

Индексный файл (файл-индекс или просто стартовая страница) — это файл, который открывается по умолчанию при обращении не к конкретному файлу, а к каталогу. Примером такого обращения является переход по адресу «http://my-site.handyhost.ru/atricls» (здесь atricls — каталог) и веб-сервер отобразит один из существующих в данном каталоге индексных файлов из списка заданных по умолчанию: index.html, index.htm, index.php, index.php3, index.phtml, index.shtml, default.htm или default.html. То есть при переходе по адресу “http://my-site.handyhost.ru/” отобразится страница «http://my-site.handyhost.ru/index.html» (или index.php и т.д.). Если веб-сервер не найдет индексный файл, то выдаст список файлов в каталоге или ошибку с кодом 403.
Если Вы хотите сделать стартовой страницей (индексным файлом), скажем, my-page.php, то необходимо поместить в соответствующий файл .htaccess следующую директиву:
Тогда при переходе по адресу «http://my-site.handyhost.ru» отобразиться страница «http://my-site.handyhost.ru/my-page.php».
В данной директиве можно указывать несколько индексных файлов:
DirectoryIndex my-page.shtml my-page.php my-page.php3 my-page.html
Индексная страница — это файл, который соответствует каталогу, запрашиваемому пользователем. Допустим пользователь через браузер запрашивает страницу http://www.сайт.ru/, сервер обрабатывает запрос и выдает страницу в таком виде http://www.сайт.ru/index.html, так как по данному адресу настроена индексная страница index.html.
Если в запрашиваемом каталоге нет соответствующего файла, сервер выдаст ошибку 403.
В некоторых CMS обычно используются следующие индексные файлы:
На нашем хостинге используются стандартные индексные файлы (index.php, index.htm, index.html), поэтому дополнительных действий по изменению индексных страниц, при использовании нашего хостинга, не требуется.
Индексный файл нужен для того, чтобы направить пользователя на нужную страницу.
Как поменять индексные страницы?
Для того, чтобы изменить индексные файлы, требуется открыть раздел «WWW-домены», выбрать нужный домен и нажать кнопку «Изменить». Выбрать поле «Индексная страница» и изменить индексные файлы. Список имён индексных файлов указывается через пробел в порядке убывания значимости. Важно знать, сервер открывает файлы в порядке очереди от более значимых до менее значимых.
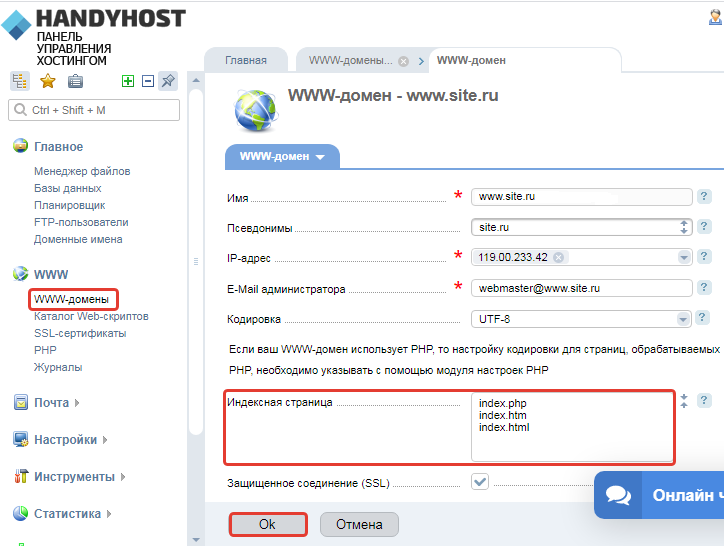
Web-сервер будет искать данные файлы, если URL указан без имени файла. Если список пуст, то значения будут использованы из глобальных настроек Web-сервера.
Также индексный файл можно изменить с помощью файла .htaccess прописав директиву, например:
DirectoryIndex index.html
или
DirectoryIndex index.html index.htm index.php
В этом случае сервер будет искать файлы в порядке заданной очереди.
Индекс в базе
данных аналогичен предметному указателю
в книге. Индекс – это вспомогательная
структура, связанная с файлом и
предназначенная для поиска информации
по тому же принципу, что и в книге
предметным указателем. Индекс позволяет
избежать проведения последовательного
или пошагового просмотра файла в поисках
необходимых данных.
Индекс
– структура данных, которая помогает
СУБД быстрее обнаружить отдельные
записи в файле и сократить время
выполнения запросов пользователей.
Структура индекса связана с определенным
ключом поиска и содержит записи, состоящие
из ключевого значения и адреса логической
записи в файле, содержащей это ключевое
значение. Файл, содержащий логические
записи, называется файлом
данных, а
файл, содержащий индексные записи, —
индексным
файлом.
Значения в индексном файле упорядочены
по полю индексирования, которое обычно
строится на базе одного атрибута.
Для ускорения
доступа к данным применяют несколько
типов индексов:
Файл может иметь
не больше одного первичного индекса
или одного индекса кластеризации, но
дополнительно к ним может иметь несколько
вторичных индексов.
Индекс может быть:
Файлы на основе
индексов можно разделить на следующие
группы: индексно-последовательные
файлы, файлы с использованием вторичного
индекса, файлы с использованием
многоуровневых индексов и файлы с
использованием индекса кластеризации.
Индексно-последовательные
файлы –
отсортированные файлы с первичным
индексом. В таком файле записи могут
обрабатываться как последовательно,
так и выборочно с произвольным доступом,
осуществляемым на основе поиска по
заданному значению ключа с использованием
индекса.
Файлы
с использованием вторичного индекса
являются упорядоченными файлами. Файл
данных, связанный с вторичным индексом,
не всегда отсортирован по ключу
индексации. Ключ вторичного индекса
может содержать повторяющиеся значения.
При запросах, в которых для поиска
используются атрибуты, отличные от
атрибутов первичного ключа, вторичные
индексы повышают производительность
обработки запросов.
Файлы
с использованием многоуровневых
индексов.
Поиск в такого рода файлах начинается
с поиска индекса самого низкого уровня,
при нахождении нужной страницы (с
атрибутом, равным условию или большим)
идет ссылка на следующий уровень индекса
с более подробной индексацией записей
и т.д.
Во многих СУБД
используется структура данных, называемая
деревом. Дерево состоит из иерархии
узлов, в котором каждый узел, за исключением
корня, имеет родительский узел, а также
один, несколько или ни одного дочернего
узла. Если узел не имеет дочернего, его
называют листом. Глубина дерева –
минимальное количество уровней между
корнем и листом. Глубина дерева может
быть различной для разных путей доступа
к листам. Если глубина одинакова для
всех листов, то дерево называют
сбалансированным или В-деревом. Степенью
или порядком дерева называют максимально
допустимое количество дочерних узлов
для каждого родительского узла. Бинарным
деревом называют дерево порядка 2.
Усовершенствованные
сбалансированные древовидные индексы
(В+-деревом) определяются по следующим
правилам:
Файлы
с использованием индекса кластеризации.
Кластерами называют
группы из одной или нескольких таблиц,
которые физически хранятся вместе,
поскольку в них совместно используются
общие столбцы и доступ к ним часто
осуществляется одновременно. Пример
кластеризованного хранения данных
приведен на рисунке 21.
Рисунок 21 — Таблицы
Сотрудники и Должность, кластеризованные
по значению Код должности
Использование
кластеров позволяет повысить
производительность выборки данных, но
степень такого повышения зависит от
распределения данных и типовых запросов.
В кластеризованных
таблицах используют индексированные
и хешированные кластеры. В индексированном
кластере хранятся вместе записи, имеющие
одинаковый ключ кластера. В хешированный
кластер запись вносится с учетом
применения хеш-функции к значению ключа
кластера этой записи.
Физическая
структура — то, как представляется
обрабатываемая информация в памяти
компьютера, как видит ее системный
программист – разработчик операционных
систем и систем управления базами
данных
Типовые операции над информационными
элементами
— выделение элементов определенного
типа среди других (необходимы: имя
(идентификатор), размер и адрес
элемента);
— сравнение значений элементов
между собой и с литералами (константами)
– необходимы те же характеристики плюс
типы внутреннего представления
(физические структуры) сравнивамых
элементов;
— над элементами записей данными могут
выполняться арифметические операции,
которые требуют тех же самых структурных
характеристик;
— переход к другому связанному
элементу структуры – необходим адрес
связанного элемента
Структура
данных — множество информационных
элементов и связей между ними.
Для работы
с физическими представлениями структур
различных уровней (записей, файлов и
баз данных) необходимы следующие
структурные характеристики:
имя
элемента структуры;
размер
элемента структуры;
адрес
связанного элемента;
тип
внутренней структуры элемента .
Анализ возможных способов физической
организации информации различных
уровней рассматривали в зависимости
от:
способа
представления
собственно
информации
об объектах предметной области хранимой
в памяти компьютера;
способа представления структурных
характеристик (явного или не явного);
способа хранения (совместного
или автономного) структурных
характеристик и собственно информации.
Элементами
структуры являются данные.
Кроме
естественного представления элементов
– данных (символьное, числовое, дата и
т.п.) в системах обработки данных часто
используется кодированное представление,
когда значения символьных данных,
значительных по размеру или определенных
на одних и тех же словарях (доменах),
заменяются компактными, чаще всего
цифровыми кодами.
Наиболее часто используют два способа
формирования кодов: порядковое и
серийно-порядковое. ( сущ-ет также
двоично-позиционное кодирование)
Под организацией значений данных
понимают относительно устойчивый
порядок расположения записей данных в
памяти ЭВМ и способ обеспечения
взаимосвязи между записями.
Организация значений данных (далее
называемая просто организацией данных)
может быть линейной и нелинейной. При
линейной организации данных каждая
запись, кроме первой и последней, связана
с одной предыдущей и одной последующей
записями. У записей, соответствующих
нелинейной организации данных, количество
предыдущих и последующих записей может
быть произвольным.
Линейные методы организации данных
различаются только способами указания
предыдущей и последующей записи по
отношению к данной записи. Но это приводит
к тому, что алгоритмы, эффективные для
одних методов организации данных,
становятся неприемлемыми для других
методов.
Среди линейных методов выделяются
последовательная и цепная организации
данных. При последовательной организации
данных записи располагаются в памяти
строго одна за другой, без промежутков,
в той последовательности, в которой они
обрабатываются. Последовательная
организация данных обычно и соответствует
понятию массив (файл).
Записи, составляющие массив, с точки
зрения способа указания их длины делятся
на записи фиксированной, переменной и
неопределенной длины. Записи фиксированной
(постоянной) длины имеют одинаковую,
заранее известную длину. Если длины
записей неодинаковы, то длина указывается
в самой записи. Такие записи называют
записями переменной длины. Вместо явного
указания длины записи можно отмечать
окончание записи специальным
символом-разделителем, который не должен
встречаться среди информационных
символов значения записи. Записи,
заканчивающиеся разделителем, называются
записями неопределенной длины.
При последовательно-смежной
организации логически связанные элементы
физически размещаются в памяти
непосредственно друг за другом, без
разрывов.
При использовании адресных указателей
логически связанные элементы физически
могу размещаться в любых участках
памяти, и каждый элемент содержит адрес
связанного с ним другого элемента. Такая
организация хранения называется
цепной или списковой.
Решение целого ряда задач обработки
данных требует применения таких методов
организации данных, которые позволили
бы связать физически разнесенные в
памяти данные в логическую последовательность,
определяющую порядок их обработки.
Простейшим методом, применяемым для
этих целей, является списковая (цепная)
организация данных.
Списком называется множество записей,
занимающих произвольные участки памяти,
последовательность обработки которых
задается с помощью адресов связи. Адресом
связи некоторой записи называется
атрибут, в котором хранится начальный
адрес или номер записи, обрабатываемой
после этой записи. Обычная последовательность
обработки записей в списке определяется
возрастанием значений ключа в записях.
В списке выделяется собственная
информация (записи с содержательными
сведениями) и ассоциативная информация,
т. е. все адреса связи.
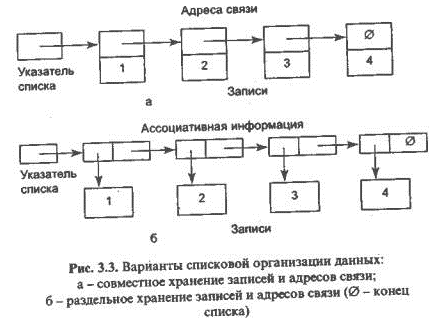
Возможны два способа хранения структурных
характеристик и собственно информации
об объектах – совместное и автономное.
В последовательных структурах элементы
логически следуют друг за другом,
располагаясь в смежных участках памяти.
В списковых — связи между элементами
данных передаются посредством адресных
указателей. Для отражения связей между
элементами данных используются
символические указатели.
Символическая связь – повторение
значения поля, по которому производится
связывание. Обычно связывающий компонент
– идентификатор данных. Связи между
элементами данных отражаются с помощью
битовых структур. В этом случае кроме
файла, содержащего сведения об объектах
создаются 1 или несколько битовых
структур (битовых векторов или матриц),
показывающих взаимоотношения элементов
основного файла. Совокупность индекса
и индексного массива является индексной
структурой. В БД обычно используют
довольно сложные многоуровневые
логические структуры данных. Сокращение
объема памяти в БД занимаются
специализированные архиваторы, являющиеся
утилитами БД. Проектирование физических
и логических структур данных тесно
связано между собой.
Последовательная организация хранения
данных (ПОХД).
ПОХД обладает следующими преимуществами:
1.отсутствие дополнительной адресной
информации и плотное размещение данных
в запоминающей среде, приводящее к
сокращению объема памяти.
2.возможность использования любых
носителей информации.
3.сокращение времени обработки при
условии, что порядок размещение на
носителе совпадает с требованием в
порядке обработки.
4.простота организации данных и
манипулирование ими, так как идет
увеличение объема памяти и уменьшение
цены, то значимость 1 и 2 фактора снижается.
Последовательные структуры данных
имеют недостатки:
2.необходимость разворачивания нелинейных
логических структур в линейные.
3.трудности в обеспечении адекватного,
интегрированного отображения предметной
области.
4.длительность выборочного поиска.
5.адаптация новых элементов данных
последовательную структуру должно
выполняться согласно логическому
порядку следующего элемента, что вызывает
необходимость физического перемещения
данных.
В последнее время в связи с широким
распространением реляционной БД,
использование последовательных данных
в файлах увеличивается. Многие реляционные
СУБД предусматривают организацию
хранения каждого отношения данных в
качестве видимого файла.
Списковая организация хранения данных.
Заключается в использование адресных
указателей для связей элементов данных.
Различают списковую организацию с
совместным и раздельным хранением, с
объектной, собственной, ассоциативной,
адресной информацией, однонаправленные
и двунаправленные списки. Такая
классификация списковых структур
традиционная. Взависимости от характера
связывания элементов, списковая структура
может связывать однотипные элементы
данных в единую структуру – однородный
список. На одном и том же множестве
элементов может быть задано несколько
связей, каждая из которых выделяет
подмножество элементов, это списки –
многосвязные. Если информация в списках
одного типа, то информация называется
гомогенной. Если информация разнородна,
то список называется гетерогенным.
списковая организация обладает
преимуществами:
1.возможность естественным путем
передавать сложные логические
взаимодействия между элементами, при
корректировках списковых структур
добавление и анулирование элементов в
списках производится без физического
перемещения элементов путем изменения
адреса элементов, при этом память может
быть повторно использована вновь
добавляемым элементом. Новые элементы
могут быть привязаны к любому месту
памяти.
2.позволяют динамически наращивать
состав БД без существенного изменения
существующих ее частей.
3.устраняют дублирование данных
(избыточность), позволяют на одном и том
же множестве элементов обеспечивать
их различную упорядоченность.
4.просто могут быть организованы в любой
прямоадресной памяти.
1. Большой расход памяти на указатели.
2. Физический разброс данных по носителю,
увеличивающий время обработки данных.
3. Потеря адреса связи в каком-либо
элементе списка, делает недоступным
всю оставшуюся часть структуры, а
искажение адреса приводит к аварийным
ситуациям.
4. Списковая структура нуждается в
сложном управлении свободной памяти.
5. Эффект дробления памяти приводит к
необходимости реорганизации массива.
Индексные
файлы (индексно-прямые, индексно-последовательные,
В-деревья)
Индексные
файлы могут представить как файлы
состоящие из 2-х частей: индексная часть
и основная часть. Различают 2 типа файлов:
—
с плотным индексом или индексно-прямые
файлы
—
с неплотным индексом (неполным) или
индексно – последовательные файлы
значение
ключа – это значение первичного ключа
Для
индексно-прямых файлов поиск начинается
в индексной области, где применяется
двоичный алгоритм поиска, потом путем
прямой адресации обращение к основной
области по конкретному номеру записи.
При
вставке и удалении узлов производится
реструктуризация дерева с тем, чтобы
сохранить его сбалансированность.
Индексные файлы
(автономное хранение характеристики
СВЯЗЬ )
3
20 1 16
Индекс по Ф. И. О.
Индекс по ПОЛ
Индекс по НАЦИОНАЛЬНОСТЬ
Таблица
соответствия
Возможно составление
индексного файла по нескольким атрибутам:
Учитывается иерархия
согласно порядку следования атрибутов,
т.е. индексирование
по Ф. И. О., пол
или Ф. И. О.,
национальность
бессмысленно
Индекс по НАЦИОНАЛЬНОСТЬ
, Ф,И,О,
Поиск
файлов является самой распространенной
операцией в системах обработки данных,
поэтому важнейшим элементом любой
системы управления базами данных
является наличие средств ускоренного
поиска данных.
Этот
механизм обычно реализуется введением
так называемых индексных файлов
(индексов). Они имеют расширение имени
NDX.
Если
файл проиндексирован, команды DISPLAY,
BROWSE, SKIP, REPLACE и все другие команды,
связанные с движением в файле базы
данных, перемещают указатель записей
в соответствии с индексом, а не с
физическим порядком расположения
записей.
Один
файл базы данных может быть проиндексирован
по нескольким полям и иметь любое число
индексных файлов, которое ограничено
только дисковой памятью компьютера.
Такие файлы содержат информацию о
расположении записей файла базы данных
в алфавитном, хронологическом или
числовом порядке для того поля, по
которому выполнено индексирование.
Допускается индексирование и по
логическим полям.
Для
создания индексного файла, использующего
в качестве ключа содержимое поля NAME,
вводится команда
INDEX
ON NAME TO NAMIDX
Эта
команда создает файл по имени NAMIDX. NDX,
добавляя автоматически расширение NDX
к имени, указанному в команде. Файл
NAMIDX содержит указатели
на записи файла EMPLOY, причем
эти указатели следуют друг за другом в
алфавитном порядке фамилий, расположенных
в полях NAME.
При
работе с индексными файлами используются
команды FIND и SEEK.
Их функции взаимно перекрываются.
Первая
команда FIND обычно
применяется при работе со строками
символов, команда SEEK –
при работе с числовыми литералами,
датами и временными переменными.
Для
нахождения в файле первой записи,
содержимое поля NAME которой
начинается буквой R,
используется команда
С
помощью команды LIST NAME
воспроизводятся записи в алфавитном
порядке.
Если
теперь создать дополнительный индексный
файл DPTIDX командой
INDEX
ON DEPT TO DPTIDX
то после ввода команды
LIST NAME, DEPT
Записи будут воспроизводиться в порядке
возрастания значения содержимого поля
DEPT, а не поля NAME,
так как при создании индексного файла
DPTIDX файл NAMIDX
был закрыт.
Чтобы
быть уверенным, что для извлечения
требуемой информации используется
соответствующий индексный файл, файл
данных следует открывать совместно с
требуемым индексным файлом, например,
USE
EMPLOY INDEX NAMIDX
Для
определения того, какой индексный файл
открыт в настоящий момент, используется
команда
Индексирование
файла данных можно также выполнять,
используя в качестве ключа числовое
поле записи.
INDEX
ON ANN_SAL TO SALIDX
SET HEADING ON
LIST NAME, ANN_SAL
Записи
воспроизводятся на экране в порядке
возрастания значения числового поля
ANN_SAL. Если требуется
воспроизвести первую запись, содержимое
числового поля ANN_SAL которой
равно 15000000, то это выполняется так:
dBASE
позволяет одновременно держать
открытыми до семи индексных файлов.
По
команде CLOSE INDEX все открытые
индексные файлы закрываются. Файл данных
EMPLOY все еще остается
открытым, и записи можно извлекать в
порядке их следования в файле данных.
По
команде CLOSE DATABASES закрываются
все открытые файлы данных и все открытые
индексные файлы.
Сортировка
Для
реорганизации текущего файла данных,
используя содержимое одного или
нескольких полей в качестве критерия
упорядочения записей, применяется
команда SORT.
Реорганизованные
записи помещаются в специально создаваемый
для этой цели файл данных.
Преимуществом
сортировки является возможность создания
файла с расположением записей в порядке
убывания “значений” содержимого
символьных полей, чего нельзя достигнуть
индексированием.
Для
сортировки файла EMPLOY в
порядке убывания значений содержимого
поля HIRE_DATE (запись о
служащем, принятым на работу первым,
будет в начале списка) нужно выполнить
команды:
SORT TO HEMPLOY ON
HIRE_DATE /D
Здесь
HEMPLOY – имя файла, создаваемого
командой SORT. По умолчанию,
к нему добавляется расширение DBF.
Необязательный для употребления, но
используемый в команде SORT,
параметр /D указывает на
необходимость сортировки в порядке
убывания содержимого поля HIRE_DATE.
Если требуется сортировка в порядке
возрастания указанных значений, то этот
параметр указывать не нужно.
воспроизведут записи в порядке очередности
приема служащих на работу.
Для
получения подробной информации о
служащих с упорядочением в пределах
каждого отдела нужно выполнить команды:
SORT TO HEMPLOY ON
DEPT, HIRE_DATE
LIST DEPT, NAME,
HIRE_DATE
Соседние файлы в папке Лекции по информационным технологиям
