

SQL – декларативный язык программирования. Вы объявляете базе данных о своих намерениях, а способ получения результата она выбирает сама. Это решения об использовании индексов, порядке объединения таблиц или проверки условий. PostgreSQL в стандартном виде не предусматривает вмешательства извне в этот процесс, но показывает последователь выполнения любого запроса.
На практике разработчик часто недоумевает, почему запрос обрабатывается так медленно. Вот четыре причины этого:
Поскольку последний пункт встречается редко при разработке приложения, рассмотрим решение для первых трёх проблем – анализ плана запроса.
- Копирование данных
- Визуализация плана запроса
- Консолидация логов
- Коррелирующие подзапросы против производных таблиц
- Устранение UDF
- DISTINCT с небольшим числом уникальных значений
- Зачем переписывать запросы
- IN против UNION ALL
- Оконные функции против GROUP BY
- И еще
- Структуризация собранной информации
- Усовершенствование представления плана
- Создание UDF
- Получение плана запроса
- Переключение оценщиков кардинального числа
- Форсирование порядка соединения таблиц
- Сжатие данных
- Временные промежуточные таблицы
- Индексные представления
- Заключение
Копирование данных
Если вы не можете улучшить производительность, переписав запрос, вы всегда сможете скопировать необходимые данные в новую таблицу там, где вы сможете предварительно создать индексы и другие полезные трансформации.
Визуализация плана запроса
Что поможет визуализировать необходимую информацию?
Сайт на базе текстового представления плана отрисовывает таблицу с такими данными:
Из минусов этого ресурса отметим:
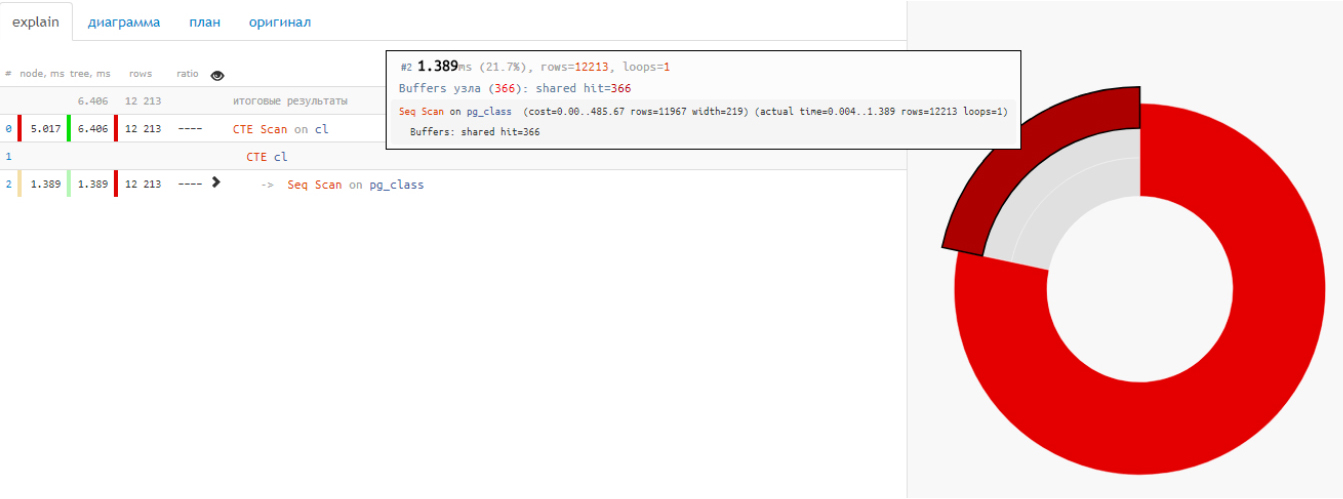
Обратите внимание, что результирующее время плана совпадает со временем отдельного узла CTE Scan:

Это ошибка, ведь Seq Scan отработал 1,389 мс, и для получения времени CTE Scan выполняется вычитание.
Консолидация логов
Для объединения информации PostgreSQL предоставляет дефолтный инструмент pg_stat_statements. При использовании этого модуля возникают такие неудобства:
С учётом копипасты в масштабах выгоднее написать собственный коллектор, который по SHH обращается к серверу PostgreSQL, запускает там tail и получает зеркальный трафик логов. Причём эта информация доступна онлайн. Для сохранения ресурсов коллектор поддерживает соединение и периодически проверяет pg_stat_activity и pg_locks.
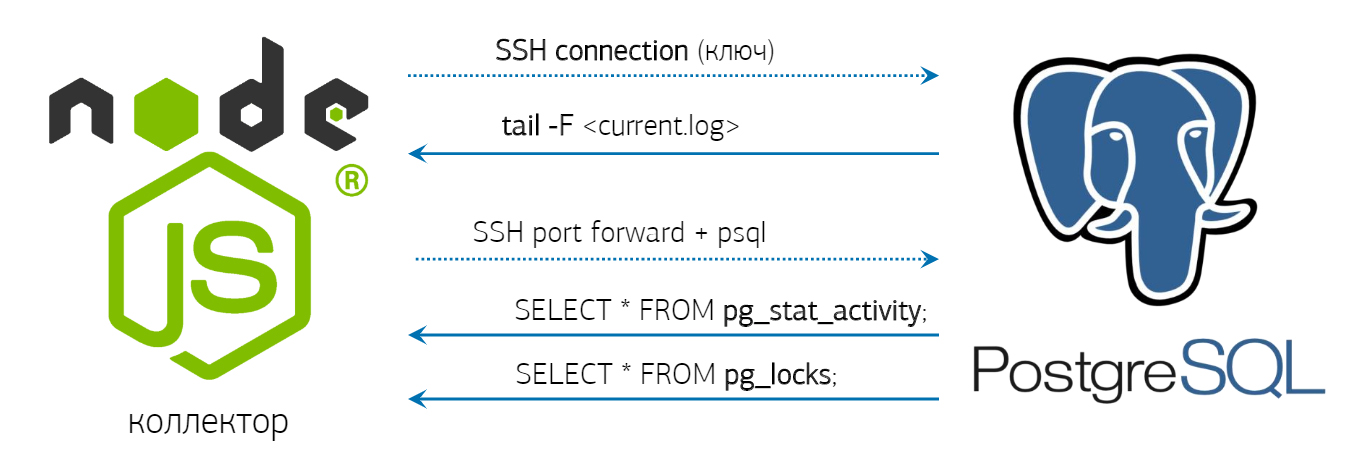
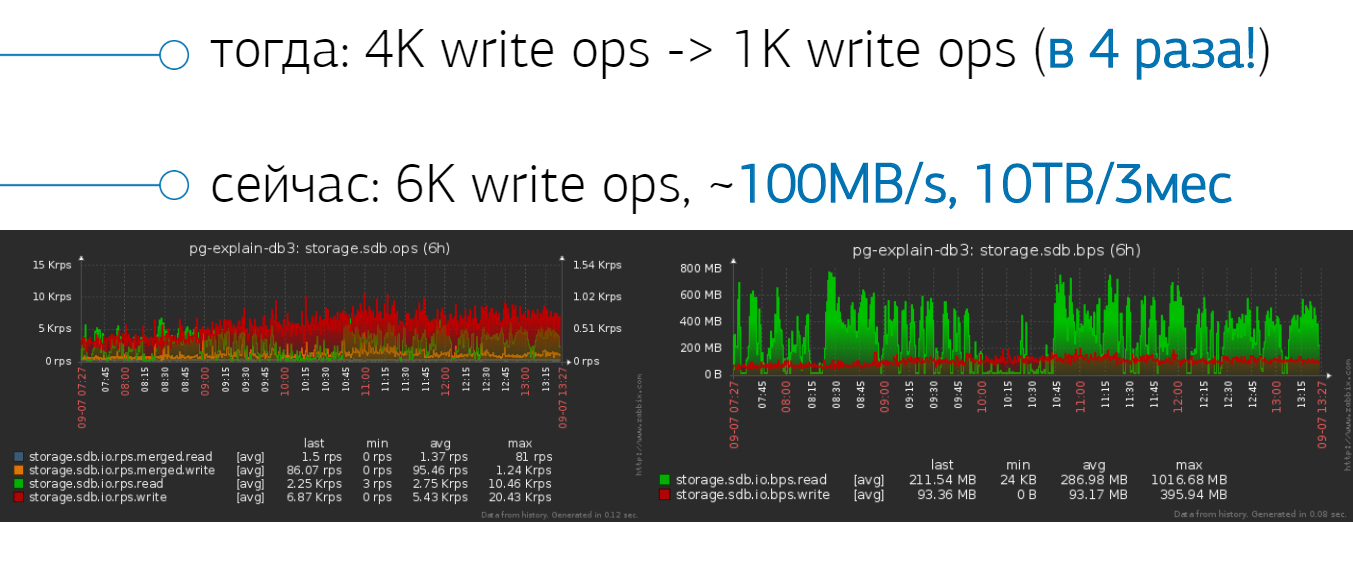
Благодаря COPY-потоку удалось снизить нагрузку с 4 тысяч операций в секунду до 1 тысячи. При дальнейшем увеличении нагрузки до 6 тысяч потоковая запись идёт со скоростью 100 мегабайт в секунду. Сколько разработчик будет разбираться с проблемой? За три месяца уж справится с любым сложным запросом, при этом размер архива оставит 10 терабайт.
Коррелирующие подзапросы против производных таблиц
Многим нравится использовать коррелирующие подзапросы, поскольку их логику зачастую легко понять, однако переход на запросы с производными таблицами часто дает лучшую производительность в силу их теоретико-множественной природы.
Устранение UDF
UDF зачастую провоцирует плохую производительность запросов, благодаря навязыванию последовательных планов и приводя к неточным оценкам. Одним из способов возможного улучшения производительности запросов, которые вызывают UDF, попытаться встроить логику UDF непосредственно в основной запрос. С SQL Server 2019 это будет иногда делаться автоматически во многих случаях, однако Брент Озар показал, что вы можете иногда вручную встроить функциональность UDF, чтобы получить наилучшую производительность.
DISTINCT с небольшим числом уникальных значений
Использование оператора DISTINCT не всегда является самым быстрым способом вернуть уникальные значения в наборе данных. В частности, Paul White использует рекурсивные CTE, чтобы вернуть отличные значения на больших наборах данных при относительно небольшом числе уникальных значений. Это отличный пример решения проблемы с помощью очень креативного решения.
Зачем переписывать запросы
Я часто работаю в условиях, когда при настройке производительности нет возможности менять индексы или параметры сервера. Я обычно сталкиваюсь с подобными сценариями, когда имею дело с:
Хотя всегда предпочтительней решать проблему производительности в корне, иногда единственным способом, которым я могу воспользоваться для решения проблемы в подобных условиях, является переписывание запросов.
Я решил написать этот краткий пост, потому что хотел бы изначально иметь такой ресурс. Иногда, возможно, в попытках найти способ переписать SQL-запрос данный пост даст толчок вашим творческим идеям.
Итак, вот список 12 методов без определенного порядка, который вы можете использовать, чтобы переписать ваши запросы с целью улучшить их производительность.
IN против UNION ALL
При фильтрации строк данных по множеству значений в таблицах с перекошенными распределениями и непокрывающими индексами запись вашей логики через множество операторов, объединяемых с помощью UNION ALL, иногда производит более эффективный план выполнения, чем простое использование IN или OR.
Оконные функции против GROUP BY
Иногда оконные функции несколько злоупотребляют использованием tempdb и блокирующими операторами, чтобы выполнить свою работу. Я всегда предпочитаю их из-за простого синтаксиса. Но если страдает производительность, вы обычно можете переписать их в старомодной манере с GROUP BY, чтобы улучшить производительность.
И еще
Не следует считать этот список исчерпывающим. Существует много других способов переписать запросы, и не все из них будут работать постоянно.
Ключевой момент — это думать о том, что знает оптимизатор запросов о ваших данных, и почему он выбирает тот план, который выбирает. Как только вы поймете, что он делает, вы сможете начать создавать различные варианты переписывания запросов для решения проблемы производительности.
Структуризация собранной информации
Что делать с миллионами сохранённых планов? Без структурирования ничего не понятно, поэтому нужна такая информация о запросе:

Отсюда легко отобразить пользователю, когда и на каком сервере базы выполнялся запрос, PID процесса и другие данные, которые вы выбрали при конфигурации log_line_prefix.
Помимо именования, запросы разделяют по серверам и дням, а также рассматривают в пределе шаблона (сокращённого плана), приложения или метода и узла. Шаблоны уменьшают количество анализируемых объектов в несколько раз, например, из 1121 получаем 80. С помощью timeline вы находите общие паттерны поведения и сопоставляете с действиями.

При анализе планов важно обратить внимание на следующие показатели:
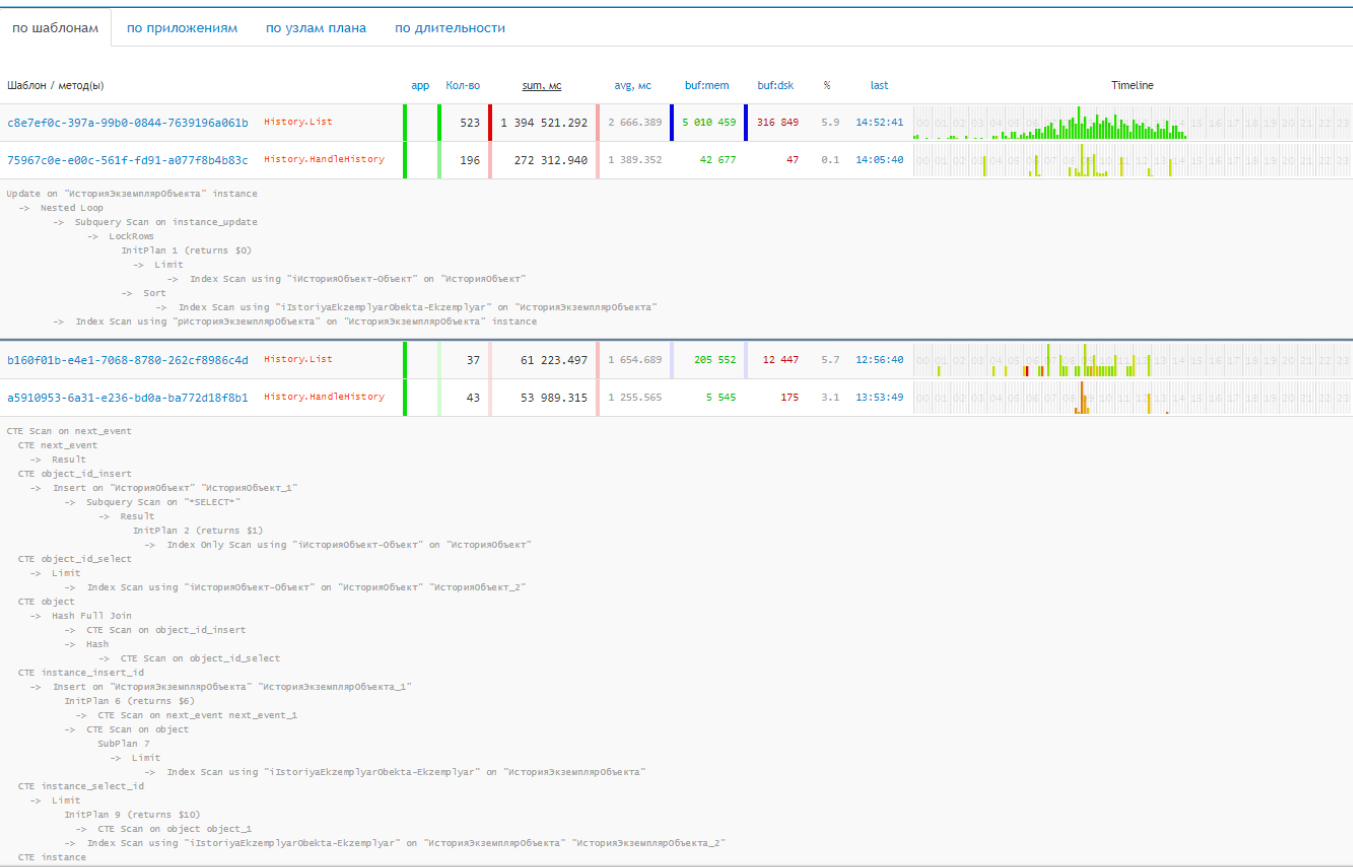
Выяснилось, что подобный мониторинг нужен и по отдельным узлам, а также по динамическим вроде CTE scan и Subquery.
На основании полной информации в компании сделали подсказчик, который рекомендует разработчику те или другие решения, благодаря выявленным паттернам поведения:

Усовершенствование представления плана
Чтобы качественнее анализировать планы запросов, компания «Тензор» реализовала собственный сервис для внутреннего использования, но позднее появилась публичная версия. Разработчики сделали парсер планов, добавили правильный анализ CTE-ресурсов и буфера, а также наглядную визуализацию.
Слева на полном плане отображаются показатели, как и у предыдущего сервиса, а справа – потреблённые данные. Для большей наглядности тело плана сократили и добавили диаграмму распределения времени по операциям.
В таком представлении отчётливо видно, что извлечение 12 тысяч записей заняло только четверть времени, а остальное ушло на CTE.
С маленькими планами проще, а когда план включает десяток операций, то диаграмма облегчает жизнь в несколько раз. Благодаря ей вы видите, что больше половины общего времени заняло последовательное сканирование таблицы, хотя вернулось 57 тысяч строк:
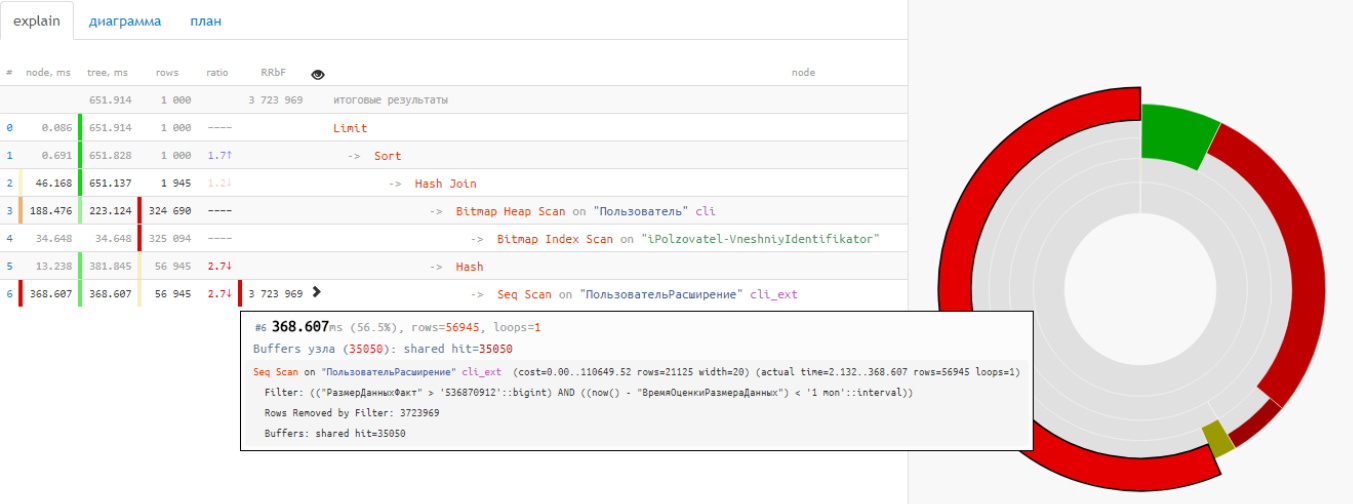
Проблема кроется в фильтрации более 3 миллионов записей по пути. Рассматривая время выполнения отдельных узлов, вы делаете выводы, где допустили ошибку при прогнозировании.
При разборе распределения ресурсов CTE возникли сложности. Для иллюстрации рассмотрим пример:

Создали таблицу, прочитали оттуда две записи: первую и со смещением на 100. План запроса выглядит так:
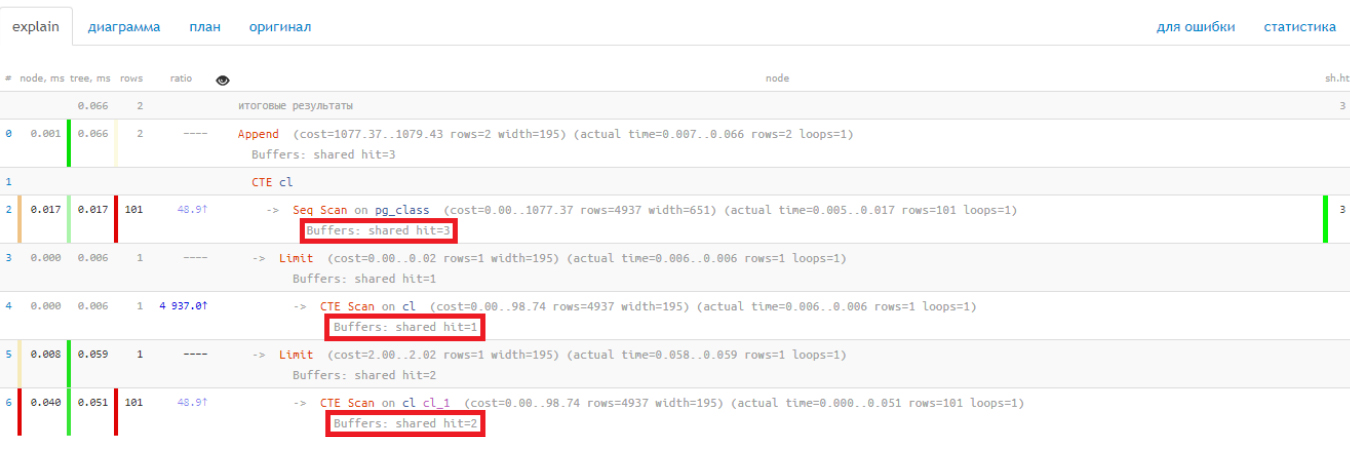
Посмотрите на количество потреблённых данных. На последовательное сканирование ушло 3 страницы, первый CTE scan занял 1, а второй – 2. Покажется, будто потребление составило 6 страниц, но в действительности это те же 3 страницы, что и в Seq scan.
Получается, распределение ресурсов в плане вовсе не дерево – ациклический направленный граф. Для понимания взгляните на схему выполнения предыдущего запроса, где видно, что ресурсы расходятся на 2 потребителя:
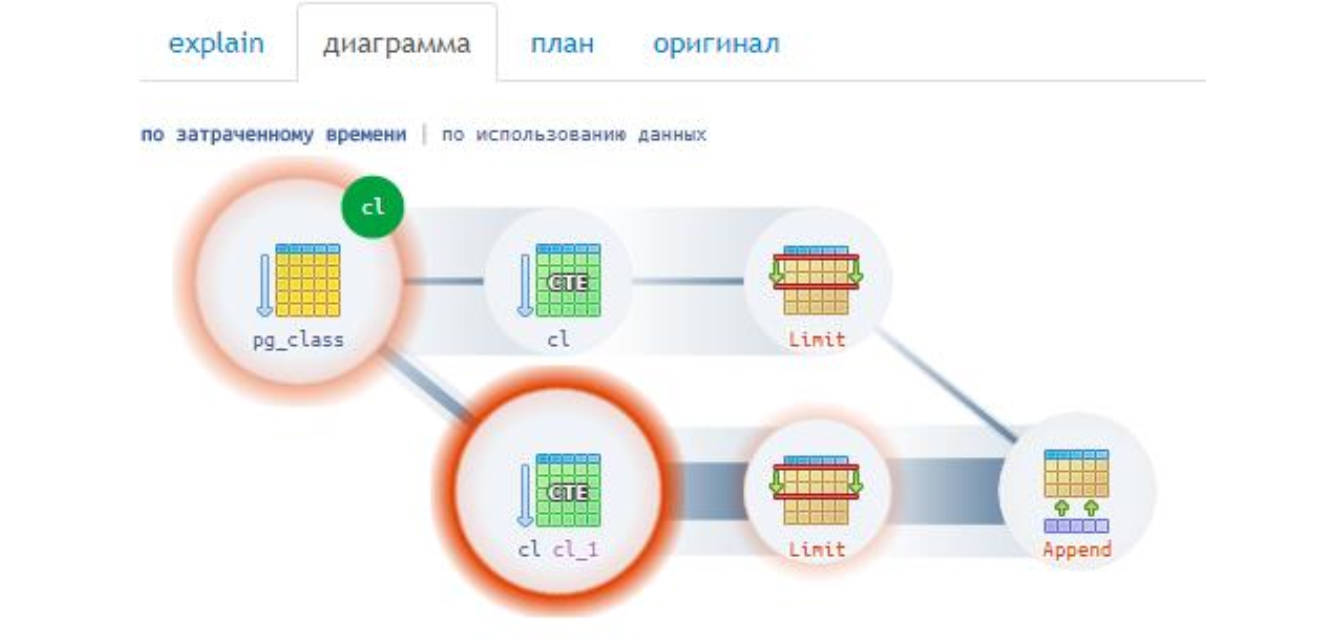
В реальности запросы и схемы посложнее. Главное, что благодаря красной подсветке разработчик видит узкое место без изучения плана полностью:
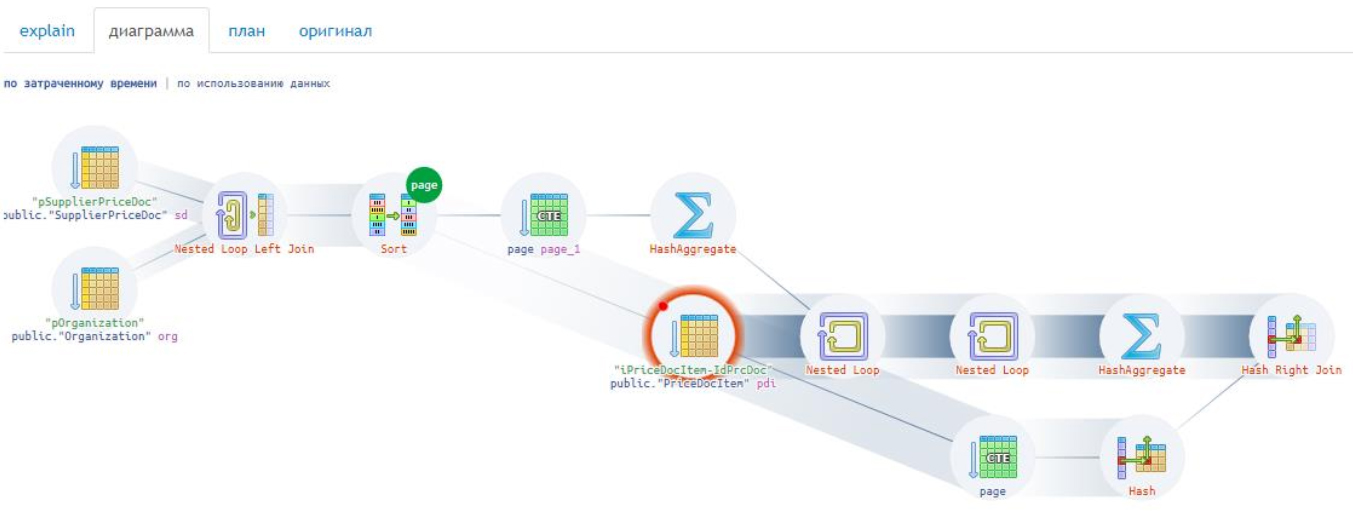
Чаще вы встречаетесь с подобными случаями:
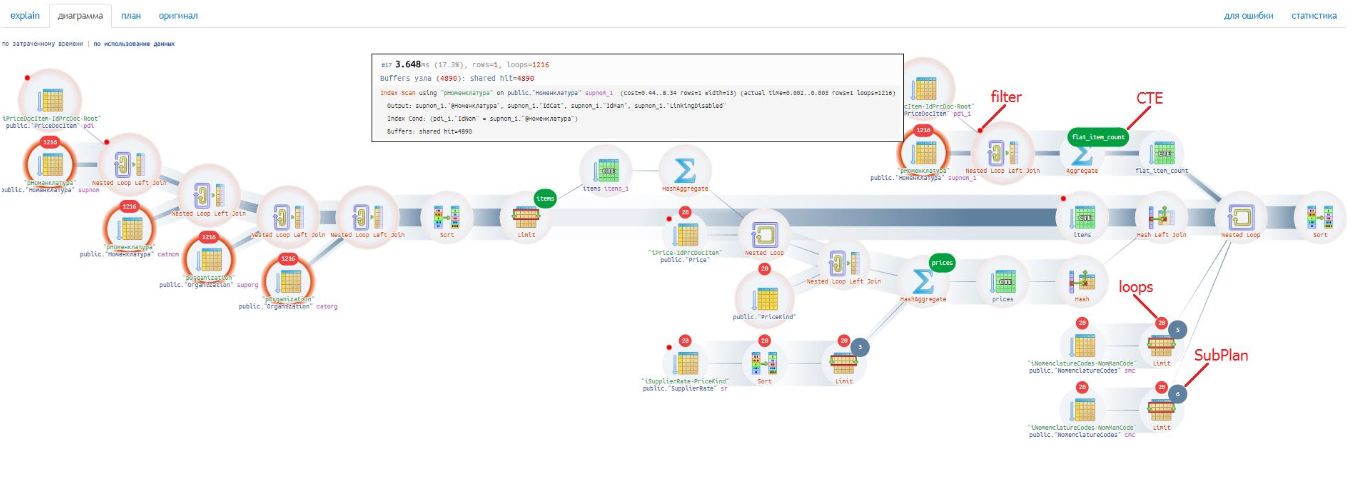
На схеме видно то, что облегчает разработчику анализировать план запроса:
В конце концов, проблем с планами запросов становится меньше, но если у вас сотни серверов, появляется ещё одна проблема – тонны логов.
Создание UDF
Иногда плохо сконфигурированный сервер будет слишком часто распараллеливать запросы, приводя к более плохой производительности, чем их эквивалентный последовательный план. В подобных случаях, перемещение логики проблемного запроса в скалярнозначную или многооператорную функцию может улучшить производительность, поскольку заставит эту часть плана выполняться последовательно. Это определенно не лучшая практика, но один из способов прийти к последовательным планам, когда вы не можете изменить пороговое значение стоимости для параллелизма.
Получение плана запроса
План запроса – последовательность шагов в виде дерева для получения результата SQL-запроса. Каждый шаг – операция: извлечение или обработка данных, сканирование индекса, пересечение или объединение множеств, построение битовых карт или другая.
Для получения плана запроса используют команду EXPLAIN. Добавьте параметры ANALYZE и BUFFERS, и, помимо действительной отработки запроса, получите время выполнения, статистическую информацию, количество попаданий, блоков и прочих данных буфера. Эта команда подходит только для локальной отладки вручную, потому что при большой нагрузке системы данные быстро меняются, и план теряет актуальность во время выполнения.
Для крупных приложений применяют модуль auto_explain. Главная прелесть auto_explain в том, что вы задаёте «медленное» время выполнения запроса. Он анализирует и записывает план в лог сервера только тогда, когда оператор отрабатывает дольше указанного числа.
Смотрите, как выглядит получение плана:
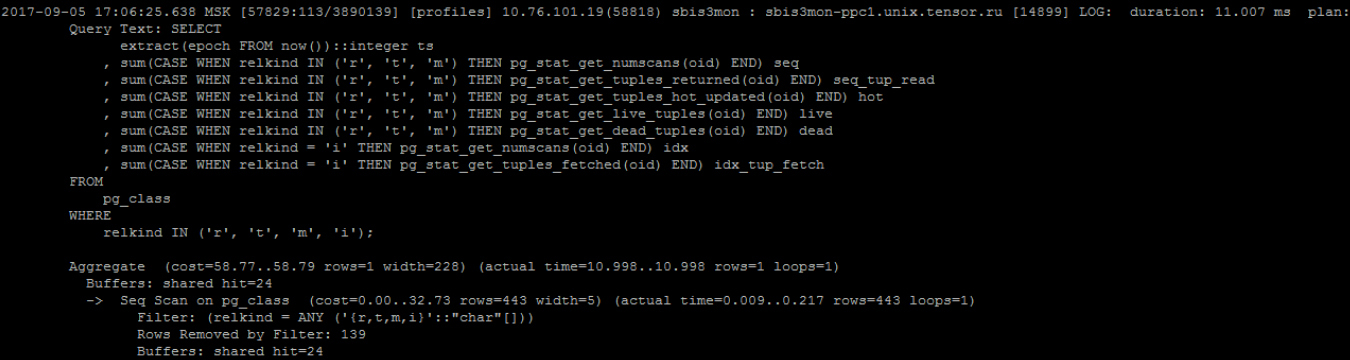
После заголовка вы видите тело запроса, а со слова Aggregate начинается, собственно, план.
Понимаем, что время выполнения хорошее, а в остальном такое представление недостаточно информативное. Поскольку каждый элемент плана отображает сумму по ресурсам поддерева, для получения количества страниц конкретного узла приходится выполнять вычисления в уме. Чтобы проанализировать время, вы умножаете оценку времени каждого узла на количество циклов выполнения. Вдобавок нелегко будет определить узкое место в плане.
Переключение оценщиков кардинального числа
Недавно появившийся в SQL Server 2014 оценщик кардинального числа улучшает производительность многих запросов. Однако в некоторых конкретных случаях это может сделать запросы более медленными. В таких случаях простой хинт запроса — это все, что вам нужно, чтобы заставить SQL server вернуться к прежнему оценщику кардинального числа.
Форсирование порядка соединения таблиц
Иногда устаревшая статистика и недостаток другой информации может привести к тому, что оптимизатор запросов SQL Server соединяет таблицы в далеко не идеальной последовательности.
Сжатие данных
Сжатие данных не только экономит место, но при определенной рабочей нагрузке может фактически улучшить производительность. Поскольку сжатые данные могут быть записаны на меньшем числе страниц, увеличивается скорость чтения с диска, но, что может быть более важно, сжатые данные позволяют сохранить их больший объем в буферном пуле SQL Server, увеличивая вероятность нахождения в памяти повторно используемых данных.
Временные промежуточные таблицы
Иногда оптимизатор запросов мучается в попытках построить эффективный план выполнения сложных запросов. Разбиение сложного запроса на множество шагов, использующих временные промежуточные таблицы, может предоставить SQL Server больше информации о ваших данных. Это также вынуждают вас писать более простые запросы, которые позволяют оптимизатору строить более эффективные планы выполнения, а также повторно использовать результирующие наборы.
Индексные представления
Когда вы не можете добавить новые индексы в существующие таблицы, возможно, вы сможете обойти это ограничений созданием представления на этих таблицах и их индексированием. Это отлично работает на базах данных от поставщиков, когда вы не можете трогать существующие объекты.
Заключение
Для решения проблем с производительностью запросов в PostgreSQL нужен детальный анализ плана запроса. С учётом разбора времени выполнения каждого узла, потребления ресурсов и отслеживания поведенческих паттернов вы понимаете, какая операция валит показатели и что требуется исправить.
Когда речь идёт о сотнях серверов, важно консолидировать логи. Теперь вы знаете, насколько нетривиальная эта задача и какие принципы применять.
