Автор ХостМастерНа чтение 20 минПросмотров86Опубликовано
// remove duplicates
var lookup = {};
var items = JSON.parse(value);
var result = [];
for (var item, i = 0; item = items[i++];) { var url = item.url; if (!(url in lookup)) { var row = {}; lookup[url] = 1; row["url"] = item.url; row["price"] = item.price; row["District"] = item.District; row["City"] = item.City; row["Street"] = item.Street; row["Rooms"] = item.Rooms; row["Area"] = item.Area; row["Floor"] = item.Floor; row["Series"] = item.Series; row["Type"] = item.Type; row["Facilities"] = item.Facilities; result.push(row); }
}
return JSON.stringify(result);
соответствуют реальным IP-адресам в файле hosts:
return value
.match(/^[^#]+/gm)
.sort().join("\n")
.match(/^[1-9]+.*$/gm)
.sort().join("\n")
.trim()
.replace(/^\s*[\r\n]/gm, '');
работа с запуском дополнительного сценария ключевого слова найдено
// look for keyword "pod" (including double quotes)
if (value.search("\"pod\"") > 0) {
// if pod has been found then execute extra JSONPath to find name
// Set the plain text to be a JSON object
var jsonData = JSON.parse(value);
// Count length of array. How many pods has been failed
lenghtOfArray=jsonData.length;
// Define an array to put inside all failed pods
var answerArray = [];
// Locate each pod and put inside answer Array
for(var pod = 0; pod < lenghtOfArray; pod++){
answerArray.push(jsonData[pod].metric.pod);
}
// Return all failed pods, and convert array to text with a comma as dividor
return answerArray.join(", ");
}
else {
// If "pod" was not found, then nothing happens
return 0
}
Сортировать строки по алфавиту:
var data='beta\nalpha\ndelta';
var array=data.match(/.*/gm);
return array.sort().join("\n");
var lld = [];
// this line is important to match all required patterns right away. Otherwise the upcoming code will fail.
var lines = value.match(/^.*:\d+.*\"[^\"]+\".*$/gm);
// go through all lines which match critera
var lines_num = lines.length;
for (i = 0; i < lines_num; i++)
{ var row = {}; row["port"] = lines[i].toString().match(/:([0-9]+)/)[1]; row["process"] = lines[i].toString().match(/\"([^\"]+)\"/)[1]; lld.push(row);
} return JSON.stringify(lld);
var arr1 = [ 1, 2, 3, 5 ];
var arr2 = [ 1, 4, 5, 6 ];
// merge, remove dublicates, sort
var arr3 = arr1.concat(arr2)
.reduce(function(a,b){if(a.indexOf(b) < 0)a.push(b);return a;},[])
.sort(function(a, b){return a - b});
return arr3;
Количество строк:
return value.split(/\r\n|\r|\n/).length;
Конкретные услуги для мониторинга:
var lines = '{$SERVICES_TO_MONITOR}'.split("|");
var lld = [];
var lines_num = lines.length;
for (i = 0; i < lines_num; i++)
{ var row = {}; row["{#NAME}"] = lines[i] lld.push(row);
}
return JSON.stringify(lld);
service1|service2
Отсортируйте массив чисел с плавающей запятой от большего к меньшему:
return value.match(/[0-9\.]+/gm).sort(function(a, b){return a - b}).reverse();
значение мод 180:
return value % 180
Встречаемость узора:
var temp = "Wel to come to W3Docs to asd";
return (temp.match(/to/g) || []).length;
Проверить и извлечь:
var lld = [];
if (value.match(/1 packets transmitted, 1 received/)) {
var lines = value
.match(/^.*1 packets transmitted, 1 received/gm)
.join("\n")
.replace(/^PING /gm,"")
.match(/^[0-9\.]+/gm);
var lines_num = lines.length;
for (i = 0; i < lines_num; i++)
{ var row = {}; row["{#IP.POS}"] = lines[i] lld.push(row);
}
return JSON.stringify(lld);
}
else
{
return JSON.stringify(lld);
}
Удалить начальные пробелы:
.replace(/^\s+/gm,'');
Удалить начальные и конечные пробелы:
.replace(/^\s+|\s+$/gm,'')
var string="kaste ta 13 da suns 66 iet"
var re=/\d+/g;
return string.match(re) ? re.exec(string) : 0;
Извлечь все числа:
return "This 13 this is another number 54 and third number 222".match(/\d+/g);
Определить наличие значения с помощью регулярного выражения
return value
.replace(/{#ID}/gm,'ID')
.replace(/{#NAME}/gm,'NAME')
.replace(/{#VALUE}/gm,'VALUE')
.replace(/{#CREATED_ON}/gm,'CREATED_ON')
.replace(/{#UPDATED_ON}/gm,'UPDATED_ON')
.replace(/{#ISDELETED}/gm,'ISDELETED');
Сортировка и целочисленный порядок:
return value.sort(function(a, b){return a - b});
return value.match(/[0-9]+/gm).sort(function(a, b){return a - b});
Удалить пустые строки:
return value.trim().replace(/^\s*[\r\n]/gm, '');
return value.split(/\r\n|\r|\n/).length;
Печатать новые порты из контекста:
var rownput_1 = [ { "value": "22,3306,5432,10051" }, { "value": "22,3000,3306,5432,10051" }, { "value": "22,3306,5432,10051" }, { "value": "22,3306,5432,10051" }
];
var rownput_2 = [ { "value": "22,3306,5432,10051" }, { "value": "22,3000,3306,5432,10051" }, { "value": "22,3306,5432,10051" }, { "value": "22,3306,5432,10050,10051" }
];
var array = JSON.parse(value);
var occurances = {};
// start two loops
// first loop starts. it will go through array elements (AKA rows)
var arraySize=array.length;
for (var row = 0; row < arraySize; row++) { // start working with one specific line in array var cur = array[row]; // count how many ports are in the line var countOfPorts=cur["value"].split(",").length; // start a loop to go through all ports for (var port = 0; port < countOfPorts; port++) { // select one specific port. put it in 'cur_num' variable var cur_num = cur["value"].split(",")[port]; // if the corresponding number does not have any value yet (for example when analyzing first line) occurances[cur_num] = (occurances[cur_num] == null ? 1 : occurances[cur_num] + 1); }
}
// Find the maximum value (the amount of occurances that non-odd one outs have)
var max = 0;
for (var key in occurances) { if (max < occurances[key]) { max = occurances[key]; }
}
var result = []; // Find all of the odd ones out
for (var key in occurances) { if (occurances[key] != max) { result.push(key); }
}
return result.join(',');
Обнаружение Transfor SNMP: JSONPath:
$.[*].["{#SNMPINDEX}"]
Предварительная обработка для преобразования SNMPINDEX, сотрите все справа:
// put the output from JSONPath result as an array of elements
var obj = JSON.parse(value);
// count the elements in input
var lines_num = obj.length;
// define new array
var lld = [];
// transform each element in array and put in new array
// .replace(/\..*$/gm,"") means we will erase any other character starting from first dot (.)
for (i = 0; i < lines_num; i++)
{ var row = {}; row["{#SNMPINDEX}"] = obj[i].replace(/\..*$/gm,""); lld.push(row);
}
return JSON.stringify(lld);
Диры и размеры:
var jsonData = JSON.parse(value);
// check each row and remove the data
for(var row = 0; row < jsonData.length - 1; row++){ // this will check the first condition. var pointer = 1; while(row + pointer < jsonData.length && jsonData[row].SIZE == jsonData[row + pointer].SIZE){ if( jsonData[row].DIR.startsWith(jsonData[row+1].DIR) ){ jsonData.splice(row + pointer, 1); } else { pointer++; } } // this will check the second condition. // for the second condition, it needs extra loop while the difference of size is smaller than 20480. pointer = 1; while(row + pointer < jsonData.length && jsonData[row].SIZE - jsonData[row + pointer].SIZE < 20480){ if (jsonData[row + pointer].DIR.startsWith(jsonData[row].DIR)) { // remove the current row and then reduce row because array items after row will be shifted jsonData.splice(row, 1); row--; break; } pointer ++; }
}
return JSON.stringify(jsonData.slice(0,10));
Суммируйте все целые числа внутри текста ‘111+222+333’:
var separeted = value.split("+");
var sum = 0;
for (var i = 0; i < separeted.length; i++) {
sum += parseInt(separeted[i].toString().match(/(\d+)/));
}
return sum;
$.body.data.result
var obj = JSON.parse(value);
return obj.length;
var lld = [];
var lines = value.match(/(http|https|ftp|ftps)\:\/\/[a-zA-Z0-9\-\.\/_?&=]+/gm).reduce(function(a,b){if(a.indexOf(b)< 0)a.push(b);return a;},[]);
var lines_num = lines.length;
for (i = 0; i < lines_num; i++)
{ var row = {}; row["{#URL}"] = lines[i] lld.push(row);
}
return JSON.stringify(lld);
Весь массив в нижнем регистре:
return JSON.parse(JSON.stringify(value, function(a, b) { return typeof b === "string" ? b.toLowerCase() : b }));
HEX в ASCII:
var out = "";
for (var i = 0, nums = value.split(" "); i < nums.length; i++) { out += String.fromCharCode(parseInt(nums[i], 16));
}
return out;
var obj = JSON.parse(value), result = obj.filter(function(e) { return e['{#' + 'TABLESPACE}'] == '{#TABLESPACE}'; });
return result[0]['{#' + 'TOTAL_MB}']
Замените переменные bash:
var lld = [];
// проверяем, есть ли ссылки вообще
if (value.match(/(http|https|ftp|ftps)\:\/\/[a-zA-Z0-9\-\.\/\$_?&=]+/gm)) {
// если есть ссылки, то извлечь и убедиться, что нет дубликатов:
var lines = value.match(/(http|https|ftp|ftps)\:\/\/[a-zA-Z0-9\-\.\/\$_?&=]+/gm).reduce (функция (a, b) {if (a.indexOf (b) < 0) a.push (b); return a;}, []);
вар число_строк = длина_строк;
для (я = 0; я < число_строк; я ++) {
переменная строка = {};
// патч для извлечения переменной (та, что со знаком доллара)
// если следующий ввод окажется каким-то кодом bash
если (lines[i].match(/\$[az]+/gm)) {
// извлечь полное название переменной и значение
переменная var = value.match(/([a-z]+)=([a-z0-9\.]+)/gm);
// сколько переменных в коде bash
var count_of_variables = переменная.длина;
// пройтись по всем переменным в коде bash
for (j = 0; j < count_of_variables; j++) {
var regexp = /([a-z]+)=([a-z0-9\.]+)/gm;
var unpack = regexp.exec (переменная [j]);
вар имя_переменной = '
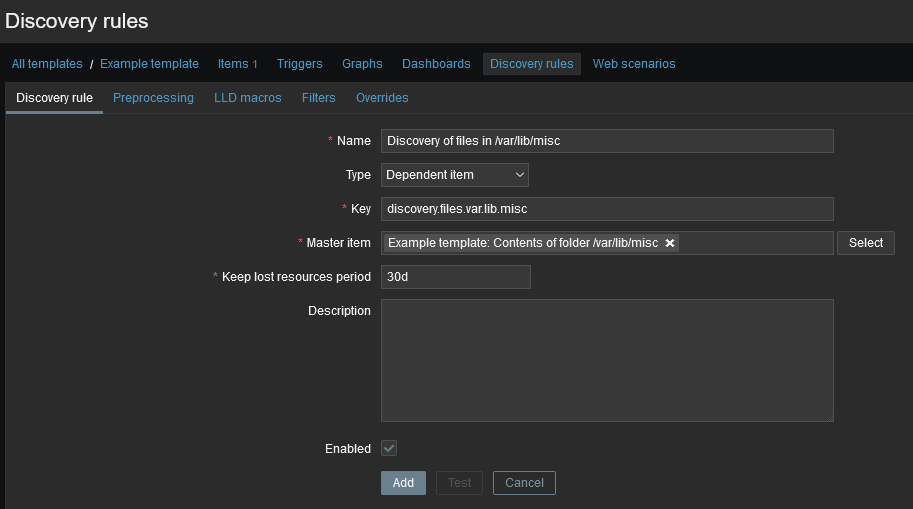
Имена файлов и метка времени последнего изменения находятся прямо там, и они уже структурированы как массив.
Давайте настроим правило обнаружения и сделаем его зависимым от этого элемента.
Мы близки к этому, но документ JSON еще не соответствует требованиям Zabbix для LLD.
В прошлом требовалось, чтобы документ JSON, используемый для LLD, имел родительский объект «данные». К счастью, это было изменено в Zabbix 4.2, и теперь любой массив JSON будет принят.
Чтобы обеспечить массовый сбор метрик и их одновременное использование в нескольких связанных элементах, Zabbix поддерживает зависимые элементы. Зависимые элементы зависят от основного элемента, который одновременно собирает их данные в одном запросе. Новое значение основного элемента автоматически заполняет значения зависимых элементов. Зависимые элементы не могут иметь другой интервал обновления, чем основной элемент.
Параметры предварительной обработки Zabbix можно использовать для извлечения части, необходимой для зависимого элемента, из данных основного элемента.
Предварительной обработкой управляет процесс менеджера предварительной обработки, который был добавлен в Zabbix 3.4 вместе с рабочими процессами, выполняющими шаги предварительной обработки. Все значения (с предварительной обработкой или без нее) из разных сборщиков данных перед добавлением в кэш истории проходят через менеджер предварительной обработки. Связь IPC на основе сокетов используется между сборщиками данных (поллерами, ловушками и т. д.) и процессом предварительной обработки.
Zabbix-сервер или Zabbix-прокси (если хост отслеживается прокси-сервером) выполняют этапы предварительной обработки и обрабатывают зависимые элементы.
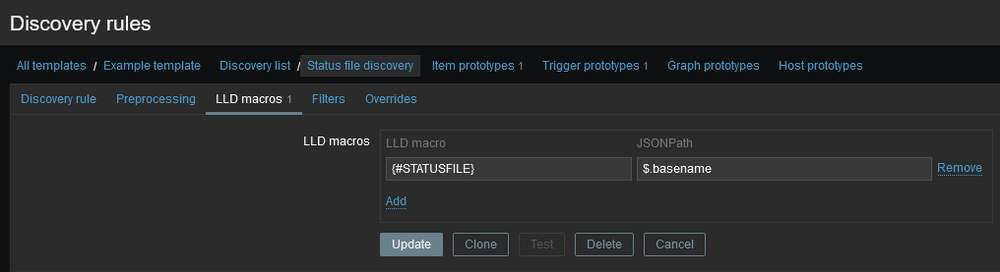
Элемент любого типа, даже зависимый элемент, может быть установлен в качестве главного элемента. Дополнительные уровни зависимых элементов могут использоваться для извлечения более мелких частей из значения существующего зависимого элемента.
Настроив 3 независимых элемента и настроив предварительную обработку JSONPath для каждого элемента, мы будем готовы к работе! Однако для каждого элемента мы будем опрашивать API, получать все 3 метрики, отбрасывать то, что нам не нужно, и сохранять только данные, актуальные для этого элемента. Какая трата!
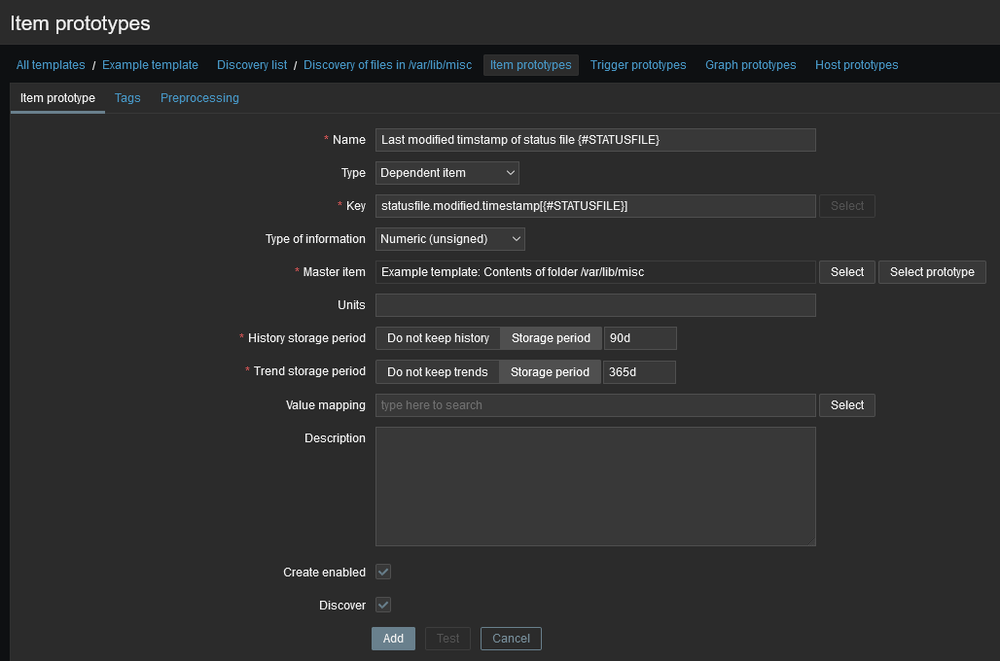
Вместо этого мы можем настроить один «Основной элемент», который получает данные из API. Сделав это, мы можем затем настроить дополнительные элементы и направить их к основному элементу. Когда основной элемент опрашивается и обновляется, то же самое происходит и со всеми зависимыми элементами! Используя предварительную обработку JSONPath для этих дополнительных элементов, мы можем проанализировать необходимую информацию для каждого из них. Например, для зависимого элемента «Температура в градусах Цельсия» мы добавим шаг предварительной обработки:
Как и любой другой предмет, вы можете добавить к ним дополнительные этапы предварительной обработки, если хотите.
Затем мы повторяем это также для метрик «temp_f» и «влажность». Теперь мы опрашиваем все 3 метрики одним вызовом API вместо 3!
С предварительной обработкой вы можете изменять, подгонять и корректировать входящие данные в любой желаемой форме. Это служит многим целям, например. ваши устройства могут не представлять данные в правильном формате или собирать пронумерованные показатели с точностью до десятичной точки.
Выдержка из zabbix.com о предварительной обработке элементов:
Предварительная обработка значений элементов данных позволяет определять и выполнять правила преобразования для полученных значений элементов.
Предварительной обработкой управляет процесс менеджера предварительной обработки, который был добавлен в Zabbix 3.4 вместе с рабочими предварительной обработки, которые выполняют шаги предварительной обработки. Все значения (с предварительной обработкой или без нее) из разных сборщиков данных перед добавлением в кэш истории проходят через менеджер предварительной обработки. Связь IPC на основе сокетов используется между сборщиками данных (поллерами, ловушками и т. д.) и процессом предварительной обработки. Либо сервер Zabbix, либо прокси-сервер Zabbix (для элементов, отслеживаемых прокси-сервером) выполняет этапы предварительной обработки.
При этом у вас есть возможность использовать, среди прочего:
Множители клиентов — данные, полученные в миллисекундах, можно умножить на 1000, а затем использовать единицу измерения «с», чтобы Zabbix представлял данные в удобочитаемом формате времени
JSON Path — копаться в структурах данных JSON, используя JSONPath чтобы получить и сохранить именно ту часть данных, которая вам нужна
Простое изменение или изменение в секунду — многие счетчики являются инкрементными, что позволяет Zabbix автоматически вычислять разницу между текущими и предыдущими собранными данными
Регулярное выражение — использование групп захвата искать и получать только те данные, которые вам нужны, даже с возможностью добавления или редактирования части данных
Преобразование – шестнадцатеричное, восьмеричное, логическое и десятичное, вы можете конвертировать числа любым способом
Возможно, вы измеряете данные о температуре и ваше устройство может выдавать вам шестнадцатеричную нечитаемую тарабарщину. Используйте предварительную обработку, чтобы легко преобразовать его в десятичное!
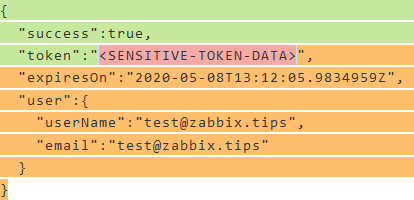
Например, вы можете наблюдать за JWT служба аутентификации. Вы хотите знать, правильно ли он работает и отвечает ли он действительным токеном. Используя элемент HTTP-агента, вы регулярно отправляете POST-запрос службе, и служба отвечает:
Давайте разберемся: шаблон разделен на 3 группы, каждая из которых начинается и заканчивается скобкой. Вот раскрашенное изображение групп: , и
В параметре Output мы просто используем только группы 1 и 3. Мы опускаем группу 2 и вместо нее пишем <redacted> . Результирующие данные, сохраняемые Zabbix:
Любые данные токенов, собранные Zabbix, теперь эффективно выбрасываются перед сохранением в базе данных.
Предварительная обработка предлагает множество других способов настройки и унификации ваших данных перед их сохранением в соответствии с вашими потребностями, поэкспериментируйте с этим!
+ распаковать[1]; var var_value = распаковать[2];
// делаем замену ссылки for (k = 0; k < (lines[i].match(/\$/g) || []).length; k++) { строки[i] = строки[i].replace(var_name,var_value); }
}
row["{#POST.URL}"] = lines[i];
} еще { row["{#POST.URL}"] = lines[i]; }
lld.push(строка); }
вернуть JSON.stringify(lld);
} еще { вернуть JSON.stringify(lld);
Имена файлов и отметка времени последнего изменения находятся прямо здесь, и они уже структурированы как массив.
Давайте настроим правило обнаружения и сделаем его зависимым от этого элемента.
Мы близки к этому, но документ JSON еще не соответствует требованиям Zabbix для LLD.
В прошлом требовалось, чтобы документ JSON, используемый для LLD, имел родительский объект «данные». К счастью, это было изменено в Zabbix 4.2, и теперь любой массив JSON будет принят.
Чтобы обеспечить массовый сбор метрик и их одновременное использование в нескольких связанных элементах, Zabbix поддерживает зависимые элементы. Зависимые элементы зависят от основного элемента, который одновременно собирает их данные в одном запросе. Новое значение основного элемента автоматически заполняет значения зависимых элементов. Зависимые элементы не могут иметь интервал обновления, отличный от интервала обновления основного элемента.
Параметры предварительной обработки Zabbix можно использовать для извлечения части, необходимой для зависимого элемента, из данных основного элемента.
Предварительной обработкой управляет процесс менеджера предварительной обработки, который был добавлен в Zabbix 3.4 вместе с рабочими процессами, выполняющими шаги предварительной обработки. Все значения (с предварительной обработкой или без нее) из разных сборщиков данных перед добавлением в кэш истории проходят через менеджер предварительной обработки. Связь IPC на основе сокетов используется между сборщиками данных (поллерами, ловушками и т. д.) и процессом предварительной обработки.
Сервер Zabbix или прокси-сервер Zabbix (если хост отслеживается с помощью прокси-сервера) выполняют шаги предварительной обработки и обрабатывают зависимые элементы. .
Элемент любого типа, даже зависимый, может быть установлен как основной. Дополнительные уровни зависимых элементов можно использовать для извлечения более мелких частей из значения существующего зависимого элемента.
Настроив 3 независимых элемента и настроив предварительную обработку JSONPath для каждого элемента, мы готовы к работе! Однако для каждого элемента мы будем опрашивать API, получать все 3 метрики, отбрасывать то, что нам не нужно, и сохранять только данные, актуальные для этого элемента. Какая трата!
Вместо этого мы можем настроить один «Основной элемент», который получает данные из API. Сделав это, мы можем затем настроить дополнительные элементы и направить их к основному элементу. Когда основной элемент опрашивается и обновляется, то же самое происходит и со всеми зависимыми элементами! Используя предварительную обработку JSONPath для этих дополнительных элементов, мы можем проанализировать необходимую информацию для каждого из них. Например, для зависимого элемента «Температура в градусах Цельсия» мы добавим этап предварительной обработки:
Как и любой другой элемент, вы можете добавить к ним дополнительные этапы предварительной обработки, если хотите.
Затем мы повторяем это для показателей temp_f и влажности. Теперь мы опрашиваем все 3 метрики одним вызовом API вместо 3!
С помощью предварительной обработки вы можете изменять, подгонять и корректировать входящие данные в любой желаемой форме. Это служит многим целям, например. ваши устройства могут не отображать данные в правильном формате или собирать нумерованные показатели с точностью до десятичной точки.
Выдержка из zabbix.com о предварительной обработке элемента:
Предварительная обработка значения элемента данных позволяет определять и выполнять правила преобразования для полученных значений элемента данных.
Предварительной обработкой управляет процесс менеджера предварительной обработки, который был добавлен в Zabbix 3.4, вместе с рабочими предварительной обработки, которые выполняют шаги предварительной обработки. Все значения (с предварительной обработкой или без нее) из разных сборщиков данных перед добавлением в кэш истории проходят через менеджер предварительной обработки. Связь IPC на основе сокетов используется между сборщиками данных (поллерами, ловушками и т. д.) и процессом предварительной обработки. Либо сервер Zabbix, либо прокси-сервер Zabbix (для элементов, отслеживаемых прокси-сервером) выполняет этапы предварительной обработки.
При этом у вас есть возможность использовать, среди прочего:
Множители клиентов — данные, полученные в миллисекундах, можно умножить на 1000, а затем с помощью единицы «s» Zabbix будет представлять данные в удобочитаемом формате
Путь JSON — копаться в данных JSON структуры с использованием JSONPath для захвата и сохранения именно той части данных, которая вам нужна
Простое изменение или изменение в секунду — многие счетчики инкрементный, и это позволяет Zabbix автоматически вычислять разницу между текущими и предыдущими собранными данными
Регулярное выражение — используйте группы захвата для поиска и захвата только тех данных, которые вам нужны, даже с возможностью добавления или редактирования частей данных
Преобразование — шестнадцатеричное, восьмеричное, логическое и десятичное, вы можете преобразовывать свои числа в любой куда
Возможно, вы измеряете данные о температуре, и ваше устройство может выдавать вам шестнадцатеричный нечитаемый бред. Используйте предварительную обработку, чтобы легко преобразовать его в десятичный формат!
Например, вы можете отслеживать службу аутентификации JWT. Вы хотите знать, правильно ли он работает и отвечает ли он действительным токеном. Используя элемент агента HTTP, вы регулярно отправляете запрос POST в службу, и служба отвечает:
Все данные токенов, собранные Zabbix, теперь эффективно удаляются перед сохранением в базе данных.
Предварительная обработка предлагает множество других способов настройки и унификации данных перед их сохранением в соответствии с вашими потребностями, поэкспериментируйте с этим!</p