
 с помощью Smart Storage Administrator")
Virtual Drive Erase
The Logical View – Virtual Drive Erase menu appears.
Figure 38. Mode Selection – Virtual Drive Erase Dialog
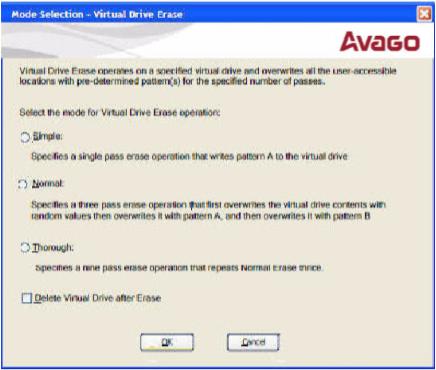
After you select this option and click , and if Delete Virtual Drive after Erase is selected, the figure appears; otherwise, the figure appears.
When you select this option, the virtual drive is erased and the figure appears; otherwise, the figure appears.
Click and if Delete Virtual Drive after Erase is checked, the figure appears; otherwise, the figure appears.
When you select this option, the dialog closes, and the MegaRAID Storage Manager navigates back to view.
Figure 39. Warning Message for Virtual Drive Erase
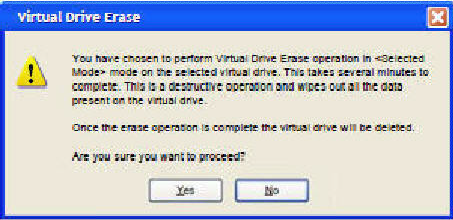
Figure 40. Warning Message for Virtual Drive Erase without Virtual Drive Delete


Понадобилось добавить новый RAID в ESXi 6.5. Гипервизор был установлен на небольшом сервере HPE ProLiant ML30. Новые диски hot plug, подсоединились без проблем, осталось настроить RAID.
ESXi 6.5 была установлена из образа HPE Customized image. Здесь есть специальная утилита ssacli для управления RAID контроллером.
Проверяем статус контроллера:
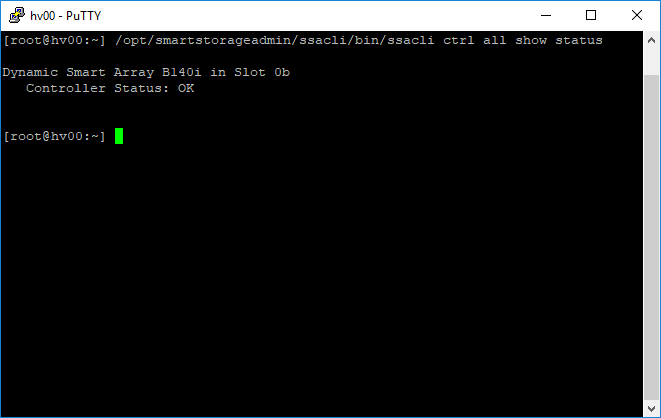
На сервере используется контроллер Dynamic Smart Array B140i. Слот 0b — этот номер слота запомним и используем дальше в командах. Статус OK, можно продолжать работу.
Проверяем конфигурация контроллера:
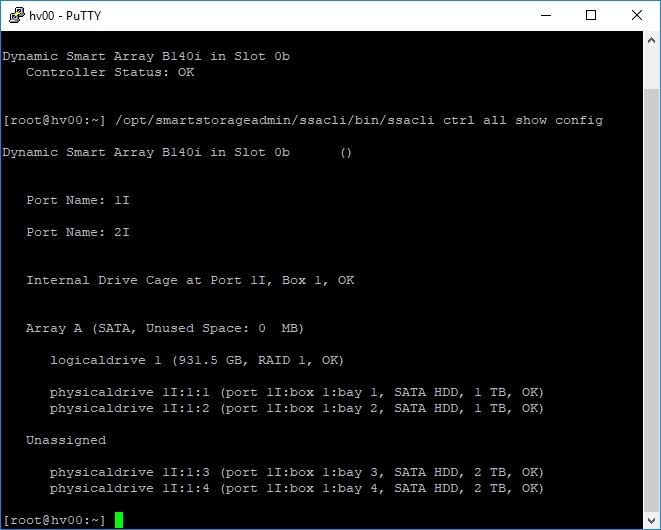
Видим, что свободно два диска «Unassigned» в 3 и 4 слоте, вот из них нам и нужно создать ещё один RAID 1 массив.
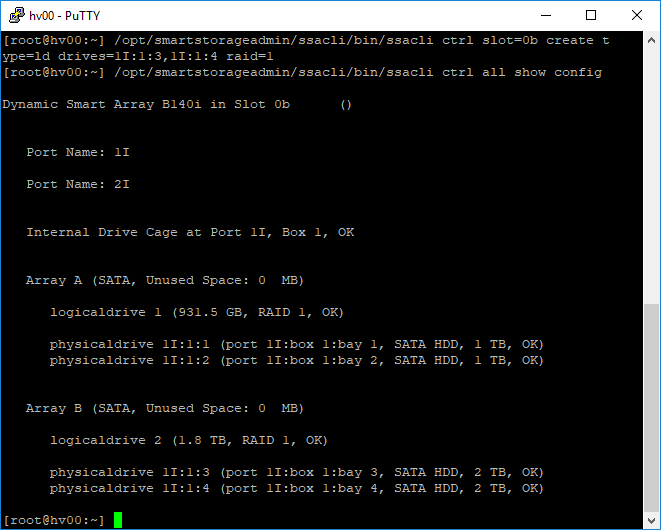
Теперь у нас есть Array B.
Проверяем статус массивов:
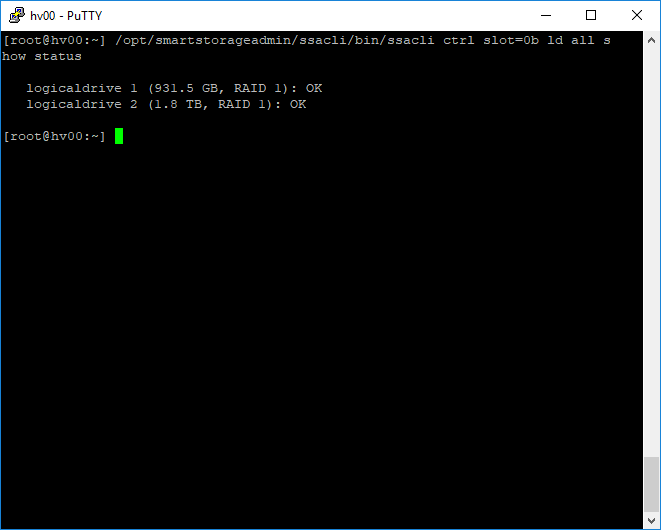
Для того, чтобы ESXi смог использовать новый RAID в качестве хранилища, потребуется перезагрузка хоста.
- Список полезных команд
- Вход в Smart Storage Administrator
- RAID1 из HDD
- RAID1 из SSD
- Проблема с RAID Adaptec 5805 (Secure Erase)
- 9 Replies
- Read these next.
- Совершенствуя системы хранения данных
- Увеличиваем быстродействие
- Увеличиваем отказоустойчивость
- История и развитие RAID
- Архитектура основных уровней RAID
- RAID 0. Дисковый массив без отказоустойчивости (Striped Disk Array without Fault Tolerance)
- RAID 1. Дисковый массив с дублированием или зеркалка (mirroring)
- RAID 2. Отказоустойчивый дисковый массив с использованием кода Хемминга (Hamming Code ECC).
- RAID 3. Отказоустойчивый массив с параллельной передачей данных и четностью (Parallel Transfer Disks with Parity)
- RAID 4. Отказоустойчивый массив независимых дисков с разделяемым диском четности (Independent Data disks with shared Parity disk)
- RAID 5. Отказоустойчивый массив независимых дисков с распределенной четностью (Independent Data disks with distributed parity blocks)
- RAID 6. Отказоустойчивый массив независимых дисков с двумя независимыми распределенными схемами четности (Independent Data disks with two independent distributed parity schemes)
- RAID 10. Отказоустойчивый массив с дублированием и параллельной обработкой
- RAID 30. Отказоустойчивый массив с параллельной передачей данных и повышенной производительностью.
- RAID 50. Отказоустойчивый массив с распределенной четностью и повышенной производительностью
- RAID 7. Отказоустойчивый массив, оптимизированный для повышения производительности. (Optimized Asynchrony for High I/O Rates as well as High Data Transfer Rates). RAID 7® является зарегистрированной торговой маркой Storage Computer Corporation (SCC)
- Некоторые аспекты реализации RAID систем
Список полезных команд
Недавно я разобрал на сервере HP Proliant DL360 Gen9 массив RAID10 из четырёх HDD дисков, два HDD вытащил. Вместо них вставил два новеньких SSD. Теперь мы можем собрать два зеркала RAID1. Один RAID1 массив из 15K HDD будет под систему, второй RAID1 массив из SSD — для 1С.
HPE Proliant DL360 Gen9 — замена дисков
Вход в Smart Storage Administrator
Для управления массивами в Gen9 серверах используем SSA.
Попадаем в BIOS. Заходим в System Configuration.
Потом в RAID контроллер.
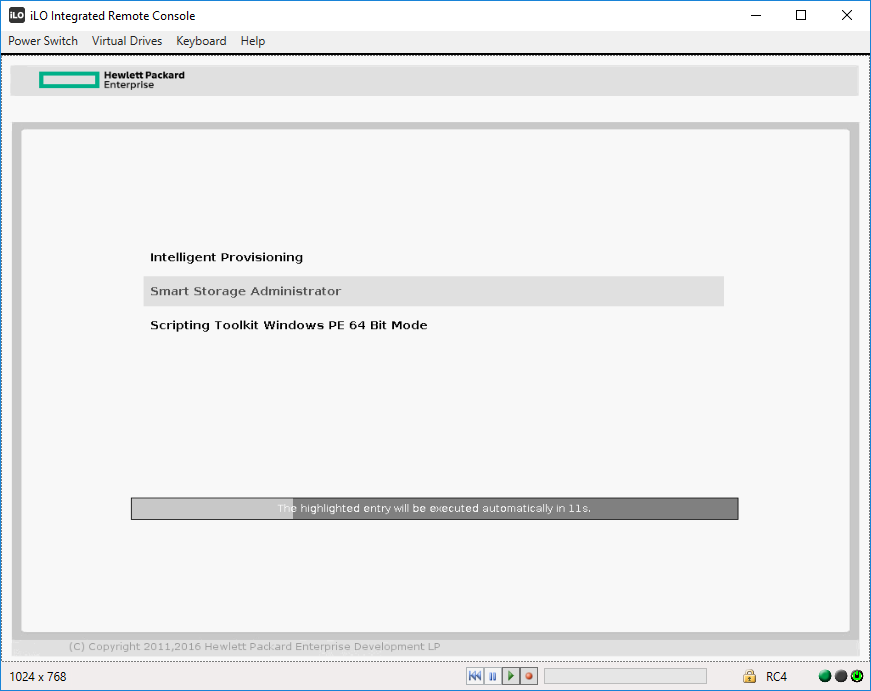
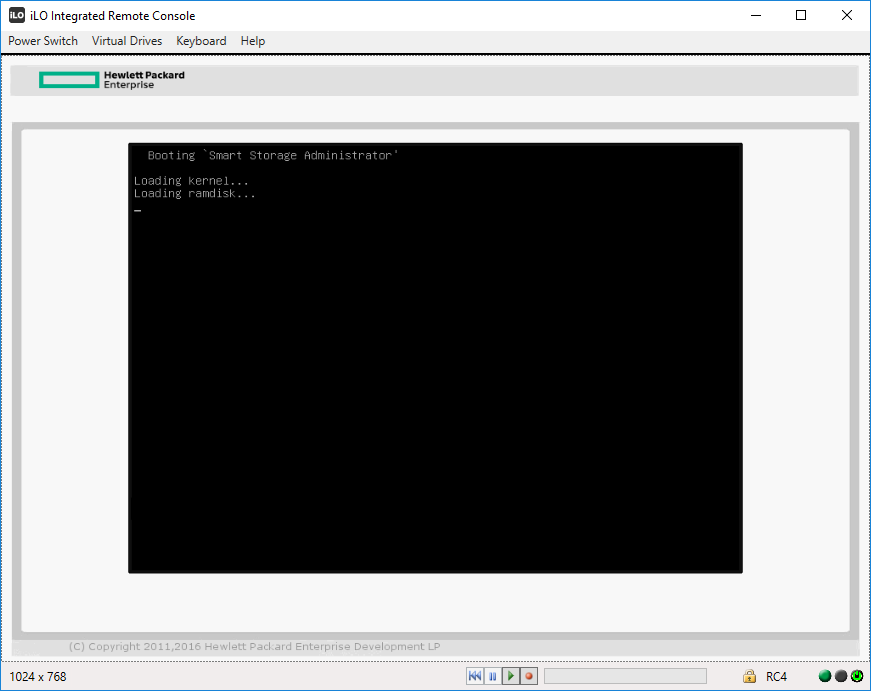
RAID1 из HDD
Собираем первый массив.
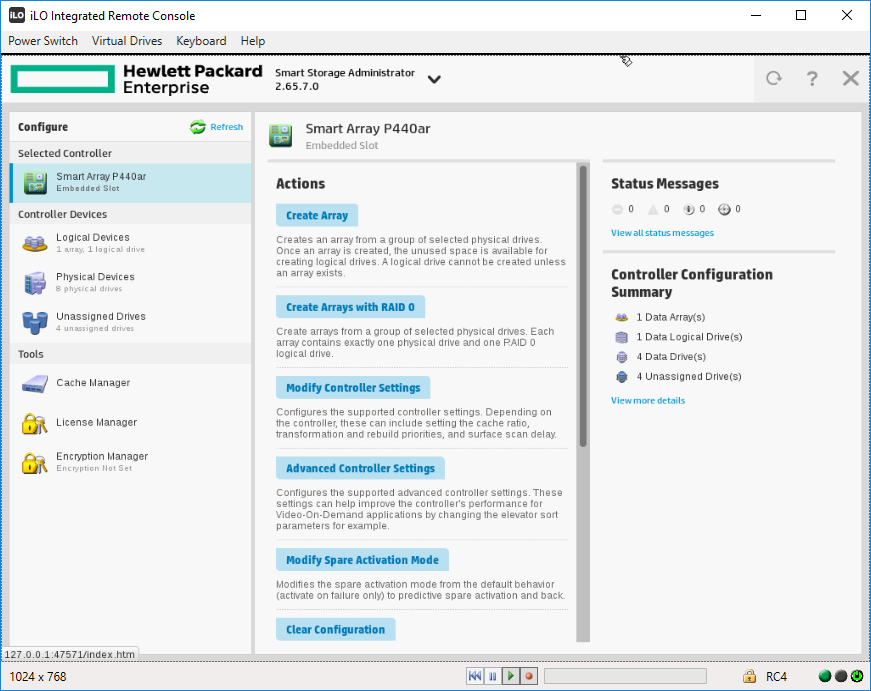
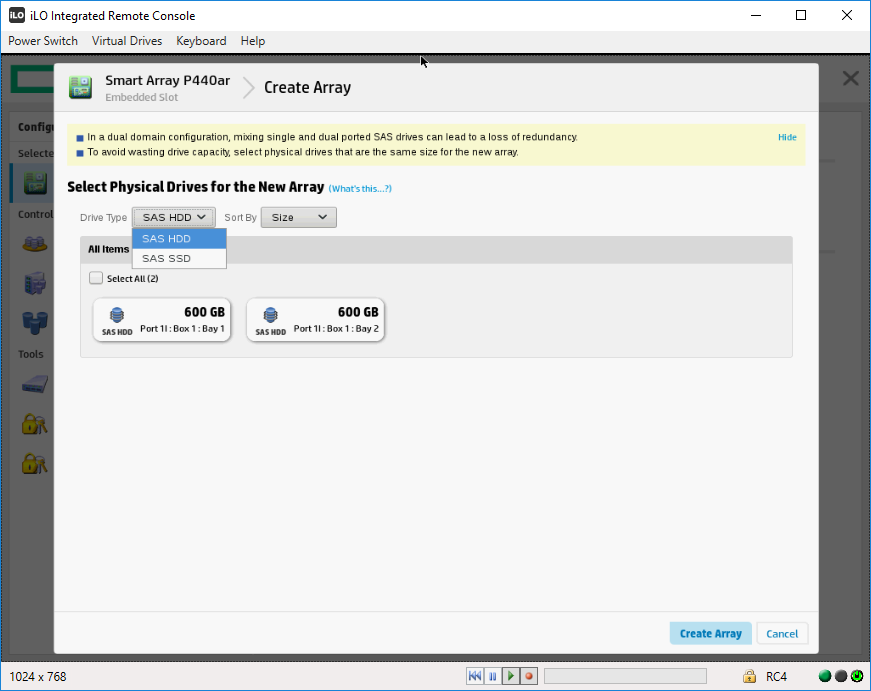
Открывается мастер создания массива. Мы можем создать массив из SAS HDD или из SAS SSD. Выбираем SAS HDD.
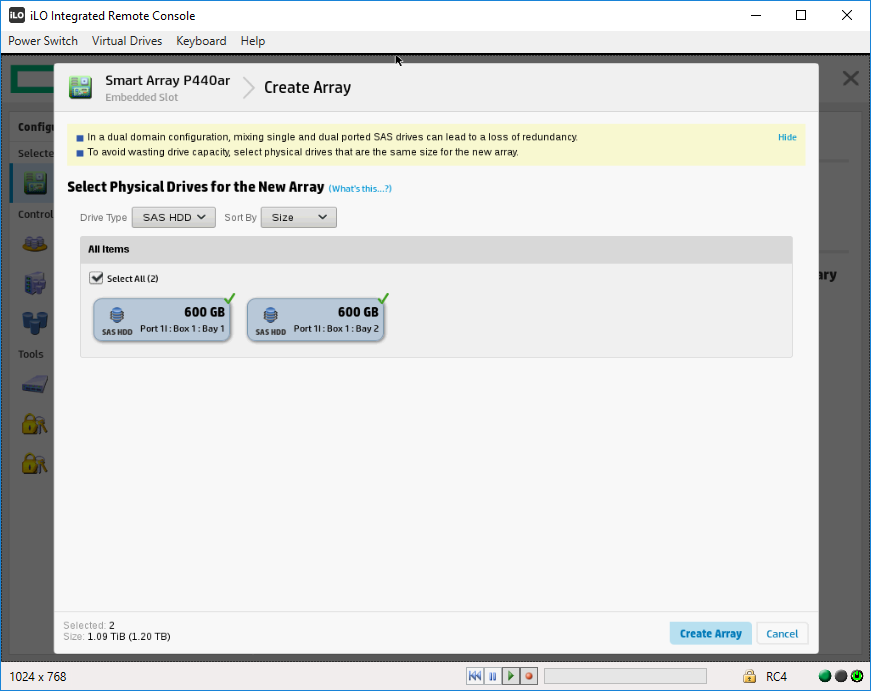
Выделяем галками оба HDD диска. Create Array.
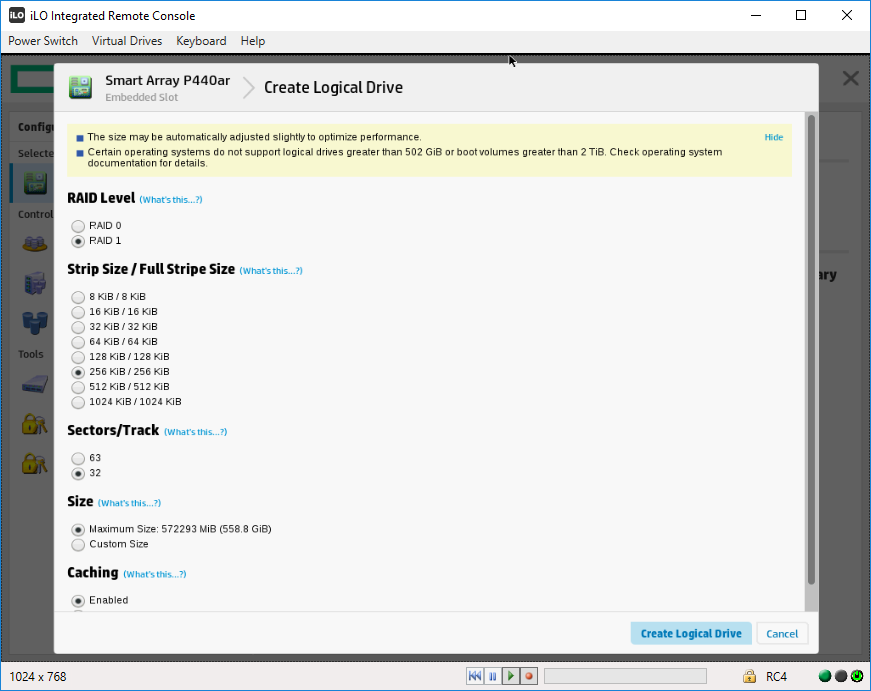
Выбираем RAID Level — RAID 1. Остальное оставляю по умолчанию. Create Logical Drive.
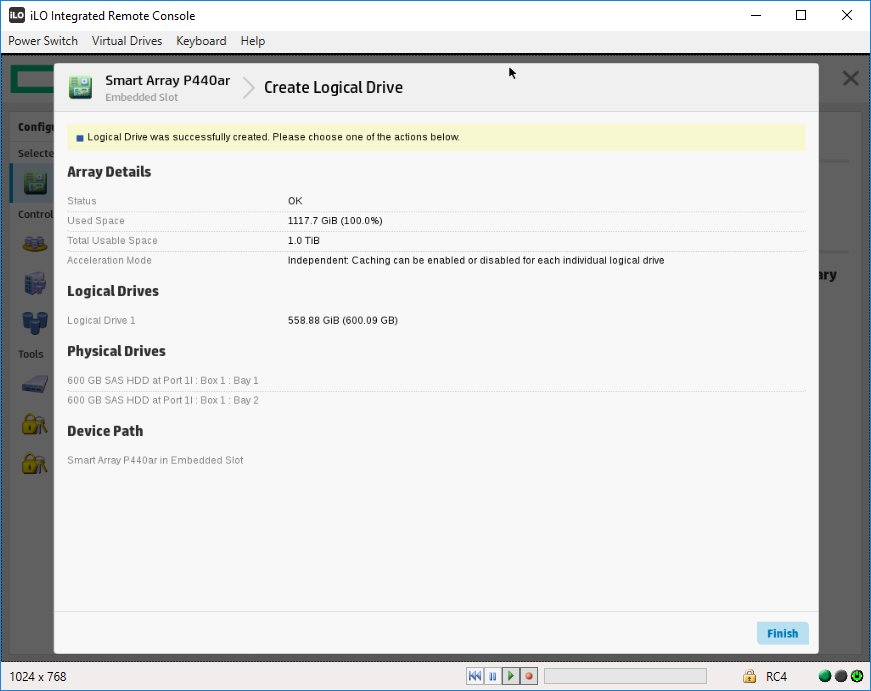
Finish. Массив создан. Мы видим его как Array A.
RAID1 из SSD
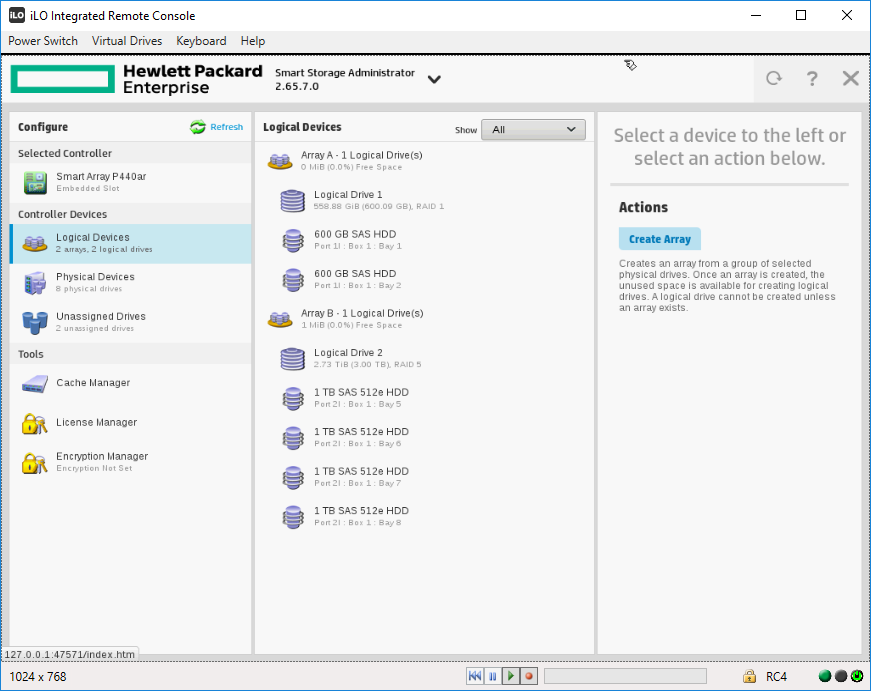
Создадим второй массив. Create Array. Снова открывается мастер создания массива. Теперь выбрать группу не из чего.
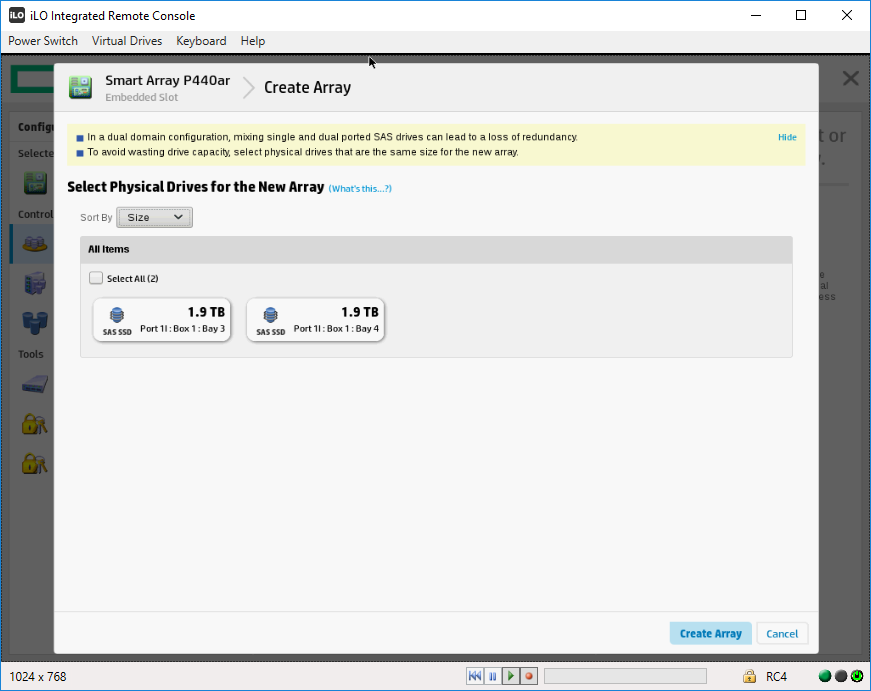
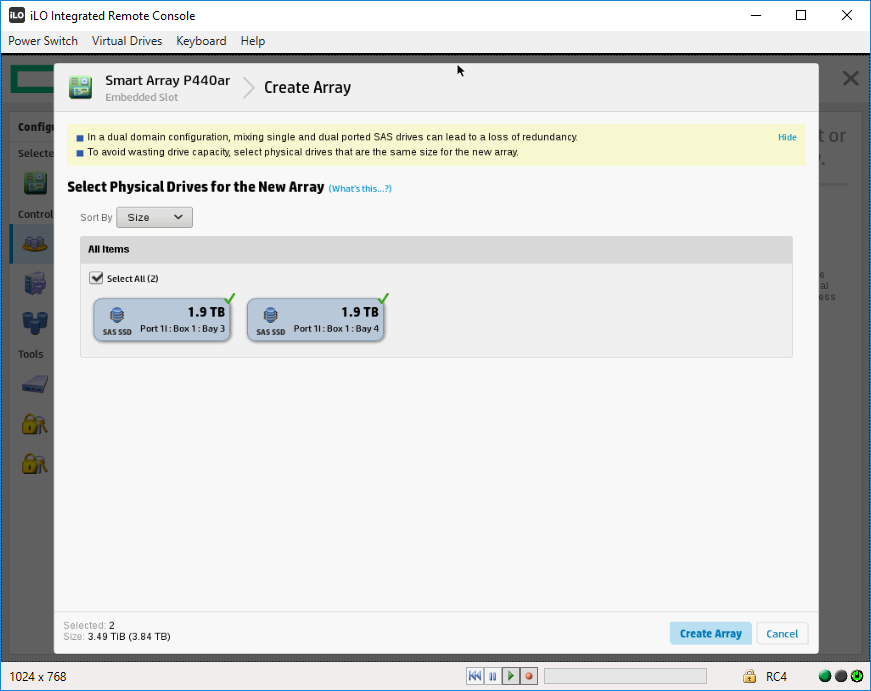
Видим два SSD диска, выделяем их.
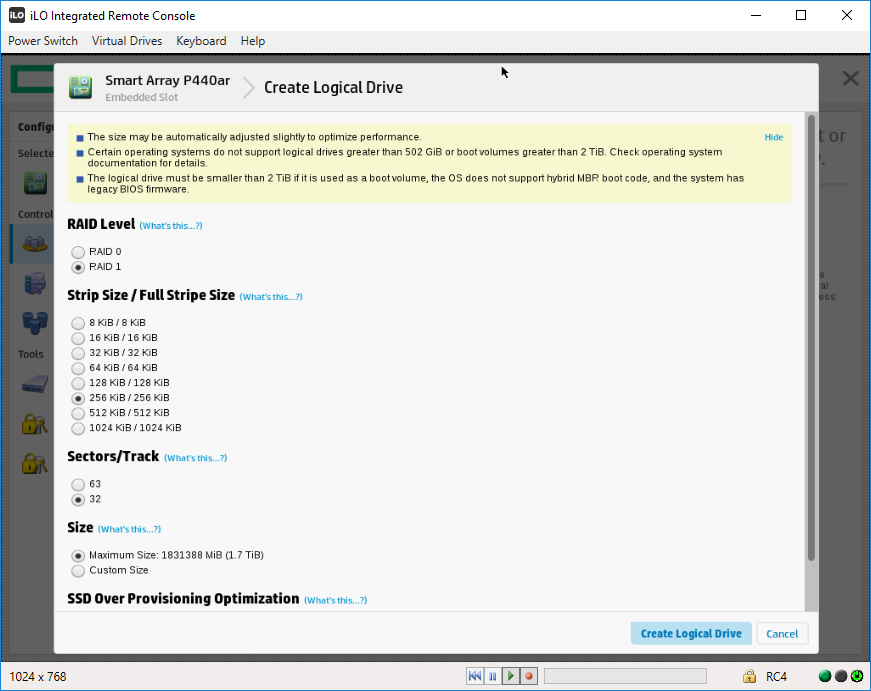
Выбираем RAID Level — RAID 1. Остальное оставляю по умолчанию. Замечаю новый пункт — SSD Over Provisioning Optimization.
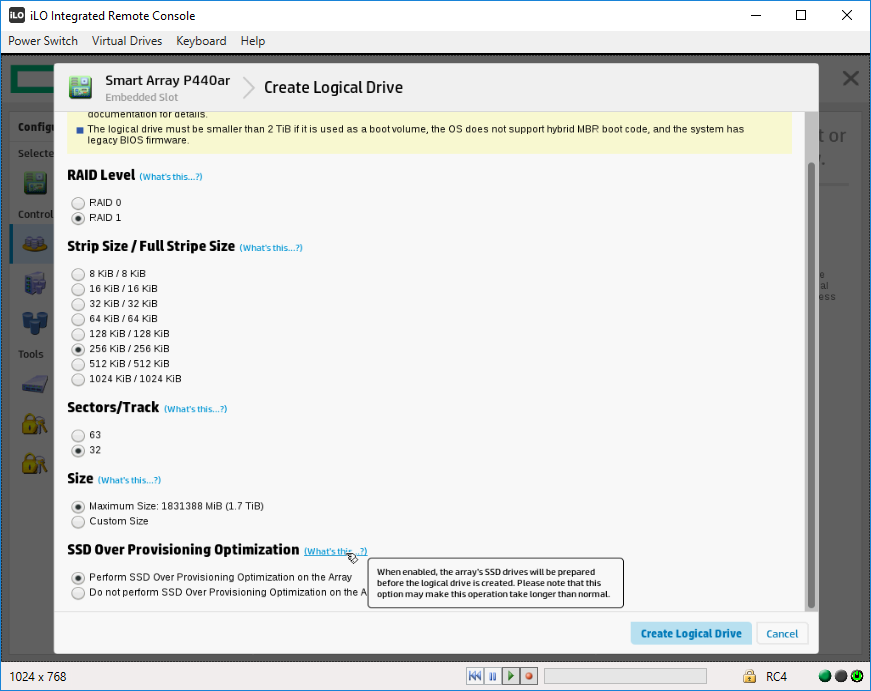
SSD Over Provisioning — это опция, которая резервируют некоторый объём диска под нужды контроллера. Как правило, резервная область составляет около 7% общей ёмкости. В серверах такой процент может доходить до 28%.
Любой SSD диск состоит из микросхем NAND памяти. NAND Flash разделена на блоки размером 512 Кб или 256 Кб. Блоки разделены на страницы по 4 Кб. Писать страницы можно только в пустые блоки. Перезапись страницы осуществляется так: сначала считываются все страницы блока, блок стирается, потом блок записывается со старыми и новыми страницами. Это долго, если есть чистый блок, то старый блок считывается, пишется в чистый с новой страницей. А потом уже лишнее стирается в фоновом режиме. Чем больше таких чистых блоков, тем быстрее запись. К тому же из Over Provisioning области выделяются блоки на смену вышедшим из строя. К сожалению, цикл перезаписи в NAND памяти ограничен. Ресурс разнится от 100000 до 1000-3000 циклов в зависимости от технологии производства.
Всегда имейте в виду, что при покупке SSD нужно накидывать 10% сверху.
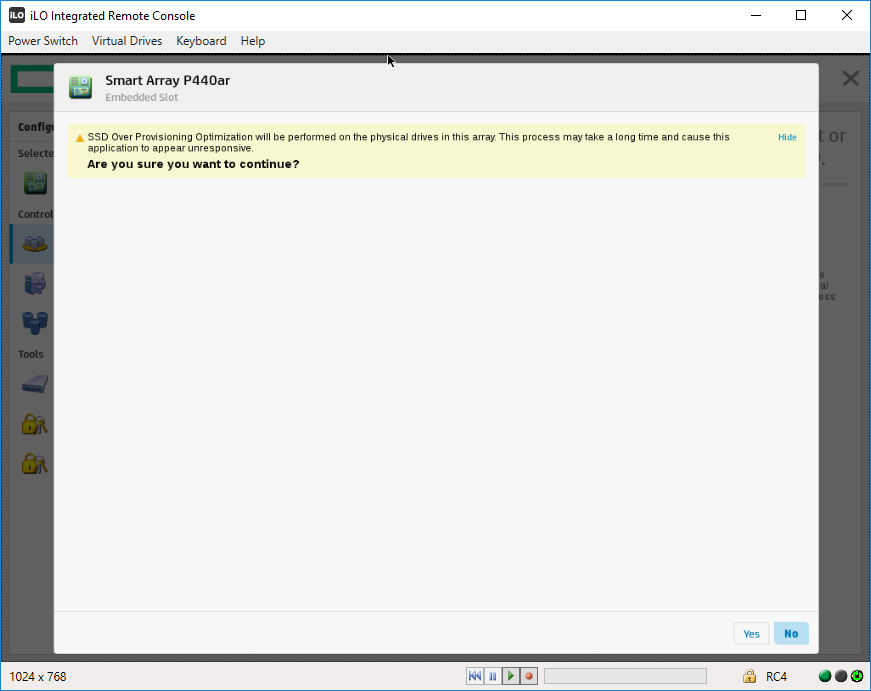
Нас предупреждают, что оптимизация может занять много времени. Yes.
В Интернете находил жалобы на 20 часов простоя. Странно, но у меня этот процесс не занял много времени. Возможно, диски уже были оптимизированы.
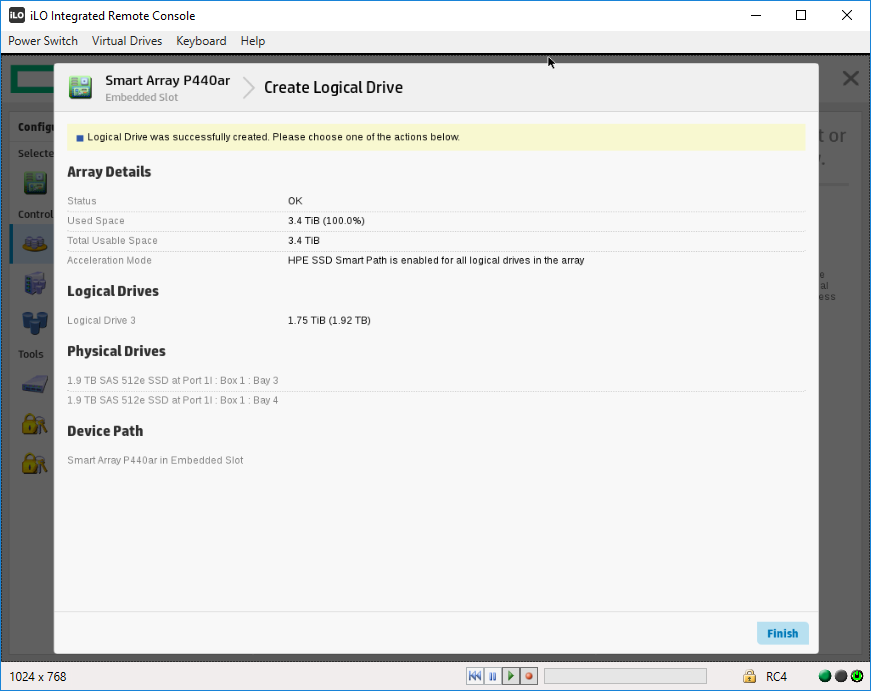
Finish. Массив создан. Мы видим его как Array C.
Junior memberСообщения: 11Зарегистрирован: 26 май 2012, 00:28Откуда: Саратов
Проблема с RAID Adaptec 5805 (Secure Erase)
Доброго времени суток! Очень нужна помощь специалистов.
Имеется контроллер Adaptec RAID 3805 и 7 дисков по 1 Тб (Seagate и несколько WD), прошивки везде самые новые.
Столкнулся со следующей проблемой:
При подключении дисков к контроллеру, он отказался их инициализировать (видимо из-за того, что диски ранее работали на другом контроллере в RAID5). По рекомендациям из просторов интернета был запущен процесс Secure Erase. Не дождавшись окончания процесса, попытался остановить его. На первом диске остановить получилось (по нажатию Ctrl+Q), после чего этот диск удалось инициализировать. На остальных дисках остановить процесс не получается. Действие Ctrl+Q контроллер будто бы выполняет (на выбранном диске), но фактической остановки процесса не происходит. Сам же процесс дошел до 69% (на некоторых дисках 57%) и будто бы завис, висит уже более 9 часов
Что можно предпринять?
Advanced memberСообщения: 186Зарегистрирован: 28 янв 2014, 08:31Откуда: Иркутск
30 янв 2014, 13:04
если сервер не в строю еще, то выключить, отключить питание, отключить батарейку кэша при наличии. потом обратный процесс и посмотреть список текущих задач на контроллере.
30 янв 2014, 13:08
Где-то читал, что такая особенность у прошивки, что мол чтобы отменить процесс — нужно каждый диск по очереди подключить к порту 0 и отменить там. Могу попробовать сделать так. Но при этом Adaptec не рекомендует во время процесса отключать питание, это как-то может повредить дискам?
Сообщения: 16650Зарегистрирован: 23 авг 2002, 17:34Откуда: Москва
Контактная информация:
31 янв 2014, 14:03
Физически отключение ничем не повредит.
Я бы попробовал кабели тупо отстегнуть.
31 янв 2014, 14:17
После долгих ожиданий, процесс так и не сдвинулся с места. В итоге пришлось, действительно, отключить все диски. После этого каждый диск по очереди подключил к порту 0 и таким образом отменил процесс (выходит, действительно у контроллера есть такая неприятная особенность, как я писал выше).
И еще непонятная штука произошла. При попытке создать логический диск на 5 Тб через утилиту Adaptec Storage Manager, вышла ошибка, что мол один логический диск не может превышать 2 Тб. Погуглил на эту тему, на сайте Adaptec сказано, что такая особенность есть только при работе с дисками SATA. Но у меня диски SATA-II, следовательно проблемы быть не должно. В итоге зашел в BIOS контроллера и попробовал создать диск там. И ко всему удивлению — диск создался без каких-либо проблем, и даже корректно отображается в этом сторедж менеджере.
Вот мне интересно, что это за чудеса такие, и у всех ли были такие проблемы?
31 янв 2014, 20:06
2Tb очень похоже не ограничение разделов MBR. В какой операционной системе стоит ASM?
31 янв 2014, 20:07
Windows Server 2008 R2 x64. В этой же системе работают 3Тб диски в GPT, никаких проблем с ними не было.
Вернуться в «Массивы — Технические вопросы, решение проблем.»
I hope that this guide will prove useful to the many people who have been tasked with erasing the drives connected to their RAID hardware. If nothing else, I hope it will give the one piece of information to help you figure out your similar situation.
I was tasked with erasing the drives on our Dell PowerEdge 2950 servers that have built-in PERC RAID controllers. DBAN’s RAID disclaimer states that DBAN is unsupported and often incompatible with RAID hardware. This guide details how I got it to work with our hardware.

Access the PERC configuration Utility, select the Controller, and chose the option to break the array.

Several articles advised setting each drive to JBOD. Unfortunately, from what I read, this capability must be enabled by the hardware. I couldn’t find a way to do this with the PERC controller so after looking around, I found a post in Dell’s forums stating that setting each disk as RAID0 would suffice.
Insert the DBAN CD in the server’s optical drive tray.

I wanted to see if my choices were successful so I chose to press Enter to utilize Interactive mode. When I’m erasing hard drives on desktop computers or laptops, I normally choose to type autonuke.

I pressed the space bar to select all the drives that were present (I had only 5 drives in the device when this picture was taken and I selected all 5 drives)

I would look at the progress periodically and it showed 3 hours remaining, and then 10 hours, and eventually 13.

After the process has run, load another set of drives and repeat the process!
I knew once I was able to get DBAN to see the drives, I was onto something. Before I even got to that step (#5 in this guide), I was greeted by several errors or reports of unrecognized device.
I’m satisfied with the results and confident that I was able to accomplish my assignment.
9 Replies
View Best Answer in replies below
Read these next.
- Need computer to run AI tracking software
- Browsers on servers
- IT Adventures: Episode Six — Shoot the Moon
Совершенствуя системы хранения данных
Перенос центра тяжести с процессоро-ориентированных на дата-ориентированные приложения обуславливает повышение значимости систем хранения данных. Вместе с этим проблема низкой пропускной способности и отказоустойчивости характерная для таких систем всегда была достаточно важной и всегда требовала своего решения.
В современной компьютерной индустрии в качестве вторичной системы хранения данных повсеместно используются магнитные диски, ибо, несмотря на все свои недостатки, они обладают наилучшими характеристиками для соответствующего типа устройств при доступной цене.
Особенности технологии построения магнитных дисков привели к значительному несоответствию между увеличением производительности процессорных модулей и самих магнитных дисков. Если в 1990 г. лучшими среди серийных были 5.25″ диски со средним временем доступа 12мс и временем задержки 5 мс (при оборотах шпинделя около 5 000 об/м1), то сегодня пальма первенства принадлежит 3.5″ дискам со средним временем доступа 5 мс и временем задержки 1 мс (при оборотах шпинделя 10 000 об/м). Здесь мы видим улучшение технических характеристик на величину около 100%. В тоже время, быстродействие процессоров увеличилось более чем на 2 000%. Во многом это стало возможно благодаря тому, что процессоры имеют прямые преимущества использования VLSI (сверхбольшой интеграции). Ее использование не только дает возможность увеличивать частоту, но и число компонент, которые могут быть интегрированы в чип, что дает возможность внедрять архитектурные преимущества, которые позволяют осуществлять параллельные вычисления.
1 — Усредненные данные.
Сложившуюся ситуацию можно охарактеризовать как кризис ввода-вывода вторичной системы хранения данных.
Увеличиваем быстродействие
Невозможность значительного увеличения технологических параметров магнитных дисков влечет за собой необходимость поиска других путей, одним из которых является параллельная обработка.
Если расположить блок данных по N дискам некоторого массива и организовать это размещение так, чтобы существовала возможность одновременного считывания информации, то этот блок можно будет считать в N раз быстрее, (без учёта времени формирования блока). Поскольку все данные передаются параллельно, это архитектурное решение называется parallel-access array (массив с параллельным доступом).
Массивы с параллельным доступом обычно используются для приложений, требующих передачи данных большого размера.
Некоторые задачи, наоборот, характерны большим количеством малых запросов. К таким задачам относятся, например, задачи обработки баз данных. Располагая записи базы данных по дискам массива, можно распределить загрузку, независимо позиционируя диски. Такую архитектуру принято называть independent-access array (массив с независимым доступом).
Увеличиваем отказоустойчивость
К сожалению, при увеличении количества дисков в массиве, надежность всего массива уменьшается. При независимых отказах и экспоненциальном законе распределения наработки на отказ, MTTF всего массива (mean time to failure — среднее время безотказной работы) вычисляется по формуле MTTFarray = MMTFhdd/Nhdd (MMTFhdd — среднее время безотказной работы одного диска; NHDD — количество дисков).
Таким образом, возникает необходимость повышения отказоустойчивости дисковых массивов. Для повышения отказоустойчивости массивов используют избыточное кодирование. Существует два основных типа кодирования, которые применяются в избыточных дисковых массивах — это дублирование и четность.
Дублирование, или зеркализация — наиболее часто используются в дисковых массивах. Простые зеркальные системы используют две копии данных, каждая копия размещается на отдельных дисках. Это схема достаточно проста и не требует дополнительных аппаратных затрат, но имеет один существенный недостаток — она использует 50% дискового пространства для хранения копии информации.
Второй способ реализации избыточных дисковых массивов — использование избыточного кодирования с помощью вычисления четности. Четность вычисляется как операция XOR всех символов в слове данных. Использование четности в избыточных дисковых массивах уменьшает накладные расходы до величины, исчисляемой формулой: НРhdd=1/Nhdd (НРhdd — накладные расходы; Nhdd — количество дисков в массиве).
История и развитие RAID
Несмотря на то, что системы хранения данных, основанные на магнитных дисках, производятся уже 40 лет, массовое производство отказоустойчивых систем началось совсем недавно. Дисковые массивы с избыточностью данных, которые принято называть RAID (redundant arrays of inexpensive disks — избыточный массив недорогих дисков) были представлены исследователями (Петтерсон, Гибсон и Катц) из Калифорнийского университета в Беркли в 1987 году. Но широкое распространение RAID системы получили только тогда, когда диски, которые подходят для использования в избыточных массивах стали доступны и достаточно производительны. Со времени представления официального доклада о RAID в 1988 году, исследования в сфере избыточных дисковых массивов начали бурно развиваться, в попытке обеспечить широкий спектр решений в сфере компромисса — цена-производительность-надежность.
С аббревиатурой RAID в свое время случился казус. Дело в том, что недорогими дисками во время написания статьи назывались все диски, которые использовались в ПК, в противовес дорогим дискам для мейнфрейм (универсальная ЭВМ). Но для использования в массивах RAID пришлось использовать достаточно дорогостоящую аппаратуру по сравнению с другой комплектовкой ПК, поэтому RAID начали расшифровывать как redundant array of independent disks2 — избыточный массив независимых дисков.
2 — Определение RAID Advisory Board
RAID 0 был представлен индустрией как определение не отказоустойчивого дискового массива. В Беркли RAID 1 был определен как зеркальный дисковый массив. RAID 2 зарезервирован для массивов, которые применяют код Хемминга. Уровни RAID 3, 4, 5 используют четность для защиты данных от одиночных неисправностей. Именно эти уровни, включительно по 5-й были представлены в Беркли, и эта систематика RAID была принята как стандарт де-факто.
Для стандартизации продуктов RAID в 1992 году был организован промышленный консорциум — RAID Advisory Board. Подробно о работе консорциума можно узнать на сайте: www.raidadvisory.org.
Уровни RAID 3,4,5 достаточно популярны, имеют хороший коэффициент использования дискового пространства, но у них есть один существенный недостаток — они устойчивы только к одиночным неисправностям. Особенно это актуально при использовании большого количества дисков, когда вероятность одновременного простоя более чем одного устройства увеличивается. Кроме того, для них характерно длительное восстановление, что также накладывает некоторые ограничения для их использования.
На сегодняшний день разработано достаточно большое количество архитектур, которые обеспечивают работоспособность массива при одновременном отказе любых двух дисков без потери данных. Среди всего множества стоит отметить two-dimensional parity (двухпространственная четность) и EVENODD, которые для кодирования используют четность, и RAID 6, в котором используется кодирование Reed-Solomon.
В схеме использующей двухпространственную четность, каждый блок данных участвует в построении двух независимых кодовых слов. Таким образом, если из строя выходит второй диск в том же кодовом слове, для реконструкции данных используется другое кодовое слово.
Минимальная избыточность в таком массиве достигается при равном количестве столбцов и строчек. И равна: 2 x Square (NDisk) (в «квадрат»).
Если же двухпространственный массив не будет организован в «квадрат», то при реализации вышеуказанной схемы избыточность будет выше.
Архитектура EVENODD имеет похожую на двухпространственную четность схему отказоустойчивости, но другое размещение информационных блоков, которое гарантирует минимальное избыточное использование емкостей. Так же как и в двухпространственной четности каждый блок данных участвует в построении двух независимый кодовых слов, но слова размещены таким образом, что коэффициент избыточности постоянен (в отличие от предыдущей схемы) и равен: 2 x Square (NDisk).
Используя два символа для проверки, четность и недвоичные коды, слово данных может быть сконструировано таким образом, чтобы обеспечить отказоустойчивость при возникновении двойной неисправности. Такая схема известна как RAID 6. Недвоичный код, построенный на основе Reed-Solomon кодирования, обычно вычисляется с использованием таблиц или как итерационный процесс с использованием линейных регистров с обратной связью, а это — относительно сложная операция, требующая специализированных аппаратных средств.
Учитывая то, что применение классических вариантов RAID, реализующих для многих приложений достаточную отказоустойчивость, имеет часто недопустимо низкое быстродействие, исследователи время от времени реализуют различные ходы, которые помогают увеличить быстродействие RAID систем.
В 1996 г. Саведж и Вилкс предложили AFRAID — часто избыточный массив независимых дисков (A Frequently Redundant Array of Independent Disks). Эта архитектура в некоторой степени приносит отказоустойчивость в жертву быстродействию. Делая попытку компенсировать проблему малой записи (small-write problem), характерную для массивов RAID 5-го уровня, разрешается оставлять стрипинг без вычисления четности на некоторый период времени. Если диск, предназначенный для записи четности, занят, то ее запись откладывается. Теоретически доказано, что 25% уменьшение отказоустойчивости может увеличить быстродействие на 97%. AFRAID фактически изменяет модель отказов массивов устойчивых к одиночным неисправностям, поскольку кодовое слово, которое не имеет обновленной четности, восприимчиво к отказам дисков.
Вместо того чтобы приносить в жертву отказоустойчивость, можно использовать такие традиционные способы увеличения быстродействия, как кэширование. Учитывая то, что дисковый трафик имеет пульсирующий характер, можно использовать кеш память с обратной записью (writeback cache) для хранения данных в момент, когда диски заняты. И если кеш-память будет выполнена в виде энергонезависимой памяти, тогда, в случае исчезновения питания, данные будут сохранены. Кроме того, отложенные дисковые операции, дают возможность объединить в произвольном порядке малые блоки для выполнения более эффективных дисковых операций.
Существует также множество архитектур, которые, принося в жертву объем, увеличивают быстродействие. Среди них — отложенная модификация на log диск и разнообразные схемы модификации логического размещение данных в физическое, которые позволяют распределять операции в массиве более эффективно.
Один из вариантов — parity logging (регистрация четности), который предполагает решение проблемы малой записи (small-write problem) и более эффективного использования дисков. Регистрация четности предполагает отложение изменения четности в RAID 5, записывая ее в FIFO log (журнал регистраций типа FIFO), который размещен частично в памяти контроллера и частично на диске. Учитывая то, что доступ к полному треку в среднем в 10 раз более эффективен, чем доступ к сектору, с помощью регистрации четности собираются большие количества данных модифицированной четности, которые потом все вместе записываются на диск, предназначенный для хранения четности по всему треку.
Архитектура floating data and parity (плавающие данные и четность), которая разрешает перераспределить физическое размещение дисковых блоков. Свободные сектора размещаются на каждом цилиндре для уменьшения rotational latency (задержки вращения), данные и четность размещаются на этих свободных местах. Для того, чтобы обеспечить работоспособность при исчезновении питания, карту четности и данных нужно сохранять в энергонезависимой памяти. Если потерять карту размещения все данные в массиве будут потеряны.
Virtual stripping — представляет собой архитектуру floating data and parity с использованием writeback cache. Естественно реализуя положительные стороны обеих.
Кроме того, существуют и другие способы повышения быстродействия, например распределение RAID операций. В свое время фирма Seagate встроила поддержку RAID операций в свои диски с интерфейсом Fibre Chanel и SCSI. Что дало возможность уменьшить трафик между центральным контроллером и дисками в массиве для систем RAID 5. Это было кардинальным новшеством в сфере реализаций RAID, но технология не получила путевки в жизнь, так как некоторые особенности Fibre Chanel и SCSI стандартов ослабляют модель отказов для дисковых массивов.
Для того же RAID 5 была представлена архитектура TickerTAIP. Выглядит она следующим образом — центральный механизм управления originator node (узел-инициатор) получает запросы пользователя, выбирает алгоритм обработки и затем передает работу с диском и четность worker node (рабочий узел). Каждый рабочий узел обрабатывает некоторое подмножество дисков в массиве. Как и в модели фирмы Seagate, рабочие узлы передают данные между собой без участия узла-инициатора. В случае отказа рабочего узла, диски, которые он обслуживал, становятся недоступными. Но если кодовое слово построено так, что каждый его символ обрабатывается отдельным рабочим узлом, то схема отказоустойчивости повторяет RAID 5. Для предупреждения отказов узла-инициатора он дублируется, таким образом, мы получаем архитектуру, устойчивую к отказам любого ее узла. При всех своих положительных чертах эта архитектура страдает от проблемы «ошибки записи» («;write hole»). Что подразумевает возникновение ошибки при одновременном изменении кодового слова несколькими пользователями и отказа узла.
Следует также упомянуть достаточно популярный способ быстрого восстановления RAID — использование свободного диска (spare). При отказе одного из дисков массива, RAID может быть восстановлен с использованием свободного диска вместо вышедшего из строя. Основной особенностью такой реализации есть то, что система переходит в свое предыдущее (отказоустойчивое состояние без внешнего вмешательства). При использовании архитектуры распределения свободного диска (distributed sparing), логические блоки spare диска распределяются физически по всем дискам массива, снимая необходимость перестройки массива при отказе диска.
Для того чтобы избежать проблемы восстановления, характерной для классических уровней RAID, используется также архитектура, которая носит название parity declustering (распределение четности). Она предполагает размещение меньшего количества логических дисков с большим объемом на физические диски меньшего объема, но большего количества. При использовании этой технологии время реакции системы на запрос во время реконструкции улучшается более чем вдвое, а время реконструкции — значительно уменьшается.
Архитектура основных уровней RAID
Теперь давайте рассмотрим архитектуру основных уровней (basic levels) RAID более детально. Перед рассмотрением примем некоторые допущения. Для демонстрации принципов построения RAID систем рассмотрим набор из N дисков (для упрощения N будем считать четным числом), каждый из которых состоит из M блоков.
Данные будем обозначать — Dm,n, где m — число блоков данных, n — число подблоков, на которые разбивается блок данных D.
Диски могут подключаться как к одному, так и к нескольким каналам передачи данных. Использование большего количества каналов увеличивает пропускную способность системы.
RAID 0. Дисковый массив без отказоустойчивости (Striped Disk Array without Fault Tolerance)
Представляет собой дисковый массив, в котором данные разбиваются на блоки, и каждый блок записываются (или же считывается) на отдельный диск. Таким образом, можно осуществлять несколько операций ввода-вывода одновременно.
- наивысшая производительность для приложений требующих интенсивной обработки запросов ввода/вывода и данных большого объема;
- простота реализации;
- низкая стоимость на единицу объема.
- не отказоустойчивое решение;
- отказ одного диска влечет за собой потерю всех данных массива.
RAID 1. Дисковый массив с дублированием или зеркалка (mirroring)
Зеркалирование — традиционный способ для повышения надежности дискового массива небольшого объема. В простейшем варианте используется два диска, на которые записывается одинаковая информация, и в случае отказа одного из них остается его дубль, который продолжает работать в прежнем режиме.
- простота реализации;
- простота восстановления массива в случае отказа (копирование);
- достаточно высокое быстродействие для приложений с большой интенсивностью запросов.
- высокая стоимость на единицу объема — 100% избыточность;
- невысокая скорость передачи данных.
RAID 2. Отказоустойчивый дисковый массив с использованием кода Хемминга (Hamming Code ECC).
Избыточное кодирование, которое используется в RAID 2, носит название кода Хемминга. Код Хемминга позволяет исправлять одиночные и обнаруживать двойные неисправности. Сегодня активно используется в технологии кодирования данных в оперативной памяти типа ECC. И кодировании данных на магнитных дисках.
В данном случае показан пример с фиксированным количеством дисков в связи с громоздкостью описания (слово данных состоит из 4 бит, соответственно ECC код из 3-х).
- быстрая коррекция ошибок («на лету»);
- очень высокая скорость передачи данных больших объемов;
- при увеличении количества дисков, накладные расходы уменьшаются;
- достаточно простая реализация.
- высокая стоимость при малом количестве дисков;
- низкая скорость обработки запросов (не подходит для систем ориентированных на обработку транзакций).
RAID 3. Отказоустойчивый массив с параллельной передачей данных и четностью (Parallel Transfer Disks with Parity)
Данные разбиваются на подблоки на уровне байт и записываются одновременно на все диски массива кроме одного, который используется для четности. Использование RAID 3 решает проблему большой избыточности в RAID 2. Большинство контрольных дисков, используемых в RAID уровня 2, нужны для определения положения неисправного разряда. Но в этом нет нужды, так как большинство контроллеров в состоянии определить, когда диск отказал при помощи специальных сигналов, или дополнительного кодирования информации, записанной на диск и используемой для исправления случайных сбоев.
- очень высокая скорость передачи данных;
- отказ диска мало влияет на скорость работы массива;
- малые накладные расходы для реализации избыточности.
- непростая реализация;
- низкая производительность при большой интенсивности запросов данных небольшого объема.
RAID 4. Отказоустойчивый массив независимых дисков с разделяемым диском четности (Independent Data disks with shared Parity disk)
Данные разбиваются на блочном уровне. Каждый блок данных записывается на отдельный диск и может быть прочитан отдельно. Четность для группы блоков генерируется при записи и проверяется при чтении. RAID уровня 4 повышает производительность передачи небольших объемов данных за счет параллелизма, давая возможность выполнять более одного обращения по вводу/выводу одновременно. Главное отличие между RAID 3 и 4 состоит в том, что в последнем, расслоение данных выполняется на уровне секторов, а не на уровне битов или байтов.
- очень высокая скорость чтения данных больших объемов;
- высокая производительность при большой интенсивности запросов чтения данных;
- малые накладные расходы для реализации избыточности.
- достаточно сложная реализация;
- очень низкая производительность при записи данных;
- сложное восстановление данных;
- низкая скорость чтения данных малого объема при единичных запросах;
- асимметричность быстродействия относительно чтения и записи.
RAID 5. Отказоустойчивый массив независимых дисков с распределенной четностью (Independent Data disks with distributed parity blocks)
Этот уровень похож на RAID 4, но в отличие от предыдущего четность распределяется циклически по всем дискам массива. Это изменение позволяет увеличить производительность записи небольших объемов данных в многозадачных системах. Если операции записи спланировать должным образом, то, возможно, параллельно обрабатывать до N/2 блоков, где N — число дисков в группе.
- высокая скорость записи данных;
- достаточно высокая скорость чтения данных;
- высокая производительность при большой интенсивности запросов чтения/записи данных;
- малые накладные расходы для реализации избыточности.
- низкая скорость чтения/записи данных малого объема при единичных запросах;
- достаточно сложная реализация;
- сложное восстановление данных.
RAID 6. Отказоустойчивый массив независимых дисков с двумя независимыми распределенными схемами четности (Independent Data disks with two independent distributed parity schemes)
Данные разбиваются на блочном уровне, аналогично RAID 5, но в дополнение к предыдущей архитектуре используется вторая схема для повышения отказоустойчивости. Эта архитектура является устойчивой к двойным отказам. Однако при выполнении логической записи реально происходит шесть обращений к диску, что сильно увеличивает время обработки одного запроса.
- высокая отказоустойчивость;
- достаточно высокая скорость обработки запросов;
- относительно малые накладные расходы для реализации избыточности.
- очень сложная реализация;
- сложное восстановление данных;
- очень низкая скорость записи данных.
Современные RAID контроллеры позволяют комбинировать различные уровни RAID. Таким образом, можно реализовать системы, которые объединяют в себе достоинства различных уровней, а также системы с большим количеством дисков. Обычно это комбинация нулевого уровня (stripping) и какого либо отказоустойчивого уровня.
RAID 10. Отказоустойчивый массив с дублированием и параллельной обработкой
Эта архитектура являет собой массив типа RAID 0, сегментами которого являются массивы RAID 1. Он объединяет в себе очень высокую отказоустойчивость и производительность.
- высокая отказоустойчивость;
- высокая производительность.
- очень высокая стоимость;
- ограниченное масштабирование.
RAID 30. Отказоустойчивый массив с параллельной передачей данных и повышенной производительностью.
Представляет собой массив типа RAID 0, сегментами которого являются массивы RAID 3. Он объединяет в себе отказоустойчивость и высокую производительность. Обычно используется для приложений требующих последовательной передачи данных больших объемов.
- высокая стоимость;
- ограниченное масштабирование.
RAID 50. Отказоустойчивый массив с распределенной четностью и повышенной производительностью
Являет собой массив типа RAID 0, сегментами которого являются массивы RAID 5. Он объединяет в себе отказоустойчивость и высокую производительность для приложений с большой интенсивностью запросов и высокую скорость передачи данных.
- высокая отказоустойчивость;
- высокая скорость передачи данных;
- высокая скорость обработки запросов.
RAID 7. Отказоустойчивый массив, оптимизированный для повышения производительности. (Optimized Asynchrony for High I/O Rates as well as High Data Transfer Rates). RAID 7® является зарегистрированной торговой маркой Storage Computer Corporation (SCC)
Для понимания архитектуры RAID 7 рассмотрим ее особенности:
- Все запросы на передачу данных обрабатываются асинхронно и независимо.
- Все операции чтения/записи кэшируются через высокоскоростную шину x-bus.
- Диск четности может быть размещен на любом канале.
- В микропроцессоре контроллера массива используется операционная система реального времени ориентированная на обработку процессов.
- Система имеет хорошую масштабируемость: до 12 host-интерфейсов и до 48 дисков.
- Операционная система контролирует коммуникационные каналы.
- Используются стандартные SCSI диски, шины, материнские платы и модули памяти.
- Используется высокоскоростная шина X-bus для работы с внутренней кеш памятью.
- Процедура генерации четности интегрирована в кеш.
- Диски, присоединенные к системе, могут быть задекларированы как отдельно стоящие.
- Для управления и мониторинга системы можно использовать SNMP агент.
- высокая скорость передачи данных и высокая скорость обработки запросов (1.5 — 6 раз выше других стандартных уровней RAID);
- высокая масштабируемость хост интерфейсов;
- скорость записи данных увеличивается с увеличением количества дисков в массиве;
- для вычисления четности нет необходимости в дополнительной передаче данных.
- собственность одного производителя;
- очень высокая стоимость на единицу объема;
- короткий гарантийный срок;
- не может обслуживаться пользователем;
- нужно использовать блок бесперебойного питания для предотвращения потери данных из кеш памяти.
Рассмотрим теперь стандартные уровни вместе для сравнения их характеристик. Сравнение производится в рамках архитектур, упомянутых в таблице.
RAIDМинимум дисковПотребность в дискахОтказо-устойчивостьСкорость передачи данныхИнтенсивность обработки запросовПрактическое использование
02N< 1 диск< RAID 3очень высокая до N х 1 дискГрафика, видео
272N< RAID 1~ RAID 3Низкаямейнфреймы
33N+1< RAID 1< RAID 7НизкаяГрафика, видео
43N+1< RAID 1R < RAID 3 W < RAID 5R = RAID 0 W << 1 дискфайл-серверы
53N+1< RAID 1R < RAID 4 W < RAID 3R = RAID 0 W < 1 дисксерверы баз данных
712N+1< RAID 1самая высокаясамая высокаяразные типы приложений
- * — рассматривается обычно используемый вариант;
- k — количество подсегментов;
- R — чтение;
- W — запись.
Некоторые аспекты реализации RAID систем
Рассмотрим три основных варианта реализации RAID систем:
- программная (software-based);
- аппаратная — шинно-ориентированная (bus-based);
- аппаратная — автономная подсистема (subsystem-based).
Нельзя однозначно сказать, что какая-либо реализация лучше, чем другая. Каждый вариант организации массива удовлетворяет тем или иным потребностям пользователя в зависимости от финансовых возможностей, количества пользователей и используемых приложений.
Каждая из вышеперечисленных реализаций базируется на исполнении программного кода. Отличаются они фактически тем, где этот код исполняется: в центральном процессоре компьютера (программная реализация) или в специализированном процессоре на RAID контроллере (аппаратная реализация).
Главное преимущество программной реализации — низкая стоимость. Но при этом у нее много недостатков: низкая производительность, загрузка дополнительной работой центрального процессора, увеличение шинного трафика. Программно обычно реализуют простые уровни RAID — 0 и 1, так как они не требуют значительных вычислений. Учитывая эти особенности, RAID системы с программной реализацией используются в серверах начального уровня.
Аппаратные реализации RAID соответственно стоят больше чем программные, так как используют дополнительную аппаратуру для выполнения операций ввода вывода. При этом они разгружают или освобождают центральный процессор и системную шину и соответственно позволяют увеличить быстродействие.
Шинно-ориентированные реализации представляют собой RAID контроллеры, которые используют скоростную шину компьютера, в который они устанавливаются (в последнее время обычно используется шина PCI). В свою очередь шинно-ориентированные реализации можно разделить на низкоуровневые и высокоуровневые. Первые обычно не имеют SCSI чипов и используют так называемый RAID порт на материнской плате со встроенным SCSI контроллером. При этом функции обработки кода RAID и операций ввода/вывода распределяются между процессором на RAID контроллере и чипами SCSI на материнской плате. Таким образом, центральный процессор освобождается от обработки дополнительного кода и уменьшается шинный трафик по сравнению с программным вариантом. Стоимость таких плат обычно небольшая, особенно если они ориентированы на системы RAID — 0 или 1 (есть также реализации RAID 3, 5, 10, 30, 50, но они дороже), благодаря чему они понемногу вытесняют программные реализации с рынка серверов начального уровня. Высокоуровневые контроллеры с шинной реализацией имеют несколько другую структуру, чем их младшие братья. Они берут на себя все функции, связанные с вводом/выводом и исполнением RAID кода. Кроме того, они не так зависимы от реализации материнской платы и, как правило, имеют больше возможностей (например, возможность подключения модуля для хранения информации в кеш в случае отказа материнской платы или исчезновения питания). Такие контроллеры обычно стоят дороже низкоуровневых и используются в серверах среднего и высокого уровня. Они, как правило, реализуют RAID уровней 0,1, 3, 5, 10, 30, 50. Учитывая то, что шинно-ориентированные реализации подключаются прямо к внутренней PCI шине компьютера, они являются наиболее производительными среди рассматриваемых систем (при организации одно-хостовых систем). Максимальное быстродействие таких систем может достигать 132 Мбайт/с (32bit PCI) или же 264 Мбайт/с (64bit PCI) при частоте шины 33MHz.
Вместе с перечисленными преимуществами шинно-ориентированная архитектура имеет следующие недостатки:
- зависимость от операционной системы и платформы;
- ограниченная масштабируемость;
- ограниченные возможности по организации отказоустойчивых систем.
Всех этих недостатков можно избежать, используя автономные подсистемы. Эти системы имеют полностью автономную внешнюю организацию и в принципе являют собой отдельный компьютер, который используется для организации систем хранения информации. Кроме того, в случае удачного развития технологии оптоволоконных каналов быстродействие автономных систем ни в чем не будет уступать шинно-ориентированным системам.
Обычно внешний контроллер ставится в отдельную стойку и в отличие от систем с шинной организацией может иметь большое количество каналов ввода/вывода, в том числе и хост-каналов, что дает возможность подключать к системе несколько хост-компьютеров и организовывать кластерные системы. В системах с автономным контроллером можно реализовать горячее резервирование контроллеров.
Одним из недостатков автономных систем остается их большая стоимость.
Учитывая вышесказанное, отметим, что автономные контроллеры обычно используются для реализации высокоемких хранилищ данных и кластерных систем.
