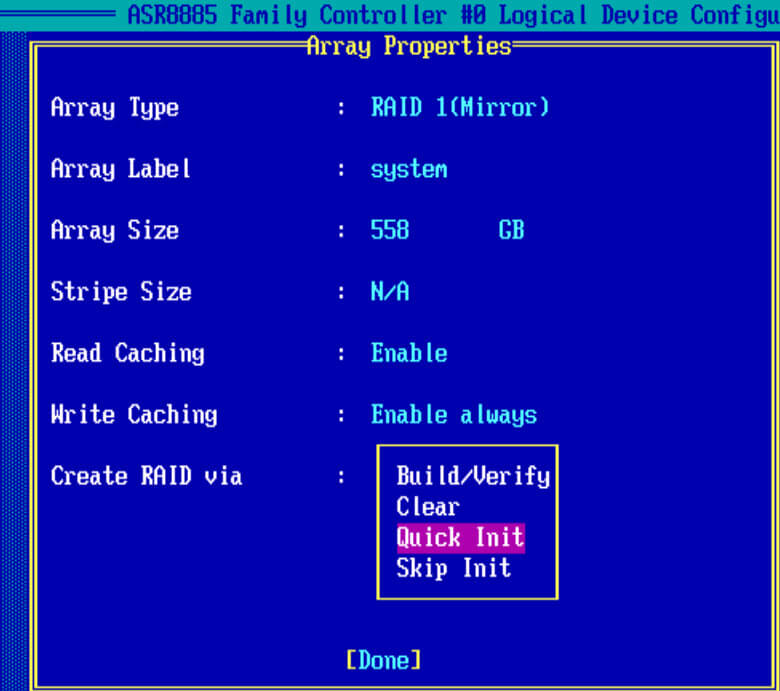
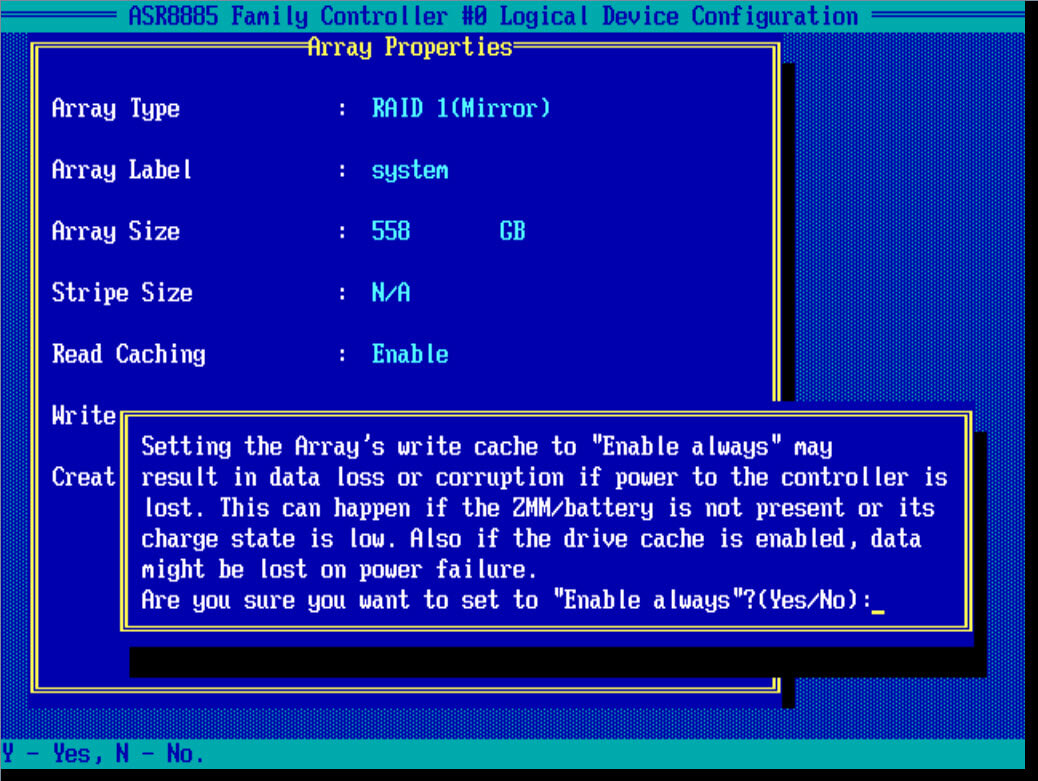
Подтверждаем инициализацию рейд дисков
Для того чтобы, потом изменить настройки созданного рейд массива, следует выйти в меню Main Menu и выбрать пункт manage Arrays. У вас будет отображен список lun в List of Arrays. Как видите у меня есть RAID 1 и он состоит из двух дисков.
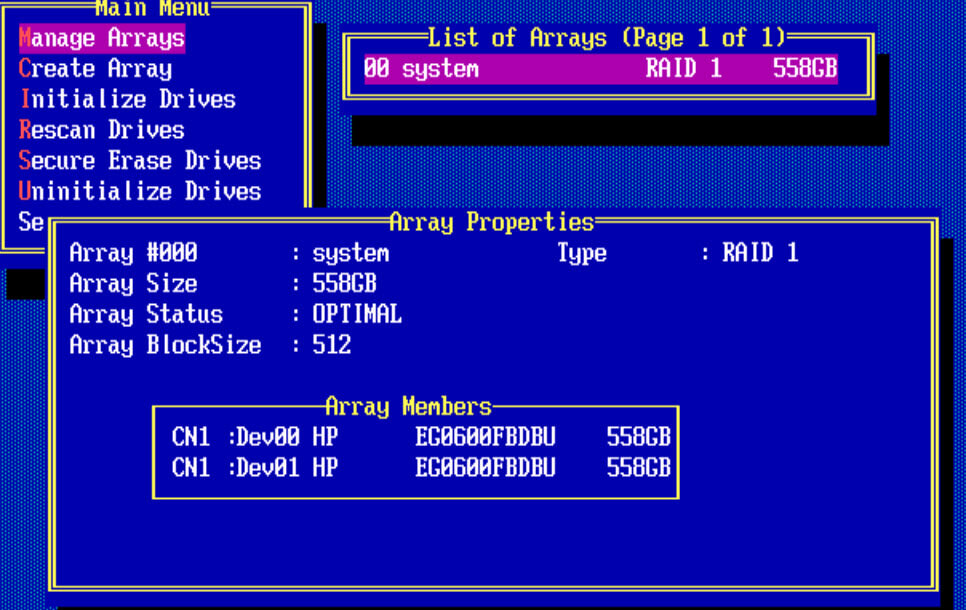
Снизу есть комбинации клавиш с помощью которых можно выполнять редактирование у созданных lunов.

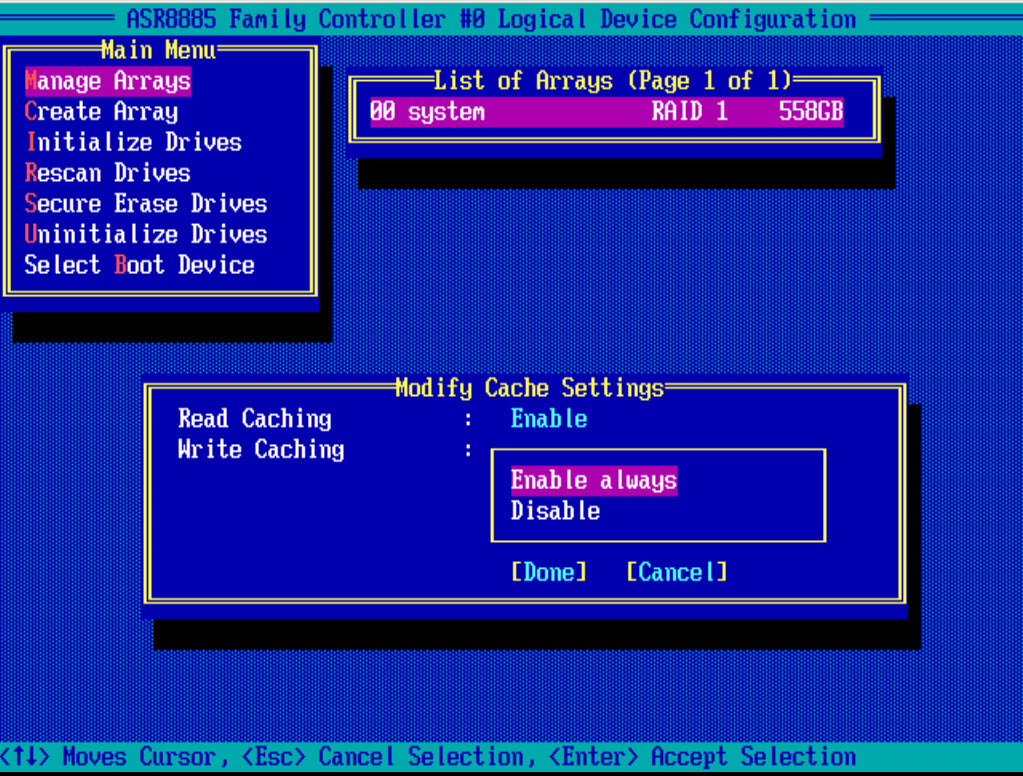
Нажимаем CTRL+R и попадаем в пункт редактирования настроек кэширования. Выбираем значения Tab.
Создаем RAID 5
Самый противоречивый вид, с одной стороны может долго восстанавливаться, а с другой экономит место. Если у вас как и у меня будут ssd твердотельные диски, для тестирования, то советую попробовать пятерку. Для создания рейд 5 требуется минимум 3 диска, формула n-1, где n общее число дисков. В моем случае из 4 ssd и в системе увижу объем трех, четвертый будет скрыт под контрольные суммы.

Выбираем из списка RAID-5

Вот какие настройки у меня получились.

Жмем done. Так как у меня 4 ssd диска, то контроллер предложил, для увеличения производительности отключить на ssd дисках кэш на чтение и на запись.

При желании потом можно включить cache.

Создаем RAID 10
И так, чтобы настроить raid массив 10, нам потребуется четное количество дисков. В моем случае это 6 ssd samsung evo 850. Выбираем диски пробелом и жмем Enter. 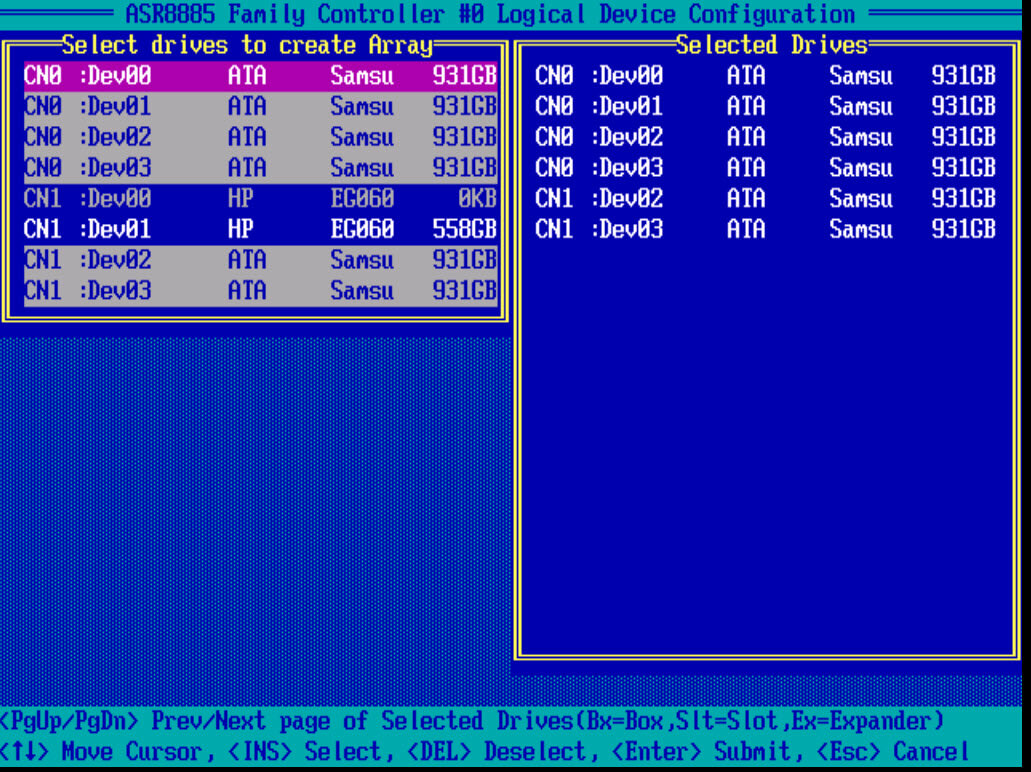
В Array Type выбираем нужное значение.
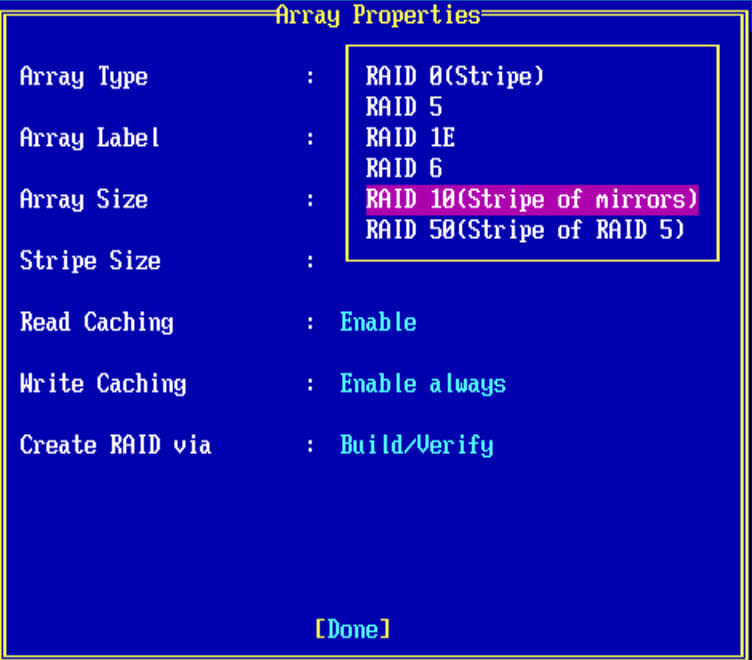
заполняем остальные значения, у меня вышло вот так и жмем done, так же контроллер вам порекомендует отключить для ssd кэширование, советую подтвердить на данном этапе, а потом сравнить во время тестирования с ним и без него.
Описание кэширования LUN
- Read Caching > Данная настройка, по дефолту включена, это позволяет adaptec 8885 контроллеру сохранять данные в кэш на диске. Со включенным кэшом контроллер мониторит процесс чтений данных с пула дисков. Опция Enable MaxCache, аналогична Cache Cade у LSI, и смысл технологии в том, что если у вас есть обычные hdd и есть один или более ssd дисков, то их можно использовать для кэширования hdd массивов, что в десятки раз увеличивает количество операций ввода/вывода (iops)
- Write Caching > так же настройка включена по дефолту. Данный параметр означает. что включен режим write-back, в котором рейд контроллер отсылает ОС подтверждение о том что данные записались, только тогда когда они появились на дисках. При его работе производительность лучше, но данные могут потеряться если у вас будут проблемы с питанием, но если у вас подключена батарейка или флэш-модуль, то кэш сохранится еще на 72 часа, в течении которых вы должны устранить проблему с питанием. Если вы не восстановите электропитание, то контроллер не сможет перенести данные из кэша DRAM, на диски.
Далее можно приступать к установке операционной системы на созданные lun, в моем случае я буду ставить VMware ESXi 5.5.
Maxview storage manager замена диска

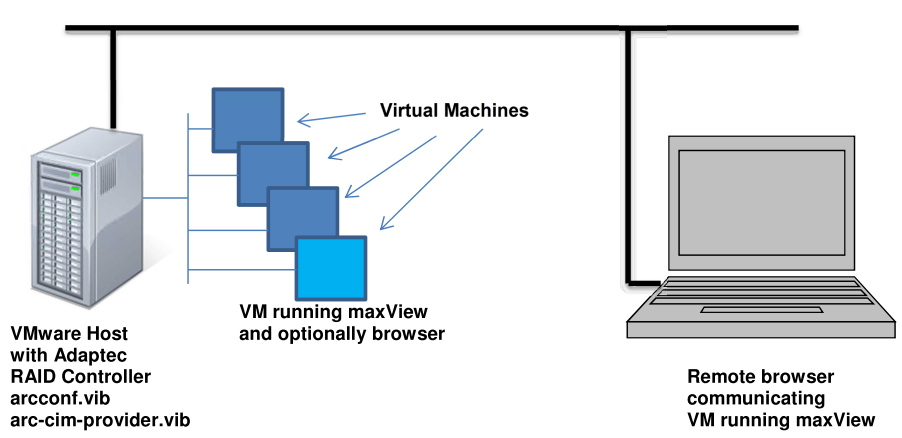
Всем добрый день, продолжаем нашу эпопею с raid контроллером Adaptec 8885, мы с вами остановились на том, что произвели установку VMware ESXI 5.5 на данный рейд контроллер. Почитать можно об этом вот тут (Установка esxi на Adaptec Raid 8885). Следующим этапом, является настроить удобное программное обеспечение, для мониторинга и управления raid массивом и самим контроллером, чем мы и займемся, на все про все мы затратим, около 10-15 минут.
Установка maxView Storage Manager в VMware ESXI 5
Как видите если зайти на вкладку Hardware у нужного хоста в vCenter, то вы не увидите, информацию о дисках или контроллерах, а ведь надо же.
И так на борту у нас ESXi и нам нужно в нем производить мониторинг состояния жестких дисков или ssd дисков. Для этого есть утилита maxView Storage Manager. Давайте ее скачаем. Переходим на сайт производителя , и скачиваем нужную версию, на момент написания статьи это maxView Storage Manager v2.00.21811 for VMware, сам дистрибутив весит порядка 630 мегабайт, очень толстый.Раньше когда был Adaptec CIM Provider, он весил пару мегабайт, но работал через Java, а тут все в браузере, ладно посмотрим.
Когда вышла седьмая серия контроллеров, то была сделана новая утилита maxView в замену Adaptec Storage Manager, так же она еще поддерживает старые контроллеры 6 версии. По сути утилита так же нужна для управления raid и его настройками, но уже работает через веб браузер. Утилита содержит вот такие компоненты:
- CIMOM (CIM Object Manager) для взаимодействия с контроллером
- Web server
- Agent
Установка подразумевает, что у вас есть включенный esxi ssh доступ, далее конектитесь к серверу, я использую утилиту mRemoteNG, очень удобная и позволяет делать много окон в одном большом, советую. Вам в начале нужно проверить есть ли нужный драйвер в системе, делается это командой:

Порядок установки maxview storage manager
В начале при любом раскладе нужно перевести хост виртуализации в режим обслуживания, maintenance mode. Затем если драйвера нет, то ставим его и перезагружаемся. Далее копируем из скачанного архива файлы vmware-esx-provider-arcconf.vib и vmware-esx-provider-arc-cim-provider.vib. Как скопировать файл в esxi читаемс. Кладем файлы в папку tmp.
Тепрь нужно проверить нет ли предыдущих версий данных пакетов
Если нет, то ко. Если есть то удаляем командой
esxcli software vib remove -n arc-cim-provider
после удаления перезагружаемся.
Останавливаем агента CIM watchdog
Все начинаем установку, первого компонента который нам поможет запустить мониторинг raid массива
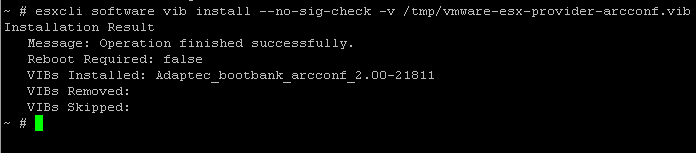
Installation Result
Message: Operation finished successfully.
Reboot Required: false
VIBs Installed: Adaptec_bootbank_arcconf_2.00-21811
VIBs Removed:
VIBs Skipped:
и ставим второй компонент.
Installation Result
Message: The update completed successfully, but the system needs to be rebooted for the changes to be effective.
Reboot Required: true
VIBs Installed: Adaptec_bootbank_arc-cim-provider_2.00-21811
Все перезагружаем хост командой reboot.
В итоге вы должны получить вот такой вид на вкладке hardware, как видите появилась вкладка Storage со всеми дисками.

Как бы все, но не тут то было. Давайте теперь более подробно ознакомимся со схемой работы. Внутри хоста ставим драйвер и CIM провайдера, а вот maxView Storage Manager Agent and Apache Tomcat уже ставятся на виртуальной машине, которая должна лежать на данном хосте, вот такая матрешка. В виртуальной машине должна быть ос linux или Windows, как 32 так и 64 бита. Я честно не знаю зачем Adaptec сделали такую схему с maxview storage manager, раньше с 5 версией Adaptec Raid controller например 5805, было проще хоть и работало все через java.

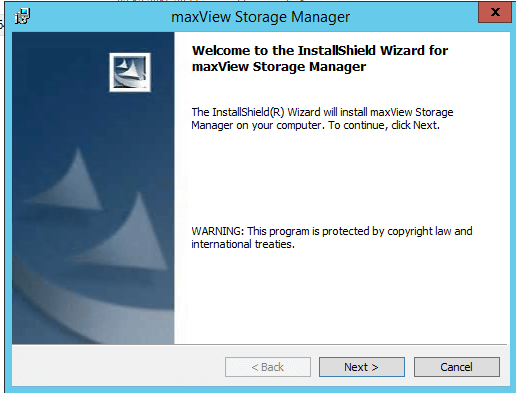
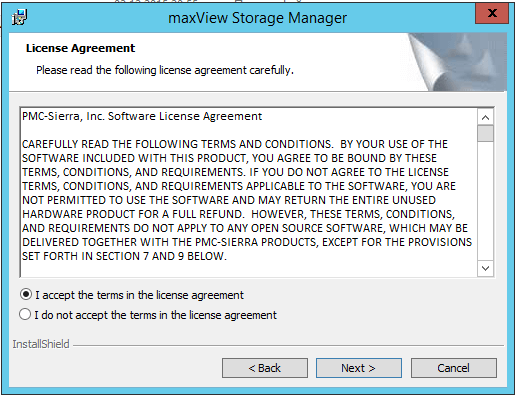
Соглашаемся с лицензионным соглашением и жмем next.
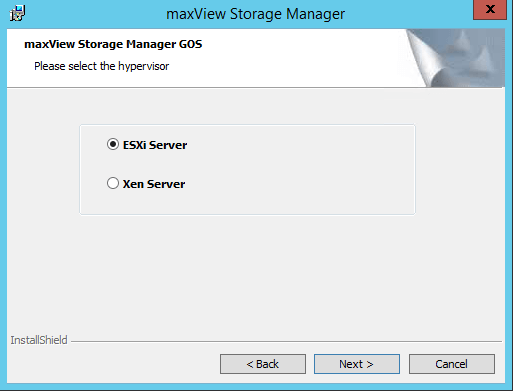
На следующем шаге вас спросят, что вы хотите мониторить, какой гипервизор, выбираем ESXi Server, next.
- ESXI Jost ip Address > адрес хоста виртуализации
- ESXI Host Password > пароль к нему, по умолчанию будет использоваться логин root.
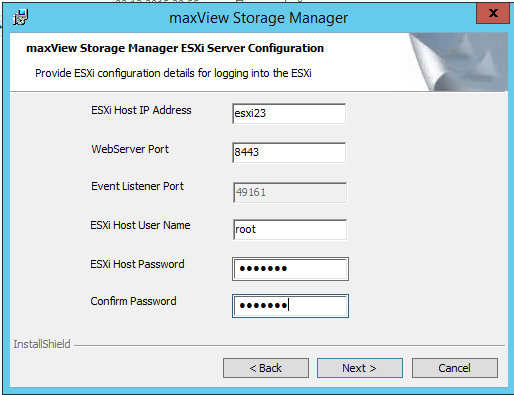
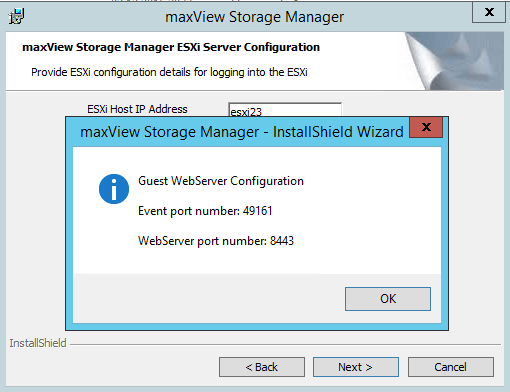
Вас предупредят о выбранных портах для управления Adaptec controller (49161 и 8443, не забудьте их открыть на ос)
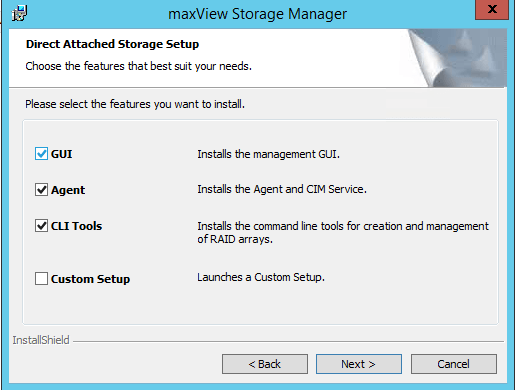
Выставляем компоненты установки, первые два обязательные.
В итоге у вас появится вот такой значок, для локального запуска утилиты, жмем Finish. На этом установка закончена. Далее вам нужно обратиться по адресу
либо если удаленно
https://адрес виртуальной машины:8443/maxview/manager/login.xhtml
Еще у меня в браузере не работало, перезагрузил виртуальную машину все залетало
В идеале у вас должно появиться вот такое окно входа.
Выглядит это так на рисунке во вложении
.
Несколько вопросов:
1. Правильно ли я понял что HotSpare сейчас не задействована?
2. Диск лучше заменить? Как необходимо действовать для замены диска (есть в наличии новый такой же):
а) как сказано в документации (второй рисунок во вложении), сделать ForceOffline, заменить, дождаться ребилда или
б) просто вытащить и вставить новый и все самой поднимется
3. Есть ли смысл заменить проблемный диска на имеющийся hotspare, а новый диск сделать позже hotspare? Как это сделать?
просто скопируй все с дисков
разбери рейд
поменяй диски
и собери рейд сноваа
ну и скопируй обратно
Типа выдернуть два диска, оставить нулевой уровень RAID, установить два новых диска и сделать ребилд?
А затем выдернуть два оставшихся из старых и еще раз ребилд?
Я вижу 2 варианта:
А) Как делал я
1) Скопировал все содержимое массива на промежуточный накопитель вместе с правами NTFS
2) Убил рейд
3) Смонтировал новые диски
4) Создал рейд
5) Залил данные обратно
Долго, но зато новенький чистенький рейд
Вариант Б в моем случае не прошел, т.к. программа управления не могла расширять массив
(2) В таком случае контроллер на новых дисках при первом ребилде возьмет только 400 из 960, а остальная часть останется неразмеченной. Там вроде есть кнопка реконстракт вроде, но это очень долго и рискованно и райд в процессе очень тормозит. Поэтому единственный вариант (1)
(0) сколько новых дисков можно подключить к этому контроллеру, не отключая текущие 4 диска?
(4) ты о чем?
я именно пересобрать массив предлагаю а не менять диски в нем
(6) всего то 1Tb диск надо обычный или usb, чтобы инфу на него скинуть
можно воткнуть еще 4 диска и собрать на них новый массив, затем скопировать данные со старого
(8)+ PCIe (3.0 или 4.0) NVMe
(2) Тоже так хотел сделать, не нашел как массив увеличить до размеров диска, по этому просче скопировать и пересобрать
точнее не скопировать,а снять образ и потом накатить его обратно, там можно пространтсво/размер задать
Контроллер кстати говно
TRIM не пашет нормально
скорость говенная
лучше пару обычных дешманских PCIe 3.0 NVMe по 4Tb взять и только по 2Tb разметить соединив их в софтварный raid 1
(12) Мне было не фиолетово, там система стояла, скуль и базы, это не я придумал, так было, зато все взлетело, как будто так и было
Нафига рейд 10 из ссд делать. Скорости все равно не будет.
(16) для старых ssd на 4к блоках имело смысл
Хороший контроллер при зеркалировании читает диски по очереди,а запись буферизует,деля на фрагменты.
Ну а 0 — это увеличение объема,когда на диске большого объема просто сэкономили
(18) хаха
это делает практически любой контроллер
вся загвоздка (проблема) в скоростях
(19) там еще весь вопрос в возможности параллельного обмена с четыремя дисками сразу.
Megaraid bios config utility замена диска

Добрый день! Уважаемые читатели и гости одного из популярных IT блогов в российском сегменте интернета Pyatilistnik.org. В прошлый раз мы с вами успешно вывели операционную систему Windows из тестового режима. Сегодня я бы хотел написать обзорную, обучающую статью про инструменты управления RAID контроллерами Avago/LSI. Уверен, что начинающим инженерам информация окажется полезной, сразу увидев все популярные утилиты для повседневной работы с данным оборудованием.
