

-
-
-
Локали и кодировки
- Локали и кодировки
- Введение
- Работа с локалями в PHP
- Локали в Windows
- Локали в UNIX
- Кодировки в MySQL
- Кодировка HTML-страниц
- Заключение
- Тестовая машина
- Устанавливаем MySQL 5
- Начало работы
- Вопросиков можно было избежать
- Настройка кодировок
- Вариант 1 — Через names
- Вариант 2 — Через непосредственно переменные character_set_*
- Вариант 3 — Через настройки самого сервера
- Что делать, если данные внесены в неправильной кодировке
- MySQL кодировки
- Как русифицировать MySQL?
Локали и кодировки
- Введение
- Работа с локалями в PHP
- Windows
- UNIX (FreeBSD)
- Кодировки в MySQL
- Кодировка HTML-страниц
- Заключение
Введение
При разработке веб-приложений есть три важных момента, связанных с кодировками: информация в файлах-сценариях, информация в базе данных и браузер пользователя. Если выставить хотя бы одну кодировку неверно, то, в лучшем случае, данные отобразятся неверно, в худшем, безвозвратно потеряются. Чтобы этого не произошло, а приложение работало корректно при любых настройках сервера, нужно правильно выставить кодировки.
Работа с локалями в PHP
Работа с локалями в PHP выглядит одинаково и в UNIX, и в Windows, и в любой другой платформе. Для установки значений локали служит всего одна функция setlocale(). Чтобы выставить локаль, нужно передать функции первым аргументом категорию, на которую эта локаль распространяется, последующими список возможных локалей. Результатом будет название первой подходящей локали, которая и была установлена.
Локали в Windows
Для того, чтобы узнать, какие локали доступны в Windows, нужно зайти в панель управления, «Язык и региональные стандарты».
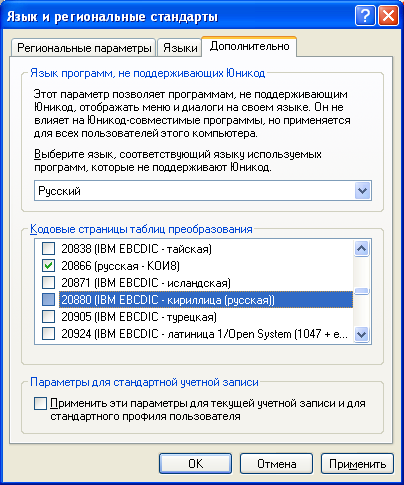
На вкладке «Дополнительно», в разделе «Кодовые страницы таблиц преобразования» показан список всех возможных локалей для Windows, которые можно использовать в PHP.
Кодовые страницы, которые отмечены в списке, из PHP могут быть использованы по их номеру.
В общем случае, использование выглядит по следующей схеме: Язык_Регион.Номер_кодовой_страницы
Для России это может выглядеть как Russian_Russia.1251 (cp1251) или Russian_Russia.20866 (KOI8-R).
Для Украины — Ukrainian_Ukraine.1251 (cp1251).
Вместо длинных названий можно использовать сокращённые russian, american, ukrainian и так далее. При этом кодовая страница выставится с учётом региональных настроек, для России и Украины — 1251, для Америки — 1252.
Единственная кодировка, с которой у меня возникли проблемы, как ни странно, оказалась UTF-8. При попытке выставить эту кодировку, выставляются все категории локалей, кроме основной. Вывод локализованных сообщений при этом идёт в cp1251.
Пока это можно списать на внутренний механизм PHP работы со строками. С шестой версии PHP вся обработка строк должна будет вестись в UTF-8, но до тех пор надо просто знать об этом и делать поправку.
Ещё одной странностью при работе с локалями в PHP на Windows является неправильная работа с категориями локалей. Так, например, я выставляю локаль на функции времени KOI8-R, setlocale(LC_TIME, 'Russian_Russia.20866'), но почему-то выставляется cp1251 на все категории. Суть проблемы я так и не понял, возможно, это просто баг (проверялось на PHP 5.2.3), а возможно, что внутренний механизм Windows просто не позволяет этого делать. Хотя по мне, так это чистой воды баг.
В общем-то, на этом можно и закончить разговор о локалях на Windows. Главное, запомнить, что локали, которые портированы из UNIX, под WIndows работают только для «галочки». Шаг влево, шаг вправо и результат будет непредсказуемым. Безопасно можно использовать только cp1251 (windows-1251) и KOI8-R, и только для LC_ALL.
Локали в UNIX
Выше я описал работу с локалями в Windows, теперь можно заострить внимание на UNIX-like системах. Для простоты, я буду их называть UNIX, а подразумевать FreeBSD :). В контексте данной статьи это не особо важно.
Итак, дистрибутивы UNIX поставляются в одном виде для всех, и работа рассчитана на многопользовательский режим, поэтому о правильной настройке локали должен заботиться сам пользователь, например:
= = = = = = = =.-
Так может выглядеть работа системной команды locale, которая выводит текущие настройки локали для пользователя. А так, обычно, выглядят настройки локали для пользователя, под которым работает PHP:
(); ================ = = = = = = = =
Функция ucwords() должна была сделать заглавными первые буквы всех слов. А перед этим strtolower() должна была предварительно все заглавные буквы сделать строчными. Но ничего не произошло. Так же не будет работать следующий код:
ucwords(strtolower()); ================ привет, МИР!
Хотя \w является множеством знаков, из которых может состоять слово (алфавит, цифры и _), регулярное выражение не срабатывает. Причина как раз в том, что, работая с cp1251, мы не сказали об этом php. Чтобы исправить положение, достаточно воспользоваться функцией setlocale() и указать правильную локаль, например, так:
setlocale(LC_ALL, );
Здесь первый аргумент — это категория, на которую будет распространяться локаль (константа LC_*), второй — название локали. Начиная с версии 4.3.0 можно указывать несколько имён локалей в виде массива или в качестве дополнительных аргументов. После вызова функция установит первую подходящую локаль и вернёт её имя:
setlocale(LC_ALL, , , ); ================ ru_RU.KOI8-R
С помощью команды grep я отобрал локали, которые поддерживают русский язык. Любую из них можно использовать, однако следует понимать, что данные должны быть в кодировке, на которую рассчитана локаль. Если же это правило не будет соблюдено, то результат может оказаться весьма неожиданным:
setlocale(LC_ALL, ), PHP_EOL; ucwords(strtolower()); =============== ru_RU.KOI8-R пРИВЕТ, мИР!
Если учесть, что koi8-r достаточно популярная кодировка для UNIX-севреров, а windows-1251 для русскоязычных сайтов, то подобное «необычное» поведение не такая уж и редкость. Когда-то я и сам столкнулся с этой проблемой при портировании проекта на реальный хостинг.
После установки правильной локали все примеры, которые не работали выше, будут работать как нужно!
setlocale(LC_ALL, , , ), PHP_EOL; ucwords(strtolower()), PHP_EOL; preg_match(, ) ? : , PHP_EOL; strftime('Сегодня: %A, %d %B, %Y года');
===============
ru_RU.CP1251
Привет, Мир!
нашёл
Сегодня: суббота, июля, годаПо-русски заговорит и функция strftime(), которая корректно работает с локалями, а также и всё остальное, что зависит от локали.
Кодировки в MySQL
Напомню, что возможность задавать кодировки появилась только в MySQL 4.1.11 и выше.
В отличие от php, проблемы с кодировками базы данных проявляют себя гораздо быстрее, чем проблемы с локалью. И связано это прежде всего с хранением и выборкой данных, поскольку от этого зависит информация на сайте. Я не буду подробно расписывать все тонкости, поскольку есть отдельная статья, остановлюсь на самых важных моментах.
Первое, чему необходимо научиться, смотреть текущие настройки соединения с mysql:
> ; + | | | + | | | | | | | | | | | | | | | | | | | | | | | ////// | + ( )
Критичными для пользователя являются character_set_client и character_set_results, которые отвечают за кодировку, в которой данные поступают в базу, и кодировку, в которой данные поступают из базы к пользователю. Если эти две кодировки отличаются от той, в которой работает клиент, в нашем случае php-скрипты, то неминуемо будут «странности», например, при сортировке выборки или внесении данных в базу.
Второе, что необходимо знать, как правильно сообщить mysql о кодировках. Самый простой и правильный способ, это использовать запрос set names:
> ; , ( )
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение cp1251. Это будет означать — клиент работает в кодировке windows-1251 (cp1251).
Помимо этого можно устанавливать непосредственно серверные переменные:
> =; , ( ) > ; + | | | + | | | | | | .....
Теперь данные поступают и извлекаются в разных кодировках.
Список доступных кодировок можно просмотреть так:
> ; + | | | | | + | | | | | | | | | | | | | | | | | - | | | | | | | | | | - | | | | | | | | | | | | | | | - | | | | | - | | | | | - | | | | | | | | | | - | | | | | - | | | | | - | | | | | | | | | | - | | | | | | | | | | | | | | | | | | | | - | | | | | | | | | | | | | | | | | | | | | | | | | | | | + ( )
И третье, что необходимо знать, — правила создания таблиц для хранения данных в нужной кодировке. К слову, данные можно хранить в любой кодировке, а работать с ними в кодировке клиента. Однако, важно понимать, что кодировки носят национальный характер и должны соответствовать вносимым данным. Иначе будут потери. Для русского языка есть три национальных кодировки koi8r, cp866, cp1251, которые могут конвертироваться друг в друга без потерь. Также можно использовать интернациональную кодировку UTF8.
Кодировку можно выставить на базу данных, таблицу и поле таблицы. Так, например, можно создать базу данных в кодировке koi8r:
CREATE DATABASE `test` DEFAULT CHARACTER SET koi8r;
Следует отметить, что кодировка базы данных влияет только на дефолтные значения кодировок при создании таблиц. Это значит, что неважно в какой кодировке была создана база, если кодировка таблицы была задана явно. Это же правило относится и к полям таблицы.
Следующим шагом я создам таблицу в cp1251 и одним полем в utf8:
( ( ) , , ( ) ) = ;
После того, как таблица создана с нужными параметрами кодировки, mysql автоматически начинает переводить данные при внесении и выборке.
> * ; + | | | + | | ! | + ( )
Данные хранятся в разном виде, но поступают к пользователю именно так, как надо!
Подробнее с кодировками и проблемами их использования можно ознакомиться на http://dev.mysql.com/doc/refman/5.1/en/charset.html.
Кодировка HTML-страниц
Объявить кодировку html-страницы можно двумя способами: через заголовки и мета-тег в самой странице. Мета-тег используется только в статичных страницах.
<meta http-equiv= content=>Я не буду его разбирать, это проблемы html. Во всех остальных случаях предпочтительней использовать HTTP-заголовок Content-Type.
PHP позволяет работать с HTTP-заголовками посредством функции header():
// Объявление типа содержимого и его кодировкиheader('Content-Type: text/html; charset=windows-1251');
Но браузер отобразит страницу корректно только в том случае, когда php-файлы сами были созданы в кодировке cp1251. Также нужно понимать, что заголовки должны быть отправлены до любого вывода на экран.
При необходимости перекодировать страницы «на лету», достаточно воспользоваться буферизацией и iconv:
Надпись «Привет, мир!» будет выведена в юникоде, при этом браузер получит информацию о кодировке через заголовки и правильно отобразит страницу. Но важно понимать, что внутри скрипта и при соединении с базой данных надо использовать windows-1251 (cp1251), поскольку страница должна быть сформирована в одной кодировке.
Важно помнить, что функции iconv доступны не всегда, и проверка на доступность этих функций не будет лишней.
Заключение
Для безопасной разработки русскоязычных веб-проектов необходимо включать в файл с общими настройками следующие команды:
Как ни странно, но эти три строчки кода значительно повышают портируемость веб-проектов.
Вольный перевод вопроса What’s the difference between utf8_general_ci and utf8_unicode_ci.
Обе эти кодировки (utf8_general_ci и utf8_unicode_ci) работают с символами UTF-8, разница в сортировке строк и их сравнении.
Заметьте: начиная с MySQL версии 5.5.3 предпочтительнее использовать
utf8mb4, а неutf8. Они обе являются кодировками UTF-8, но более
стараяuft8имеет специфические для MySQL ограничения символов UTF-8
выше 0xFFFD.
Сравнение по отдельным параметрам.
utf8mb4_unicode_ciоснована на стандарте Unicode по сортировке и
сравнению строк, который более точно сортирует строки в широком
диапазоне языков/алфавитов.utf8mb4_general_ciне реализует все правила сортировки Unicode, что
зачастую влечёт нежелательный результат в некоторых ситуациях для
определённых языков/символов.
utf8mb4_general_ciбыстрее в сравнении и сортировке, потому что она
содержит большое число оптимизаций.На современных серверах, это приращение скорости будет всегда, но незначительно. Оптимизации были задуманы во время, когда мощности серверов были значительно меньше сегодняшних.
utf8mb4_unicode_ci, которое использует правила Unicode для сортировки
и сравнения, по-честному использует более сложные алгоритмы для
точной сортировки для широкого числа языков и при использовании
спецсимволов. Эти правила принимают во внимание специфические
соглашения для языка, не всегда сортировки идёт в соответствии с
«алфавитным» порядком.
В принципе, для группы т.н. «европейских» языков нет особой разницы между строгой сортировкой по Unicode и упрощенной сортировкой utf8mb4_general_ci, но несколько различий:
Например, Unicode сортирует «ß» так же как и «ss», и «Œ» как «OE» так же как это делают люди, в то время как utf8mb4_general_ci сортирует их как отдельные символы (предположительно как «s» и «e» соответственно).
Некоторые символы Unicode определены как незначимые, что означает, что они не должны влиять на порядок сортировки и сравнение должно переходить к следующему символу. И utf8mb4_unicode_ci обрабатывает эти символы корректно.
Для группы неевропейских языков, таких как азиатские языки или языки с другим алфавитом существует гораздо больше различий между сортировкой Unicode и упрощённой сортировкой в utf8mb4_general_ci. То, насколько подходит utf8mb4_general_ci будет зависеть от конкретного языка. Для некоторых языков разница может быть сильно недостаточной.
Что же использовать?
Практически нет смысла предпочитать utf8mb4_general_ci по соображениям производительности, потому что на современных процессорах разница не будет играть роль «бутылочного горлышка».
Какая-то разница в производительности может быть в каких чрезмерно специализированных ситуациях и если это ваш случай вы должны знать об этом.
Раньше некоторые специалисты рекомендовали использовать utf8mb4_general_ci кроме тех случаев, когда необходима точная сортировка и это важнее проседания производительности. Сегодня больше обращают внимание на точную поддержку интернационализации, чем на незначительное проседание производительности.
И ещё я добавлю, что даже если ваше приложение должно поддерживать только английский язык — в нём может оказаться ситуация, когда в приложении будут вводиться имена людей и часто вводимые имена должны содержать символы, которые встречаются в других языках, поэтому так важно использовать корректные правила сортировки. Использование Unicode во всех местах, где это возможно, поможет вам разработать более качественные приложения.
-
-
-
Кодировки в MySQL
Тестовая машина
# uname -aFreeBSD dm -RELEASE FreeBSD -RELEASE
Fri May YEKST zgdm/usr/obj/usr/src/sys/GATE i386Устанавливаем MySQL 5
# pkg_add -r mysql51-serverFetching ftp//ftpfreebsdorg/pub/FreeBSD/ports/i386/ packages--release/Latest/mysql51-servertbz Done Fetching ftp//ftpfreebsdorg/pub/FreeBSD/ports/i386/ packages--release/All/mysql-client-tbz Done Added group Added user ************************************************************************ Remember to run mysql_upgrade with the optional --=dbdir flag the first you start the MySQL server after an upgrade from an earlier version ************************************************************************# /usr/local/etc/rc.d/mysql-server startStarting mysql mysql mysqld tcp4 * ** mysql mysqld stream /tmp/mysqlsock
Пускай это не самый «правильный» способ установки MySQL-сервера, зато быстрый и рабочий.
Начало работы
Итак, sockstat показала, что сервер работает, а установка говорит о том, что сервер абсолютно девственный. Чем это грозит? Кодировки по умолчанию выставлены англоязычные, а значит, будут проблемы при использовании кирилицы. Но как это распознать? Проверяем:
Welcome to the MySQL monitor Commands with or \g Your MySQL connection id is Server version -rc- FreeBSD port mysql-server- Type or help Type to clear the buffer mysql use Database changed mysql create table VARCHAR Query OK, rows affected sec mysql insert into values , , Query OK, rows affected sec Records Duplicates Warnings mysql
Первым делом используем тестовую базу, которая уже есть на сервере, затем создаём в ней таблицу и вставляем в неё три слова на русском, про кодировки мы пока ничего не знаем и знать не хотим ))).
Пока всё хорошо и радужно, никаких ошибок нет, пробуем сделать выборку:
> * ; + | | + | | | | | | + ( ) > * ; + | | + | | + ( )
> * ; + | | + | | | | | | + ( )
Расставляя точки над и, Character Set — транслируется как «кодировка», а Collation — сравнение. В чём разница? Сравнение — это правила сравнения букв кодировки. Сравнения работают только в рамках кодировки, и нельзя сравнивать данные в латинице по правилам кирилицы. Поясню на примере: мы, как увидим позже, внесли данные в таблицу на латинице, а сортировать нужно на кирилице, для чего можно использовать ключевое слово collate:
> * ; (): >
> ; + | | | | | | | + | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | + ( ) >
> ; + | | | + | | ( () ) = = | + ( )
> ; , ( ) : : :
> * ; ():
Хм.. опять та же ошибка, но откуда ей взяться?!..
> ; + | | | + | | ( () ) = = | + ( )
Ого, структура таблицы резко изменилась, теперь у неё задана одна кодировка, а у поля совсем другая.. :(( Порыв ещё мануал, можно изменить и кодировку столбца:
> () ; , , ( ) : : : > ; + | | | + | | ( () ) = = | + ( )
Ну вот!!! Злой кодировки latin1 нет и в помине, можно проверять наш роддом )))
> * ; + | | + | ???????? | | ????? | | ???? | + ( )
И вот тот страшный удар граблями, который так долго оттягивался! Внимательный читатель мог заметить, что когда была сделана попытка принудительно сменить кодировку столбца, содержащего данные в latin1, то на каждую запись, содержащую русские буквы, у MySQL был варнинг! Это был крик о том, что сервер не знает, каким образом можно перевести данные из latin1 в cp1251, ну и лучшего способа, чем заменить символы не latin1 вопросиками, он не нашёл :))). Роддом безвозвратно потерян потому, что теперь вместо кирилицы в базе содержатся вопросики..
Вопросиков можно было избежать
На самом деле, ситуация, когда изначально выставлена неправильная кодировка, встречается сплошь и рядом. Симптомы можно выявить следующим образом:
> ; + | | | + | | | | | | | | | | | | | | | | | | | | | | | ////// | + ( )
Именно эти переменные отвечают за дефолтные значения кодировок.
character_set_client— кодировка, в которой данные будут поступать от клиентаcharacter_set_connection— кодировка по умолчанию для всего, что в рамках соединения не имеет кодировкиcharacter_set_database— кодировка по умолчанию для базcharacter_set_filesystem— кодировка для работы с файловой системой (LOAD DATA INFILE, SELECT … INTO OUTFILE, и т.д.)character_set_results— кодировка, в которой будет выбран результатcharacter_set_server— кодировка, в которой работает серверcharacter_set_system— кодировка, в которой задаются идентификаторы MySQL, всегда UTF8character_sets_dir— папка с кодировками
ВАЖНО: Если character_sets_dir установлена неверно, то работа с кодировками будет под угрозой. Не пытайтесь менять её значение, если вы неуверены в своих силах. Если вы системный администратор, то перед установкой лучше ознакомиться с мануалом.
Наиболее значимые для простых пользователей следующие переменные: character_set_client, character_set_results, character_set_connection. Поскольку именно они отвечают за внесение, извлечение информации и создание таблиц/баз соответственно. Какими они могут быть?
> ; + | | | | | + | | | | | | | | | | | | | | | | | - | | | | | | | | | | - | | | | | | | | | | | | | | | - | | | | | - | | | | | - | | | | | | | | | | - | | | | | - | | | | | - | | | | | | | | | | - | | | | | | | | | | | | | | | | | | | | - | | | | | | | | | | | | | | | | | | | | | | | | | | | | + ( )
Любую из этих кодировок можно пользовать на свой вкус. Обычно русскоязычные пользователи предпочитают cp1251 или utf8, но по сути, неважно, в какой кодировке хранятся данные, важно, чтобы она была изначально правильно указана и данные были корректно внесены.
Настройка кодировок
Мануал предлагает нам три варианта задания кодировок:
ВНИМАНИЕ!!! Первые два варианта работают только в рамках текущего соединения. Это значит, что при следующем подключении все настройки вернутся в начальное состояние! Чтобы не выставлять кодировку каждый раз, нужно воспользоваться третьим вариантом.
Вариант 1 — Через names
> ; , ( ) > ; + | | | + | | | | | | | | | | | | | | | | | | | | | | | ////// | + ( )
Ну, тут всё ясно, три самые нужные кодировки в одном )))
Вариант 2 — Через непосредственно переменные character_set_*
> =; , ( ) > ; + | | | + | | | | | | | | | | | | | | | | | | | | | | | ////// | + ( )
Более детальная настройка, чем names.
Вариант 3 — Через настройки самого сервера
Тут можно пойти двумя путями — либо через конфиг файл:
---- Файл my.cnf[]# Для местного клиента--= .... []# Для всего сервера--= ....
>
Ещё можно при конфигурировании задать кодировку по умолчанию
> ./
Но лучше, когда кодировка настраивается прямо в соединении.
Что делать, если данные внесены в неправильной кодировке
Если база/таблица/данные были созданы/внесены в кодировке отличной от нужной, то необходимо сделать следующее:
- Создать бэкап базы данных
- Создать текстовый дамп базы в SQL-запросах (mysqldump или PhpMyAdmin)
- С помощью текстового редактора исправить вхождения неверной кодировки на нужную (а лучше попросту удалить всю информацию о кодировках и сравнениях)
- Удалить базу/таблицу
- Выставить нужную кодирвку на клиента/соединение
- Импортировать данные исправленного SQL-дампа
Этот вариант подходит почти для всех случаев, за исключением некоторых особых ситуаций, например, когда сравнение, выставленное по-умолчанию, не уместно для некоторых полей. Пример — поле для хранения пароля, необходимо сравнивать его с учётом регистра, тогда как по-умолчанию выставляется сравнение без учёта регистра.
> ; + | | | + | | | | | | | | | | | | | | | | | | | | | | | ////// | + ( )## Кодировки выставлены неверно, нужно их настроить> ; , ( ) > ; + | | | + | | | | | | | | | | | | | | | | | | | | | | | ////// | + ( )## Я работаю через koi8r, поэтому и выставляю её, ## но данные в таблице буду хранить в cp1251> ( ()) ; , ( )## Проверяем, всё ли в порядке> ; + | | | + | | ( () ) = = + ( )## Вносим данные > (), (),(), (), (); , ( ) : : : ## Проверяем сортировки## В обычном сравнении "И" и "и" одинаковы, поэтому ## сравнение идёт до первого отличного символа> * ; + | | + | | | | | | | | | | + ( )## В бинарном сравнении "И" меньше чем "и", поскольку у неё код меньше> * ; + | | + | | | | | | | | | | + ( )
Таким образом, клиент работает в KOI8-R, но данные хранятся в cp1251, MySQL знает об этом и делает перекодировку на лету.
Ну и на посошок:
> =; , ( ) > * ; + | | + | | | | | | | | | | + ( )
Выбирать данные можно в любой кодировке, так же, как и вносить, главное — правильно сообщить об этом MySQL.
MySQL кодировки
Проблемы с кодировками MySQL могут возникать для версий 4.1 и выше, поскольку для них введена возможность задания разной кодировки для разных уровней иерархии базы данных (сервер, база данных, таблица, столбец) и отдельно для соединения сервера с клиентом. По умолчанию MySQL имеет кодировку latin1 на всех уровнях.
Кодировка, в которой хранятся данные на сервере MySQL, должна совпадать с кодировкой самих данных. Например, для русских символов используется кодировка cp1251. Если в таблице будут храниться записи русскими буквами, то и кодировка этой таблицы должна быть задана cp1251, иначе отображаться будут не русские символы, а знаки вопроса или другие знаки.
При создании баз данных сразу указывайте кодировку для хранения символов, поскольку в случае отсутствия явно заданной кодировки будет использовано значение по умолчанию (latin1). Например, создавайте базу данных командой:
create database `my-db` default charset cp1251;
Кодировка соединения сервера с клиентом устанавливает, в каком виде будут передаваться данные между ними. Например, если в скрипте на сайте используются русские символы, то при обращении сайта к базе данных MySQL должен правильно распознать эти символы, чтобы корректно выполнить скрипт. Если кодировка соединения использует значение по умолчанию latin1, то русские символы сервер баз данных не сможет правильно распознать, следовательно, скрипт выполнится с ошибкой.
Установите нужную вам кодировку соединения сразу после подключения к серверу MySQL запросом:
set names cp1251
set init_connect="set names cp1251" где cp1251 – это нужная вам кодировка.
В этом случае сервер выполнит команду «set names cp1251» сразу после соединения с клиентом и установит указанную в запросе кодировку.
Самые распространенные в России кодировки следующие:
utf8, cp866 (DOS), cp1251 (Windows), koi8r
Установка и использование на всех уровнях сервера баз данных одинаковой кодировки устраняет 90% проблем с кодировкой в MySQL.
Как русифицировать MySQL?
Внесите следующие изменения в файл my.cnf:
[client] default-character-set=cp1251 [mysqld] character-set-server=cp1251 collation-server=cp1251_general_ci init-connect = "set names cp1251"
Перезапустите MySQL сервер.
Your answer is you can configure by MySql Settings. In My Answer may be something gone out of context but this is also know is help for you.
how to configure Character Set and Collation.
For applications that store data using the default MySQL character set
and collation (latin1, latin1_swedish_ci), no special configuration
should be needed. If applications require data storage using a
different character set or collation, you can configure character set
information several ways:
- Specify character settings per database. For example, applications
that use one database might requireutf8, whereas applications that
use another database might require sjis. - Specify character settings at server startup. This causes the server
to use the given settings for all applications that do not make other
arrangements. - Specify character settings at configuration time, if you build MySQL
from source. This causes the server to use the given settings for all
applications, without having to specify them at server startup.
Specify character settings per database
CREATE DATABASE new_db DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;Specify character settings at server startup
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ciSpecify character settings at MySQL configuration time
shell> cmake . -DDEFAULT_CHARSET=utf8 \ -DDEFAULT_COLLATION=utf8_general_ciTo see the values of the character set and collation system variables that apply to your connection, use these statements:
SHOW VARIABLES LIKE 'character_set%';
SHOW VARIABLES LIKE 'collation%';
-
Как изменить кодировку для всех таблиц в MySQL
Вы установили MySQL, создали таблицы и наполнили их данными, а в ответ отображается «абракадабра»? Дело в неправильно указанной кодировке. Для того чтобы данные отображались корректно, нужно изменить параметр кодировки для каждой таблицы.
В базе данных могут быть сотни таблиц, поэтому воспользуйтесь следующим решением для оперативной смены кодировок:
В столбце «Сравнение» отображается сопоставление кодировки базы данных:
Скопируйте запрос ниже:
SELECT CONCAT('ALTER TABLE `', t.`TABLE_SCHEMA`, '`.`', t.`TABLE_NAME`, '` CONVERT TO CHARACTER SET нужная_кодировка COLLATE сопоставление;') as sqlcode FROM `information_schema`.`TABLES` t WHERE 1 AND t.`TABLE_SCHEMA` = 'имя_базы' ORDER BY 1нужная_кодировка — кодировка, которую нужно применить;
сопоставление — сопоставление кодировки базы данных (шаг 2 — столбец «Сравнение»);
имя_базы — имя базы данных.
Вставьте запрос из шага 3 в окно запроса MySQL и выполните его, нажав Вперёд. В примере ниже мы сформировали список запросов для всех таблиц базы данных, который нужно выполнить, чтобы изменить кодировку на utf8 и на сопоставление кодировки utf8_general_ci.
В качестве ответа на запрос появится список запросов для смены кодировки каждой таблицы. Раскройте вкладку Параметры, установите чекбокс напротив пункта Полные тексты и нажмите Вперёд:
Вернитесь на вкладку SQL. Вставьте запросы в окно запроса MySQL и нажмите Вперёд:
Готово, вы успешно изменили кодировку во всех таблицах базы данных.
Спасибо за оценку!
Как мы можем улучшить статью?
Нужна помощь?
Напишите в службу поддержки!
For all the databases you have on the server:
mysql> SELECT SCHEMA_NAME 'database', default_character_set_name 'charset', DEFAULT_COLLATION_NAME 'collation' FROM information_schema.SCHEMATA;+----------------------------+---------+--------------------+
| database | charset | collation |
+----------------------------+---------+--------------------+
| information_schema | utf8 | utf8_general_ci |
| my_database | latin1 | latin1_swedish_ci |
...
+----------------------------+---------+--------------------+For a single Database:
mysql> USE my_database;
mysql> show variables like "character_set_database"; +----------------------------+---------+ | Variable_name | Value | +----------------------------+---------+ | character_set_database | latin1 | +----------------------------+---------+Getting the collation for Tables:
mysql> USE my_database;
mysql> SHOW TABLE STATUS WHERE NAME LIKE 'my_tablename';OR — will output the complete SQL for create table:
mysql> show create table my_tablename
Getting the collation of columns:
mysql> SHOW FULL COLUMNS FROM my_tablename;+---------+--------------+--------------------+ ....
| field | type | collation |
+---------+--------------+--------------------+ ....
| id | int(10) | (NULL) |
| key | varchar(255) | latin1_swedish_ci |
| value | varchar(255) | latin1_swedish_ci |
+---------+--------------+--------------------+ ....