

Вернуться к списку форумов
- Права доступа
- Post navigation
- Подготовка
- Мониторинг событий безопасности MS Windows Server
- Мониторинг событий безопасности Unix систем
- Мониторинг событий ИБ на сетевых устройствах
- Заключение
- Магия регулярных выражений
- Количество используемых инод
- Количество используемого места
- Производительность томов
- Problem
- Several other monitoring items
- Алертинг
- Визуализация
- My idea
- Create a SSH monitoring template
- SSH login automatic log log
- Test
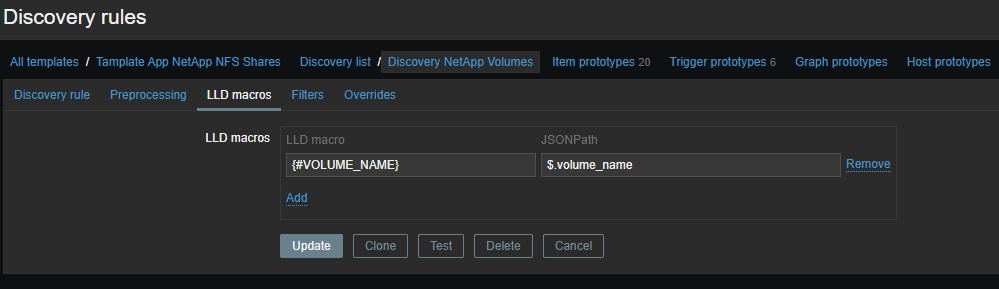
- Низкоуровневое обнаружение (LLD)
- Элементы данных
- Итоги
Права доступа
Вы не можете
начинать темы
Вы не можете
отвечать на сообщения
Вы не можете
редактировать свои сообщения
Вы не можете
удалять свои сообщения
Вы не можете
добавлять вложения
On Linux, SSH connection logs are stored in a file:
- RHEL/Rocky/Oracle Linux:
/var/log/secure - Ubuntu/Debian:
/var/log/auth.log
$ sudo chgrp zabbix /var/log/auth.log
$ sudo chmod 640 /var/log/auth.log The next step is to configure the Zabbix template for SSH log monitoring.
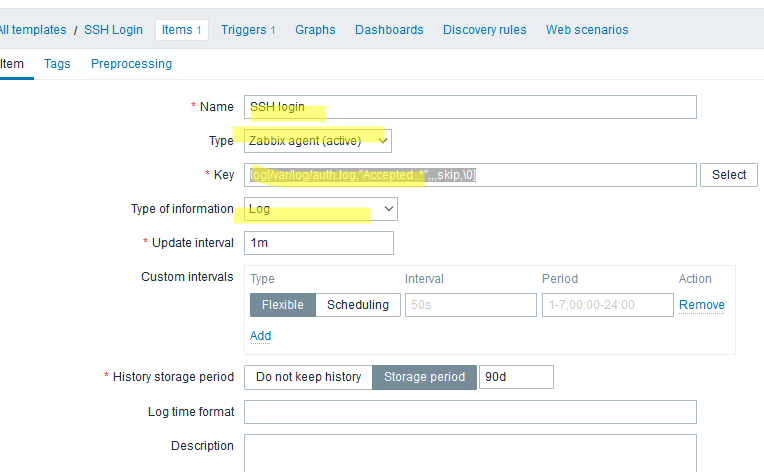
- Name:
SSH login - Type: Zabbix agent (active)
- Key:
log[/var/log/auth.log,"Accepted .*",,,skip,\0] - Type of information: Log
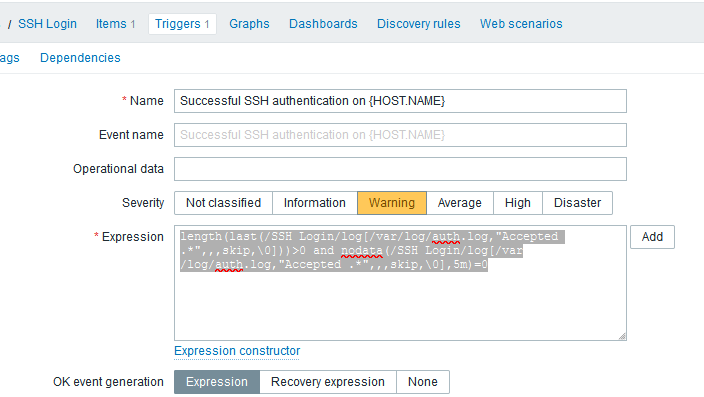
Configure a trigger for your item:
- Name:
Successful SSH authentication on {HOST.NAME} - Expression:
length(last(/SSH Login/log[/var/log/auth.log,"Accepted .*",,,skip,\0]))>0 and nodata(/SSH Login/log[/var/log/auth.log,"Accepted .*",,,skip,\0],5m)=0

You can enable and configure a trigger to send notifications from Zabbix to mail or Telegram ( How to send Zabbix notification to Telegram
).

Всем привет, меня зовут Игорь Сидоренко. Одной из основных сфер моей работы, а также моим хобби является мониторинг. Я расскажу о Zabbix и о том, как с его помощью замониторить необходимую нам информацию о томах NetApp, имея доступ только по SSH. Кому интересна тема мониторинга и Zabbix, прошу под кат.
Изначально мы мониторили тома, монтируя их к определенному серверу, на котором висел специальный шаблон, отлавливающий NFS-маунты на ноде и ставящий их на мониторинг, по аналогии с файловыми системами базового шаблона Linux. Маунт надо было прописать в fstab и примонтировать вручную — из-за этого многое терялось и забывалось.
Потом мне пришла в голову прекрасная идея: надо всё это автоматизировать. Было несколько вариантов:
-
Есть готовые шаблоны, работающие с SNMP, но доступов нет. -
Получение списка томов и автоматический маунт на ноде: надо создавать папку, прописывать fstab, маунтить вот это всё, слишком много геморроя. -
Есть же великолепный API
, но т.к мы арендуем только место, то в нашей версии ONTAP он урезан и не дает пользователю нужную информацию. - Как-то использовать доступ по SSH для получения томов и постановки их на мониторинг.
Выбор пал на SSH-агент
.
Шаблон для Входы Выходы Пользователей SSH Auth journalctl Alt Linux
Запрос будет выполнятся через ключ log
6 МОНИТОРИНГ ФАЙЛОВ ЖУРНА
Работает через активный заббикс агент, обязательное точное имя и регистр Hostname , а так же Указаны сервера в параметре ServerActive
Формат времени журнала
Поддерживаемые значения:
* y: Год (0001-9999)
* M: Месяц (01-12)
* d: День (01-31)
* h: Час (00-23)
* m: Минута (00-59)
* s: Секунда (00-59)
Например hh:mm:ss yyyy/MM/dd или ddMMyyyy:hhmmss или pppppp:yyyyMMdd:hhmmss
символы “p” и “:” являются лишь заменителями и могут быть чем угодно
Если Zabbix agent работает под пользователем zabbix нужно дать права на чтение файла лога
Для Debian/Ubuntu
chgrp zabbix /var/log/auth.log
chmod 640 /var/log/auth.log
Для Centos
chgrp zabbix /var/log/secure
chmod 640 /var/log/secure
если Zabbix agent работает от root то можно не выполнять данные команды.
Я пользовался данным шаблоном он в целом отображал входы выходы, но был нюанс сессию мог перебить любой другой пользователь вошедший в систему и так же вышедший из системы. Т.е. с одним пользователем все хорошо с несколькими нет, смотрит только на последнюю запись был вход показывает последний вход, выход закрытие проблемы хотя другие пользователи сессии могут остаться открытыми.
Делая шаблон для Входы Выходы Пользователей SSH Auth journalctl Alt Linux
и более подробно разобравшись в логах.
Искать строку для входа можем по следующим регуляркам или содержанием строки Accepted ; opened ; New
Искать строку для выхода можем по следующим регуляркам или содержанием строки closed ; Removed и не совсем подходит disconnect ; Disconnected
Результат:
1 — найдено
0 — в противном случае
Если обрабатывается более одного значения, ‘1’ возвращается, если имеется по крайней мере одно совпадающее значение.
Эта функция является чувствительной к регистру.
-
 12107 просмотров")
- SSH auth.log Debian Ubuntu Элемент данных Accepted.jpg
Генерация ОК событий Выражение восстановления
-
 12107 просмотров")
- SSH auth.log Debian Ubuntu Триггер данных Accepted.jpg
-
 12107 просмотров")
- SSH auth.log Debian Ubuntu Триггер Теги данных Accepted.jp
-
 12105 просмотров")
- SSH auth.log Debian Ubuntu Элемент данных systemd-logind
Режим генерации событий ПРОБЛЕМА Множественный
ОК событие закрывает Все проблемы если значения тегов совпадают
-
 12105 просмотров")
- SSH auth.log Debian Ubuntu Триггер systemd-logind.jpg
-
 12105 просмотров")
- SSH auth.log Debian Ubuntu Триггер теги systemd-logind
Настройка Хоста если не идут данные из лога
мониторить системный log файл, который содержит информацию о ssh подключениях.
В rpm дистрибутивах, в частности, в Centos это /var/log/secure. В deb дистрибутивах Debian/Ubuntu это /var/log/auth.log.
Все будет сделано с использованием штатного функционала zabbix.
На хостах не нужно ничего настраивать, кроме выдачи прав на чтение к лог-файлу группе zabbix.
# chgrp zabbix /var/log/secure
# chmod 640 /var/log/secure
в Debian/Ubuntu
# chgrp zabbix /var/log/auth.log
# chmod 640 /var/log/auth.log
# chmod g+r /var/log/auth.log
Перезапустить агент
-
 12103 просмотра")
- test-SSH auth.log Debian Ubuntu Элементы.jpg
-
 12103 просмотра")
- test-SSH auth.log Debian Ubuntu Триггеры.jpg

Некоторое время поработав с Zabbix, я подумал, почему бы не попробовать использовать его в качестве решения для мониторинга событий информационной безопасности. Как известно, в ИТ инфраструктуре предприятия множество самых разных систем, генерирующих такой поток событий информационной безопасности, что просмотреть их все просто невозможно. Сейчас в нашей корпоративной системе мониторинга сотни сервисов, которые мы наблюдаем с большой степенью детализации. В данной статье, я рассматриваю особенности использования Zabbix в качестве решения по мониторингу событий ИБ.
Что же позволяет Zabbix для решения нашей задачи? Примерно следующее:
- Максимальная автоматизация процессов инвентаризации ресурсов, управления уязвимостями, контроля соответствия политикам безопасности и изменений.
- Постоянная защита корпоративных ресурсов с помощью автоматического мониторинга информационной безопасности.
- Возможность получать максимально достоверную картину защищенности сети.
- Анализ широкого спектра сложных систем: сетевое оборудование, такое как Cisco, Juniper, платформы Windows, Linux, Unix, СУБД MSQL, Oracle, MySQL и т.д., сетевые приложения и веб-службы.
- Минимизация затрат на аудит и контроль защищенности.
В статье я не буду рассматривать всё выше перечисленное, затронем только наиболее распространённые и простые вопросы.
Подготовка
Итак, для начала я установил сервер мониторинга Zabbix. В качестве платформы мы будем использовать ОС FreeBSD. Думаю, что рассказывать в деталях о процессе установки и настройки нет необходимости, довольно подробная документация
на русском языке есть на сайте разработчика, начиная от процесса установки до описания всех возможностей системы.
Мы будем считать что сервер установлен, настроен, а так же настроен web-frontend для работы с ним. На момент написания статьи система работает под управлением ОС FreeBSD 9.1, Zabbix 2.2.1.
Мониторинг событий безопасности MS Windows Server
Всё, что остаётся – определить события возникающие при реализации ожидаемых нами угроз.
Устанавливая решение по мониторингу событий ИБ в ИТ инфраструктуре следует учитывать необходимость выбора баланса между желанием отслеживать всё подряд, и возможностями по обработке огромного количества информации по событиям ИБ. Здесь Zabbix открывает большие возможности для выбора. Ключевые модули Zabbix написаны на C/C++, скорость записи из сети и обработки отслеживаемых событий составляет 10 тысяч новых значений в секунду на более менее обычном сервере с правильно настроенной СУБД.
Всё это даёт нам возможность отслеживать наиболее важные события безопасности на наблюдаемом узле сети под управлением ОС Windows.
Итак, для начала рассмотрим таблицу с Event ID, которые, на мой взгляд, очевидно, можно использовать для мониторинга событий ИБ:
События ИБ MS Windows Server Security Log
Я уделяю внимание локальным группам безопасности, но в более сложных схемах AD необходимо учитывать так же общие и глобальные группы.
Дабы не дублировать информацию, подробнее о критически важных событиях можно почитать в статье:
http://habrahabr.ru/company/netwrix/blog/148501/
Способы мониторинга событий ИБ MS Windows Server
Рассмотрим практическое применение данной задачи.
Для сбора данных необходимо создать новый элемент данных:
Ключ: eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781]
Тип элемента данных: Zabbix агент (активный)
Тип информации: Журнал (лог) 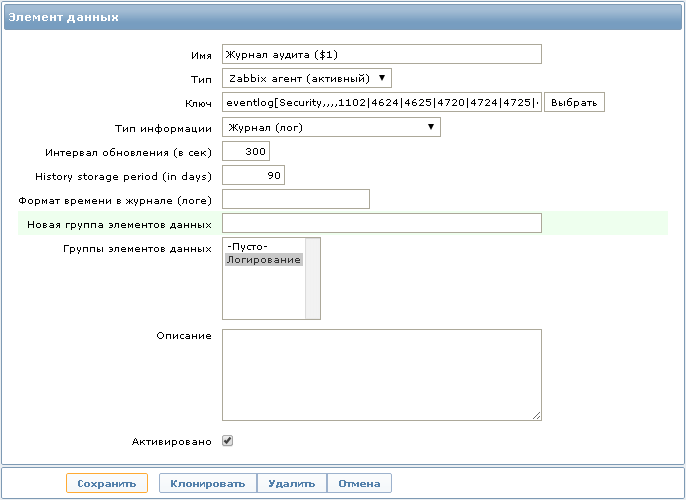
При желании для каждого Event ID можно создать по отдельному элементу данных, но я использую в одном ключе сразу несколько Event ID, чтобы хранить все полученные записи в одном месте, что позволяет быстрее производить поиск необходимой информации, не переключаясь между разными элементами данных.
Хочу заметить что в данном ключе в качестве имени мы используем журнал событий Security.
Теперь, когда элемент данных мы получили, следует настроить триггер. Триггер – это механизм Zabbix, позволяющий сигнализировать о том, что наступило какое-либо из отслеживаемых событий. В нашем случае – это событие из журнала сервера или рабочей станции MS Windows.
Теперь все что будет фиксировать журнал аудита с указанными Event ID будет передано на сервер мониторинга. Указание конкретных Event ID полезно тем, что мы получаем только необходимую информацию, и ничего лишнего.
Вот одно из выражений триггера:
{Template Windows - Eventlog 2008:eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781].logeventid(4624)}=1&{Template Windows - Eventlog 2008:eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781].nodata(5m)}=0 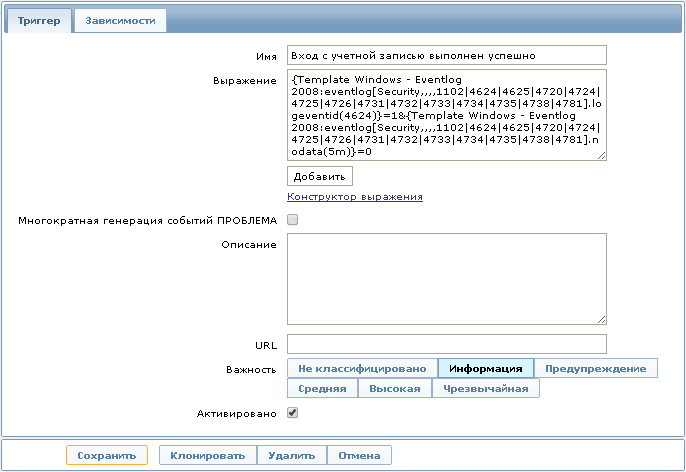
Данное выражение позволит отображать на Dashboard информацию о том что «Вход с учётной записью выполнен успешно», что соответствует Event ID 4624 для MS Windows Server 2008. Событие исчезнет спустя 5 минут, если в течение этого времени не был произведен повторный вход.
Если же необходимо отслеживать определенного пользователя, например “Администратор”, можно добавить к выражению триггера проверку по regexp:
&{Template Windows - Eventlog 2008:eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781,,skip].regexp(Администратор)}=1 Тогда триггер сработает только в том случае если будет осуществлён вход в систему именно под учетной записью с именем “Администратор”.
P. S.
Мы рассматривали простейший пример, но так же можно использовать более сложные конструкции. Например с использованием типов входа в систему, кодов ошибок, регулярных выражений и других параметров.
Таким образом тонны сообщений, генерируемых системами Windows будет проверять Zabbix, а не наши глаза. Нам остаётся только смотреть на панель Zabbix Dashboard.
Дополнительно, у меня настроена отправка уведомлений на e-mail. Это позволяет оперативно реагировать на события, и не пропустить события произошедшие например в нерабочее время.
Мониторинг событий безопасности Unix систем
Система мониторинга Zabbix так же позволяет собирать информацию из лог-файлов ОС семейства Unix.
События ИБ в Unix системах, подходящие для всех
Такими проблемами безопасности систем семейства Unix являются всё те же попытки подбора паролей к учётным записям, а так же поиск уязвимостей в средствах аутентификации, например, таких как SSH, FTP и прочих.
Некоторые критически важные события в Unix системах
Исходя из вышеуказанного следует, что нам необходимо отслеживать действия, связанные с добавлением, изменением и удалением учётных записей пользователей в системе.
Так же немаловажным фактом будет отслеживание попыток входа в систему. Изменения ключевых файлов типа sudoers, passwd, etc/rc.conf, содержимое каталогов /usr/local/etc/rc.d наличие запущенных процессов и т.п.
Способы мониторинга ИБ в Unix системах
Рассмотрим следующий пример. Нужно отслеживать входы в систему, неудачные попытки входа, попытки подбора паролей в системе FreeBSD по протоколу SSH.
Вся информация об этом, содержится в лог-файле /var/log/auth.log.
По умолчанию права на данный файл — 600, и его можно просматривать только с привилегиями root. Придется немного пожертвовать локальной политикой безопасности, и разрешить читать данный файл группе пользователей zabbix:
Меняем права на файл:
chgrp zabbix /var/log/auth.log
chmod 640 /var/log/auth.log Нам понадобится новый элемент данных со следующим ключом:
log[/var/log/auth.log,sshd,,,skip] 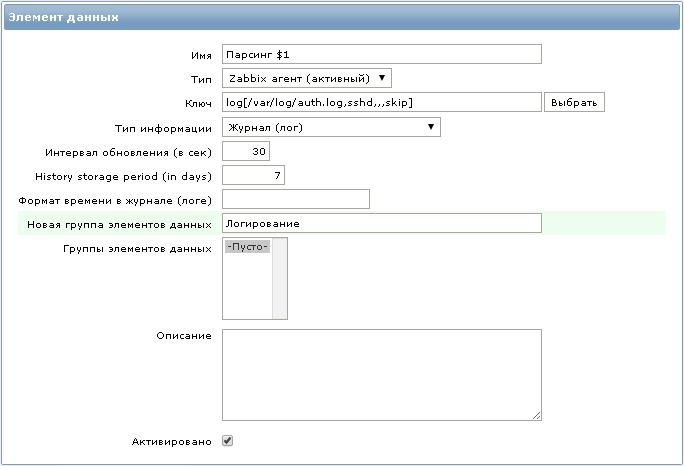
Все строки в файле /var/log/auth.log содержащие слово ”sshd” будут переданы агентом на сервер мониторинга.
Далее можно настроить триггер со следующим выражением:
{Template FreeBSD - SSH:log[/var/log/auth.log,sshd,,,skip].regexp(error:)}|{Template FreeBSD - SSH:log[/var/log/auth.log,sshd,,,skip].regexp(Wrong passwordr:)}&{Template FreeBSD - SSH:log[/var/log/auth.log,sshd,,,skip].nodata(3m)}=0 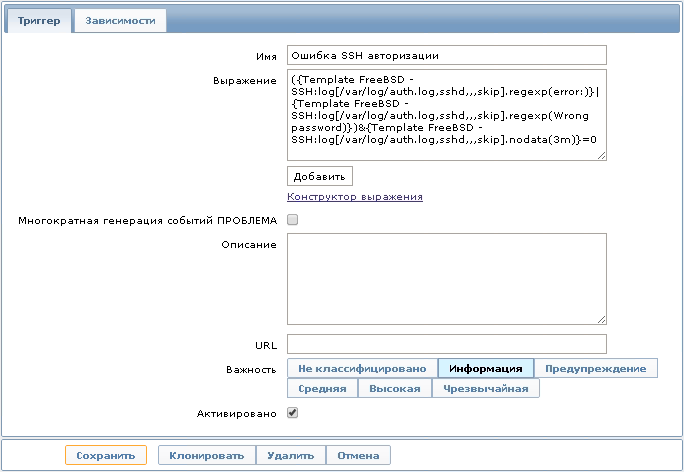
Это выражение определяется как проблема, когда в лог-файле появляются записи, отобранные по регулярному выражению “error:”. Открыв историю полученных данных, мы увидим ошибки, которые возникали при авторизации по протоколу SSH.
Вот пример последнего значения элемента данных, по которому срабатывает данный триггер:

Рассмотрим ещё один пример мониторинга безопасности в ОС FreeBSD:
С помощью агента Zabbix мы можем осуществлять проверку контрольной суммы файла /etc/passwd.
Ключ в данном случае будет следующий:
vfs.file.cksum[/etc/passwd] Это позволяет контролировать изменения учётных записей, включая смену пароля, добавление или удаление пользователей. В данном случае мы не узнаем, какая конкретная операция была произведена, но если к серверу кроме Вас доступ никто не имеет, то это повод для быстрого реагирования. Если необходимо более детально вести политику то можно использовать другие ключи, например пользовательские параметры.
Например, если мы хотим получать список пользователей, которые на данный момент заведены в системе, можно использовать такой пользовательский параметр:
UserParameter=system.users.list, /bin/cat /etc/passwd | grep -v "#" | awk -F\: '{print $1}' И, например, настроить триггер на изменение в получаемом списке.
Или же можно использовать такой простой параметр:
UserParameter=system.users.online, /usr/bin/users Так мы увидим на Dashboard, кто на данный момент находится в системе:
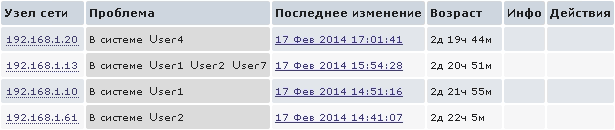
Мониторинг событий ИБ на сетевых устройствах
С помощью Zabbix можно так же очень эффективно отслеживать события ИБ на сетевых устройствах Cisco и Juniper, используя протокол SNMP. Передача данных с устройств осуществляется с помощью так называемых трапов (SNMP Trap).
С точки зрения ИБ можно выделить следующие события, которые необходимо отслеживать — изменения конфигураций оборудования, выполнение команд на коммутаторе/маршрутизаторе, успешную авторизацию, неудачные попытки входа и многое другое.
Способы мониторинга
Рассмотрим опять же пример с авторизацией:
В качестве стенда я буду использовать эмулятор GNS3 с маршрутизатором Cisco 3745. Думаю многим знакома данная схема.
Для начала нам необходимо настроить отправку SNMP трапов с маршрутизатора на сервер мониторинга. В моём случае это будет выглядеть так:
login block-for 30 attempts 3 within 60
login on-failure log
login on-success log
login delay 5
logging history 5
snmp-server enable traps syslog
snmp-server enable traps snmp authentication
snmp-server host 192.168.1.1 public Будем отправлять события из Syslog и трапы аутентификации. Замечу, что удачные и неудачные попытки авторизации пишутся именно в Syslog.
Далее необходимо настроить прием нужных нам SNMP трапов на сервере мониторинга.
Добавляем следующие строки в snmptt.conf:
EVENT clogMessageGenerated .1.3.6.1.4.1.9.9.41.2.0.1 "Status Events" Normal
FORMAT ZBXTRAP $ar $N $*
SDESC
EDESC В нашем примере будем ловить трапы Syslog.
Теперь необходимо настроить элемент данных для сбора статистики со следующим ключом:
snmptrap[“Status”] 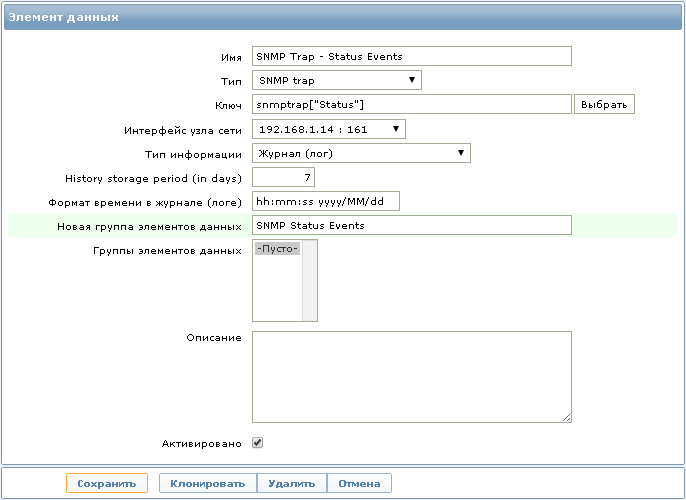
Если трап не настроен на сервере мониторинга, то в логе сервера будут примерно такие записи:
unmatched trap received from [192.168.1.14]:... 
Ну и можно настроить триггер для отображения события на Dashboard:
{192.168.1.14:snmptrap["Status"].regexp(LOGIN_FAILED)}&{192.168.1.14:snmptrap["Status"].nodata(3m)}=0 В сочетании с предыдущим пунктом у нас на Dashboard будет информация вот такого плана:
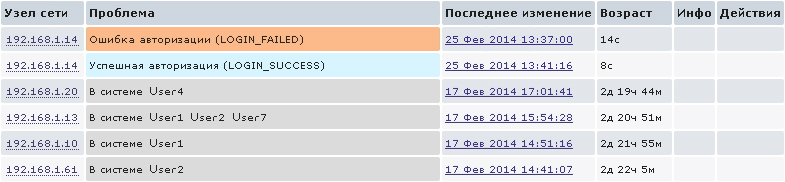
Аналогично вышеописанному примеру можно осуществлять мониторинг большого количества событий, происходящих на маршрутизаторах Cisco, для описания которых одной статьей явно не обойтись.
Хочу заметить что приведённый пример не будет работать на продуктах Cisco ASA и PIX, так как там несколько иначе организована работа с логированием авторизации.
Juniper и Syslog
Ещё одним примером мы разберем мониторинг авторизации в JunOS 12.1 для устройств Juniper.
Тут мы не сможем воспользоваться трапами SNMP, потому как нет поддержки отправки трапов из Syslog сообщений. Нам понадобится Syslog сервер на базе Unix, в нашем случае им будет тот же сервер мониторинга.
На маршрутизаторе нам необходимо настроить отправку Syslog на сервер хранения:
system syslog host 192.168.1.1 authorization info Теперь все сообщения об авторизации будут отправляться на Syslog сервер, можно конечно отправлять все сообщения (any any), но переизбыток информации нам не нужен, отправляем только необходимое.
Далее переходим к Syslog серверу
Смотрим tcpdump, приходят ли сообщения:
tcpdump -n -i em0 host 192.168.1.112 and port 514
12:22:27.437735 IP 192.168.1.112.514 > 192.168.1.1.514: SYSLOG auth.info, length: 106 По умолчанию в настройках syslog.conf все что приходит с auth.info должно записываться в /var/log/auth.log. Далее делаем все аналогично примеру с мониторингом входов в Unix.
Вот пример строки из лога:

Остается только настроить триггер на данное событие так же как это было рассмотрено в примере с авторизацией на Unix сервере.
P. S.
Таким способом можно отслеживать множество событий, среди которых такие как: сохранение конфигурации устройства (commit), вход и выход из режима редактирования конфигурации (edit).
Так же хочу заметить, что аналогичным способом можно осуществлять мониторинг и на устройствах Cisco, но способ с SNMP трапами мне кажется более быстрым и удобным, и исключается необходимость в промежуточном Syslog сервере.
Заключение
В заключении хочу отметить, что я с удовольствием приму замечания и дополнения к данной статье, а так же интересные предложения по использованию мониторинга событий информационной безопасности при помощи Zabbix.
Спасибо за внимание. 🙂
Магия регулярных выражений
Изначально для препроцессинга
я хотел использовать JavaScript, но как-то не осилил, не зашло. Поэтому остановился на регулярках, да и использую их практически везде.
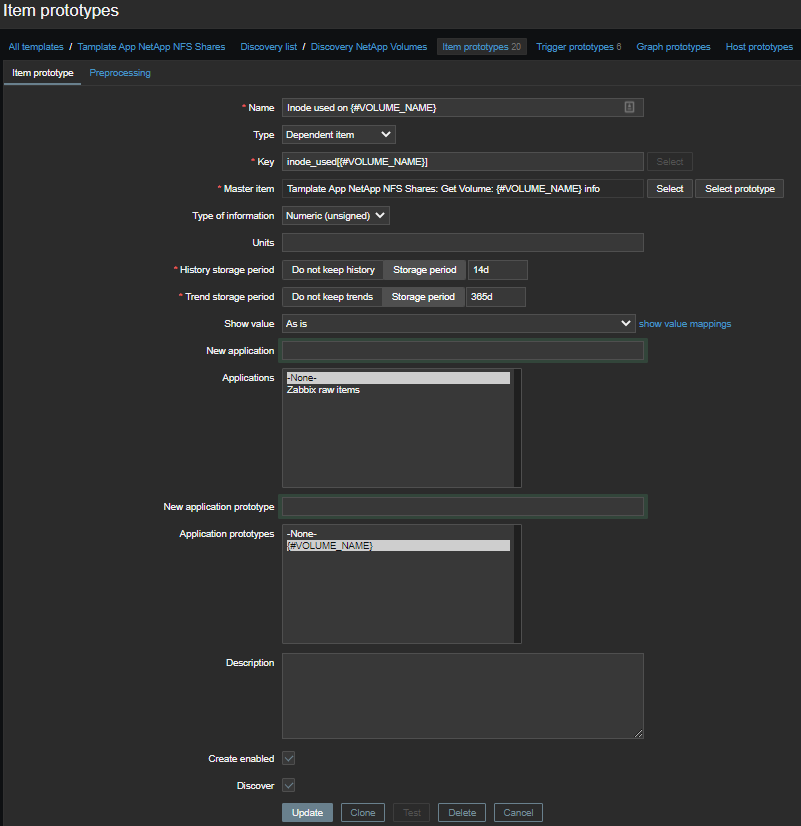
Количество используемых инод
Отберем информацию только о инодах по каждому тому в два этапа:
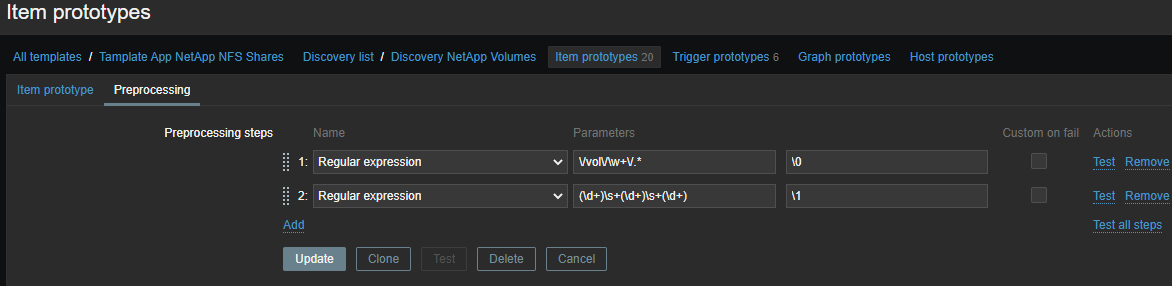
Сначала вся информация:
\/vol\/\w+\/.* 

Потом конкретно по метрикам:
(\d+)\s+(\d+)\s+(\d+) 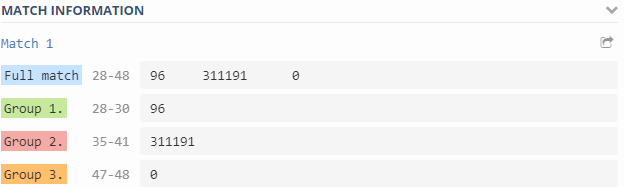

Вывод — шаблон форматирования вывода. \N (где N=1..9)
— управляющая последовательность заменяется N-ной совпадающей группой. Управляющая последовательность \0
заменяется совпадающим текстом:
-
\1 - Inode used on {#VOLUME_NAME}
— количество использованных инод; -
\2 - Inode free on {#VOLUME_NAME}
— количество свободных инод; -
\3 - Inode used percentage on {#VOLUME_NAME}
— использованные иноды в процентах; -
Inode total on {#VOLUME_NAME}
— вычислямый элемент
, количество доступных инод.
last(inode_free[{#VOLUME_NAME}])+last(inode_used[{#VOLUME_NAME}]) Количество используемого места
Здесь всё проще, данные и регулярки в более приятном формате:
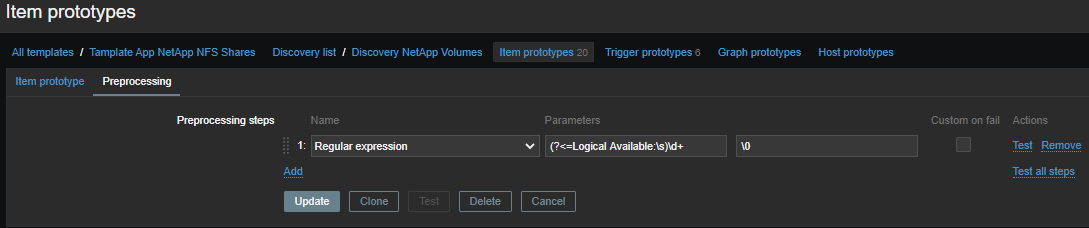
Выдергиваем нужную нам метрику и берем только число:
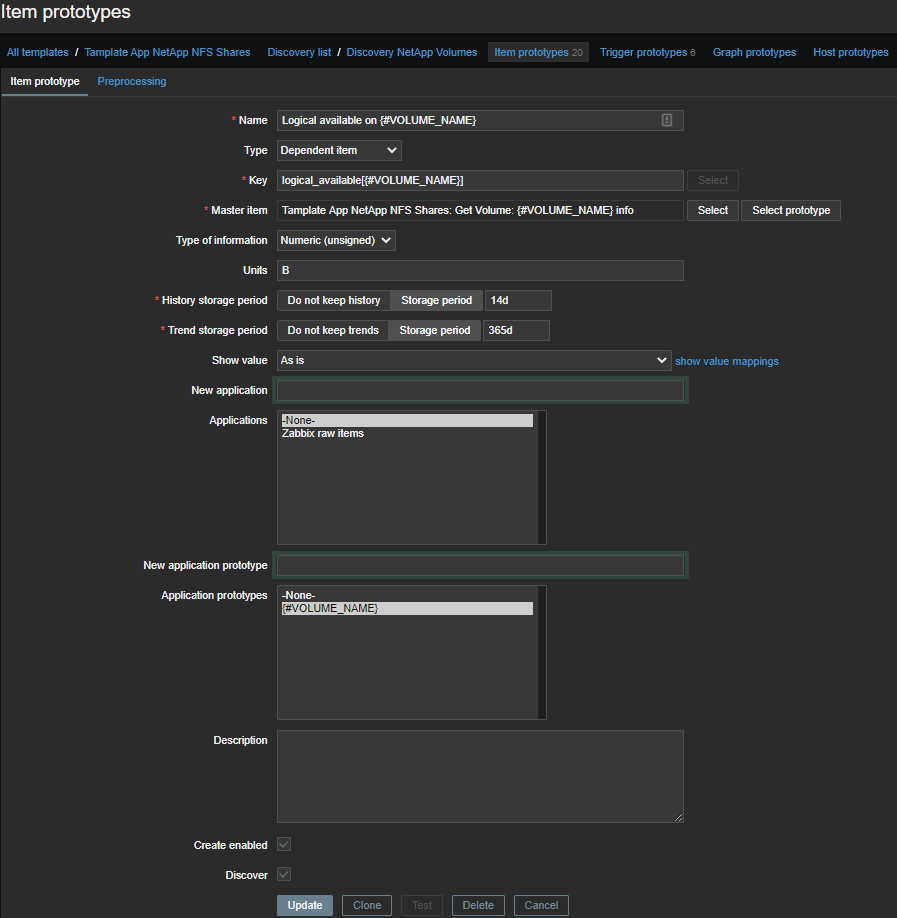
(?<=Logical Available:\s)\d+ 

-
Logical available on {#VOLUME_NAME}
— количество доступного логического места; -
Logical used percent on {#VOLUME_NAME}
— использованное логическое место в процентах; -
Logical used size on {#VOLUME_NAME}
— количество использованного логического места; -
Physical used percentage on {#VOLUME_NAME}
— использованное физическое место в процентах; -
Total physical used size on {#VOLUME_NAME}
— количество использованного физического места; -
Total used on {#VOLUME_NAME}
— всего использовано места; -
Total used percent on {#VOLUME_NAME}
— всего использовано места в процентах; -
Logical size on {#VOLUME_NAME}
— вычисляемый элемент
, количество доступного логического места.
last(logical_available[{#VOLUME_NAME}])+last(total_used[{#VOLUME_NAME}]) Производительность томов
Почитав документацию и потыкав разные команды, я выяснил, что мы можем получать метрики по производительности наших томов. За это отвечает маленький кусочек:
statistics volume show -volume {#VOLUME_NAME} 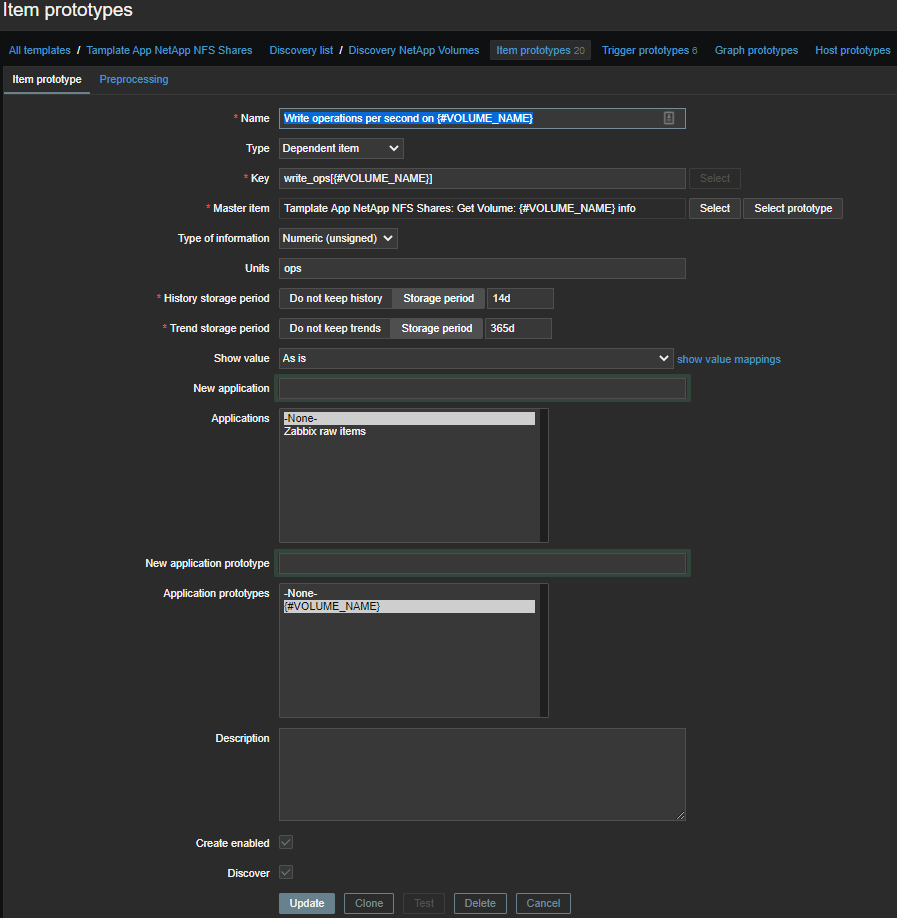
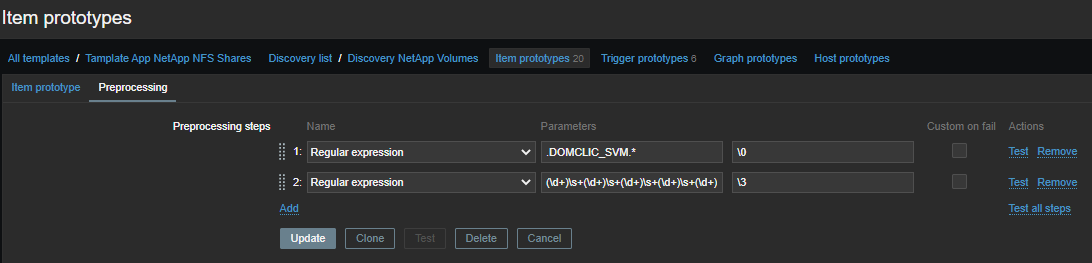
Из общей простыни первой регуляркой мы отбираем метрики по производительности:
.DOMCLIC_SVM.* 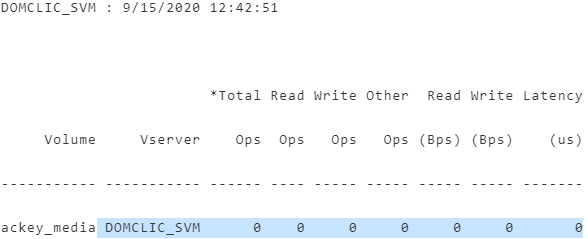

Второй группируем числа:
(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+) 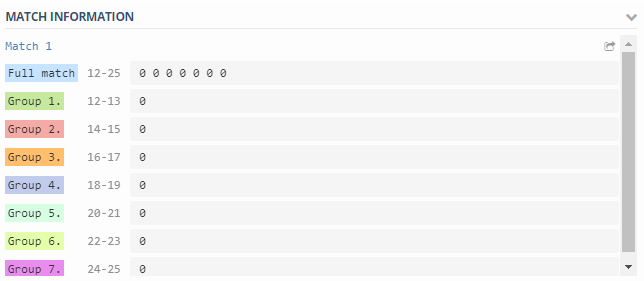
-
\1 - Total number of operations per second on {#VOLUME_NAME}
— общее количество операций в секунду; -
\2 - Read operations per second on {#VOLUME_NAME}
— операций чтения в секунду; -
\3 - Write operations per second on {#VOLUME_NAME}
— операций записи в секунду; -
\4 - Other operations per second on {#VOLUME_NAME}
— другие операции в секунду (не знаю, что это, но зачем-то снимаю); -
\5 - Read throughput in bytes per second on {#VOLUME_NAME}
— скорость чтения в байтах в секунду; -
\6 - Write throughput in bytes per second on {#VOLUME_NAME}
— скорость записи в байтах в секунду; -
\7 - Average latency for an operation in microseconds on {#VOLUME_NAME}
— средняя задержка операций в микросекундах.
Problem
- There are many articles on SSH monitoring, most of the monitoring systems comes with the output of the Last and lastb commands, and point to / var / log / wtmp and / var / log / btmp, respectively.
- When the hacker logs in to SSH, the tool will be used to clear the Last record, followed by it.
- Collect output data, use passive monitoring methods, query recently recorded a large amount of blank or completely repeated records!
- The passive way is to send a query command from the service terminal, and the SSH login cannot be so frequent!
- After discovering the problem as soon as possible, «the dead sheep is completed» is designed to reduce damage loss, not blocking damage.
Several other monitoring items
- There have been three passive mode monitoring items that have been stopped, and you will be simply listed here.
$ cd /etc/zabbix/zabbix_agentd.conf.d
$ cat ssh_login_check.conf
# wzh 20210802 UserParameter=ssh_login_wc,/usr/bin/who | wc -l UserParameter=ssh_login_last,/usr/bin/last UserParameter=ssh_login_check,/etc/zabbix/ssh_login_check.sh The first key value ssh_login_wc monitor is logged in to open several terminals (TERMINAL), and the trigger can take advantage of this value> 0
The second key value ssh_login_last simple output system command last
$ cat /etc/zabbix/ssh_login_check.sh
#!/bin/bash
#
# wzh 20210802
#
cat /var/log/zabbix-agent/ssh.log
# after read,clear
# only the last ssh login is saved
cat /dev/null>/var/log/zabbix-agent/ssh.log Only the monitoring item SSH_Login_WC trigger

expression
Others have added NODATA judgment, I deliberately removed, plus words, this is like this
{Template SSH Login Check by wzh:ssh_login_wc.last()}>0
and
{Template SSH Login Check by wzh:ssh_login_wc.last(#60)}=0 Алертинг
Набор триггеров стандартный, место и иноды:
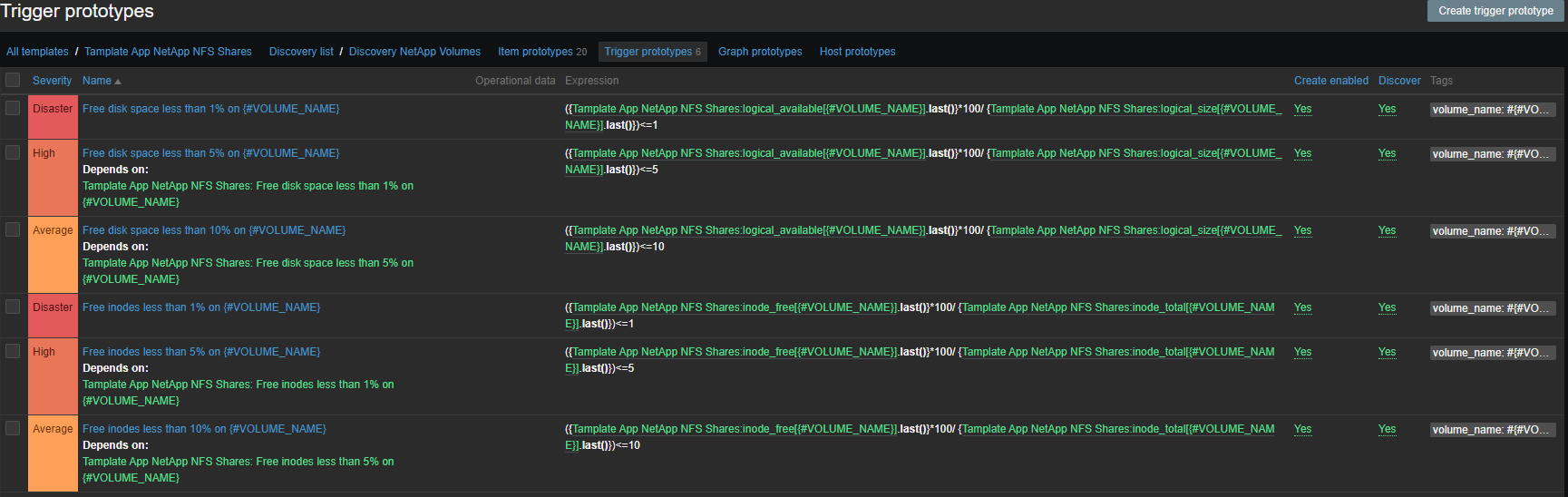
- Free disk space less than 1% on {#VOLUME_NAME}
- Free disk space less than 5% on {#VOLUME_NAME}
- Free disk space less than 10% on {#VOLUME_NAME}
- Free inodes less than 1% on {#VOLUME_NAME}
- Free inodes less than 5% on {#VOLUME_NAME}
- Free inodes less than 10% on {#VOLUME_NAME}
Визуализация
Визуализация приходится, в основном, на Grafana
, это красиво и удобно. На примере одного тома выглядит примерно так:
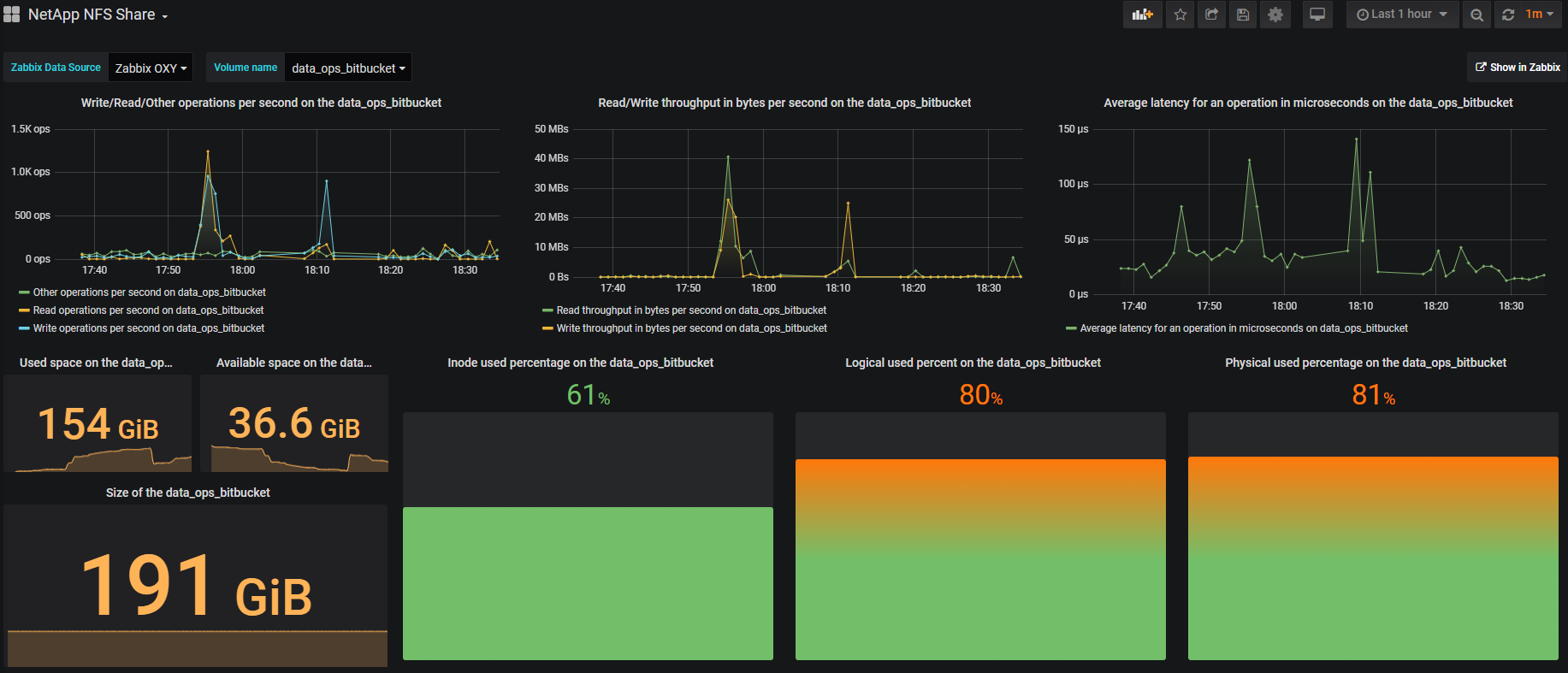
В правом верхнем углу есть кнопка Show in Zabbix
, с помощью которой можно провалиться в Zabbix и увидеть все метрики по выбранному тому.
My idea
- Use active way Agent monitoring
- Save an SSH log independently to avoid being recorded by hackers (of course, people deliberately find and erase can’t help!)
- Log monitoring with Zabbix
Create a SSH monitoring template
- Monitor

There are other three monitoring items, which are left in the learning process, and now only this Log monitoring is enabled.
- trigger
Shell file special plus Wellcome as keywords
SSH login automatic log log
I put it directly in the RC file under .ssh
$ cd ~/.ssh
$ cat rc
#!/bin/bash
LogFile=/var/log/zabbix-agent/ssh.log
# LogFile=/etc/zabbix/ssh.log
# echo $USER
# echo ${SSH_CLIENT%% *}
user=$USER
ip=${SSH_CLIENT%% *}
# echo Wellcome! User: $user , IP:$ip , Date:`date '+%Y-%m-%d %H:%M:%S'`
echo Wellcome! User: $user , IP:$ip , Date:`date '+%Y-%m-%d %H:%M:%S'` >>$LogFile Every time SSH login will be in /var/log/zabbix-agent/ssh.log record IP and other information
Test
Practice, I don’t know if there is any command line method to test, so I can only observe data in the web console.
Or a few more times, you can see the data

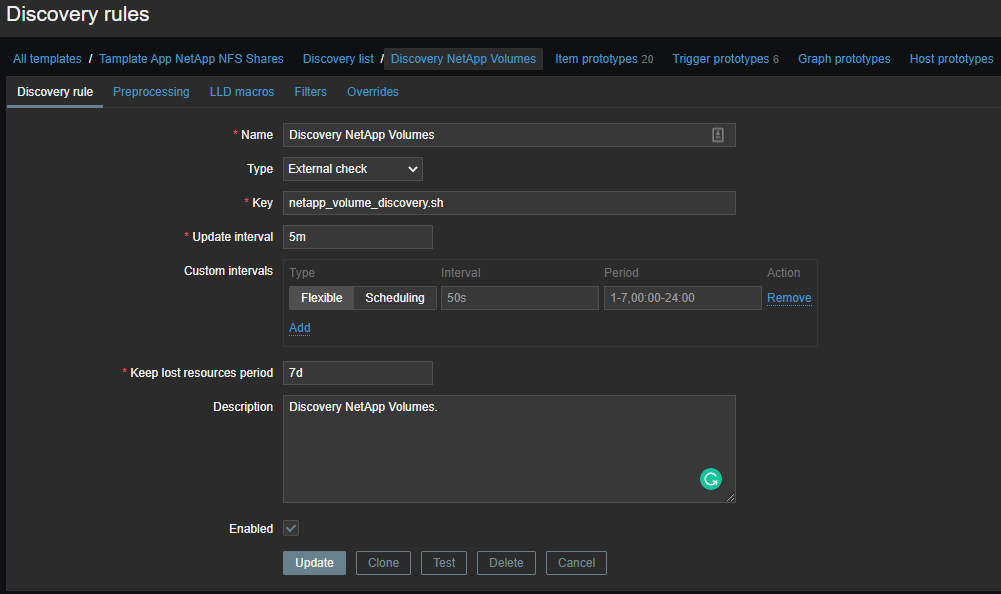
Низкоуровневое обнаружение (LLD)
Для начала нам необходимо создать низкоуровневое обнаружение (LLD)
, это будут названия наших томов. Всё это необходимо для того, чтобы вытащить конкретную информацию по нужному нам тому. Сырые данные выглядят примерно так (на момент написания их 114):
set -unit B; volume show -state online 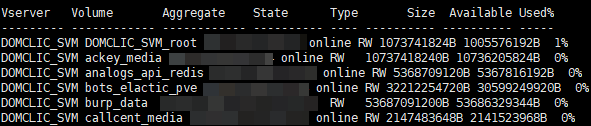
Ну как же без костылей: напишем однострочный bash-скрипт, который будет выводить названия томов в формате JSON (поскольку это внешняя проверка
, cкрипты лежат на Zabbix-сервере в директории /usr/lib/zabbix/externalscripts
):
#!/usr/bin/bash
SVM_NAME=""
SVM_ADDRESS=""
USERNAME=""
PASSWORD=""
for i in $(sshpass -p $PASSWORD ssh -o StrictHostKeyChecking=no $USERNAME@$SVM_ADDRESS 'set -unit B; volume show -state online' | grep $SVM_NAME | awk {'print $2'}); do echo '{"volume_name":"'$i'"}'; done | jq -s '. 
Теперь необходимо создать шаблон
и на основе полученных данных создавать элементы данных:
Элементы данных
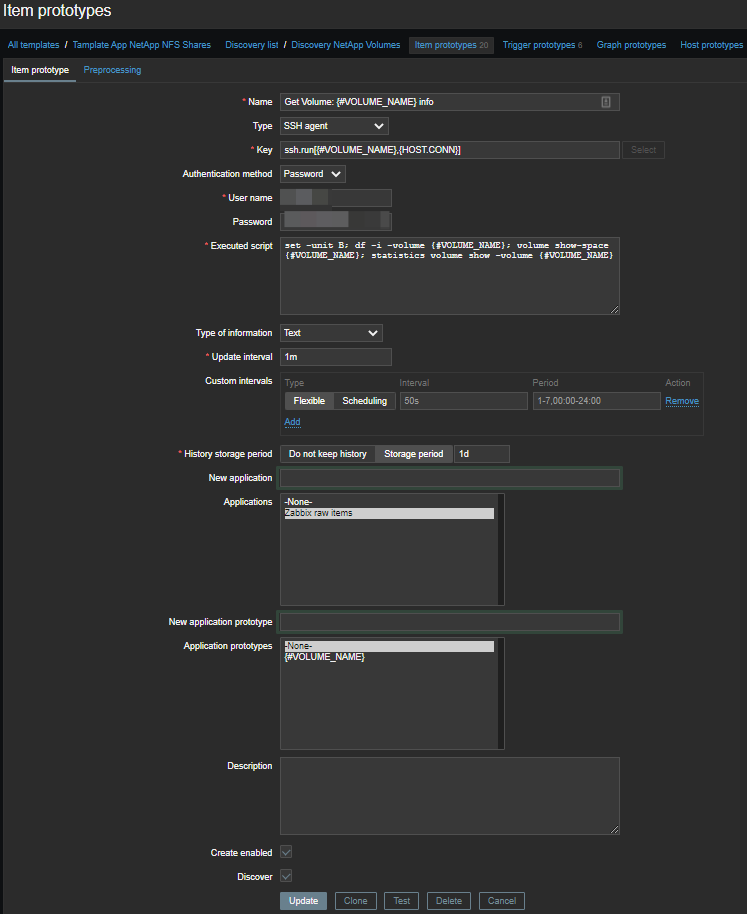
Для автоматического создания элементов данных необходимо сделать прототип элементов данных
:
Мы будем использовать мастер-элементы и несколько зависимых
от них элементов. Таким образом, для каждого тома создается один мастер-элемент, в котором выполняется набор команд по SSH:
set -unit B; df -i -volume {#VOLUME_NAME}; volume show-space {#VOLUME_NAME}; statistics volume show -volume {#VOLUME_NAME} Получаем вот такую простыню:
Get Volume: ackey_media info
Last login time: 9/15/2020 12:42:45
Filesystem iused ifree %iused Mounted on
/vol/ackey_media/ 96 311191 0% /ackey_media Volume Name: ackey_media Volume MSID: 2159592810 Volume DSID: 1317 Vserver UUID: 46a00e5d-c22d-11e8-b6ed-00a098d48e6d Aggregate Name: NGHF_FAS2720_04 Aggregate UUID: 7ec21b4d-b4db-4f84-85e2-130750f9f8c3 Hostname: FAS2720_04 User Data: 20480B User Data Percent: 0% Deduplication: - Deduplication Percent: - Temporary Deduplication: - Temporary Deduplication Percent: - Filesystem Metadata: 1150976B Filesystem Metadata Percent: 0% SnapMirror Metadata: - SnapMirror Metadata Percent: - Tape Backup Metadata: - Tape Backup Metadata Percent: - Quota Metadata: - Quota Metadata Percent: - Inodes: 12288B Inodes Percent: 0% Inodes Upgrade: - Inodes Upgrade Percent: - Snapshot Reserve: - Snapshot Reserve Percent: - Snapshot Reserve Unusable: -
Snapshot Reserve Unusable Percent: - Snapshot Spill: - Snapshot Spill Percent: - Performance Metadata: 28672B Performance Metadata Percent: 0% Total Used: 1212416B Total Used Percent: 0% Total Physical Used Size: 1212416B Physical Used Percentage: 0% Logical Used Size: 1212416B Logical Used Percent: 0% Logical Available: 10736205824B
DOMCLIC_SVM : 9/15/2020 12:42:51 *Total Read Write Other Read Write Latency Volume Vserver Ops Ops Ops Ops (Bps) (Bps) (us)
----------- ----------- ------ ---- ----- ----- ----- ----- -------
ackey_media DOMCLIC_SVM 0 0 0 0 0 0 0 Из этой простыни необходимо отобрать нужные нам метрики.
Итоги
- Автоматическая постановка томов на мониторинг.
- Автоматическое удаление томов из мониторинга, в случае удаление тома с NetApp.
- Избавились от привязки к одному серверу и ручному монтированию томов.
- Добавились метрики производительности по каждому тому. Теперь мы реже дергаем поддержку датацентра ради графиков с NetApp.
Скоро обещают обновить ONTAP и завезти расширенный API, шаблон переедет на HTTP-агент
.
